Multimodal RAG Patterns Every AI Developer Should Know
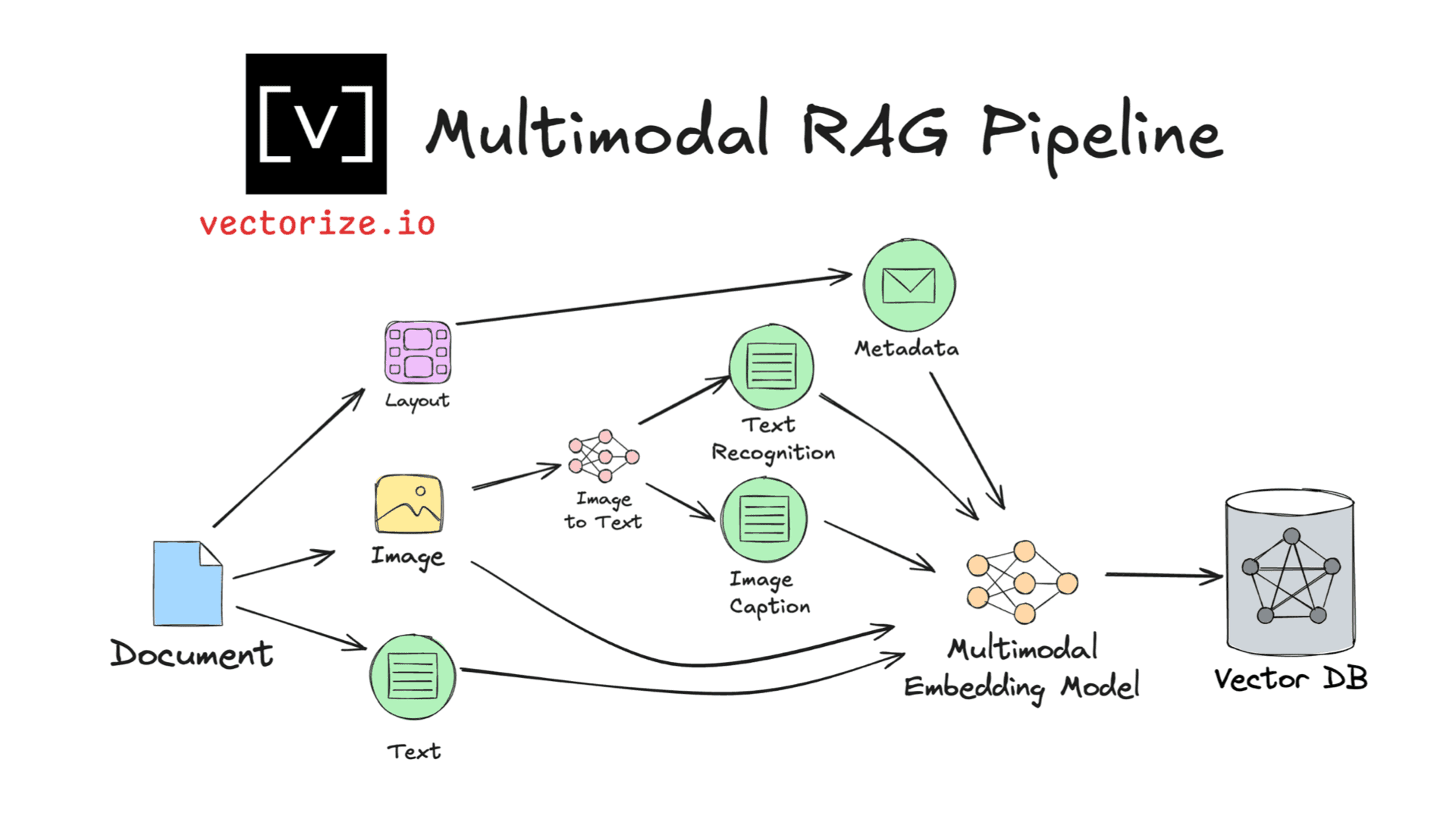
It’s been nearly a year since my co-founder and I decided to quit our jobs and start Vectorize. It’s by far the best job I’ve ever had. One big reason for that is because almost every day I get to talk with smart people who are working on interesting projects. We get to figure out how to build new applications using large language models (LLMs). Recently, a lot of these applications have involved using multimodal retrieval augmented generation (RAG).
As we’ve been working with these customers, I find we’re using the same design patterns over and over again. In this post, I’ll go into depth on the three most common multimodal patterns we see. I’ll give you a flowchart and concrete guidance so you know when to use each one. And I won’t use any framework-specific techniques; you can apply these patterns regardless of your choice of LLM framework (or lack thereof).
Types of multimodal RAG systems
Multimodal retrieval augmented generation is a lot like regular retrieval augmented generation, except that you are dealing with multiple types of data. This includes things like audio, video, and code. But by far the two most common modalities you’re likely to encounter are text and images.
Fortunately, the patterns that we will look at are agnostic of the specific data types you’re working with. Because they are so common, the examples I’ll use are going to heavily skew towards text and images and things that fall in between like tables and charts that are contained inside documents.
Systems that need information about multimodal data
Depending on the type of system you’re building, you may or may not need direct access to multimodal data types like images. For instance, let’s look at this multimodal RAG system focused on real estate listings. Instead of having real estate agents spend time writing descriptions of a property and manually entering data attributes about the listing, the system would look at a set of photos of a property and generate the information needed for a listing.
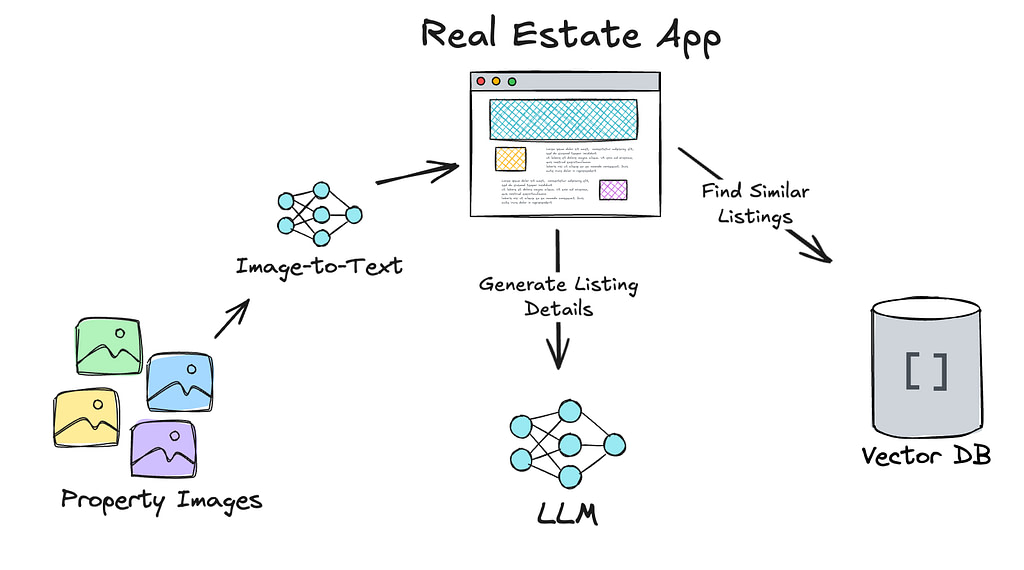
In this case, the developer had built a search index of real estate listings. They were generating a text description of images using a model on Google Vertex.
They were then retrieving similar listings that the agency had published from their vector database. They passed the listing information, along with the images, to a multimodal LLM to generate a listing based on the images and past listings.
In several other projects, we were working with images that were created by scanning paper documents. In these cases, we needed to use OCR to extract the useful text from the image, but no longer needed the raw image beyond that.
Systems that need access to multimodal data
Sometimes, having access to the raw images is important, like in this application which was built to provide an AI assistant for field technicians in an appliance repair company.
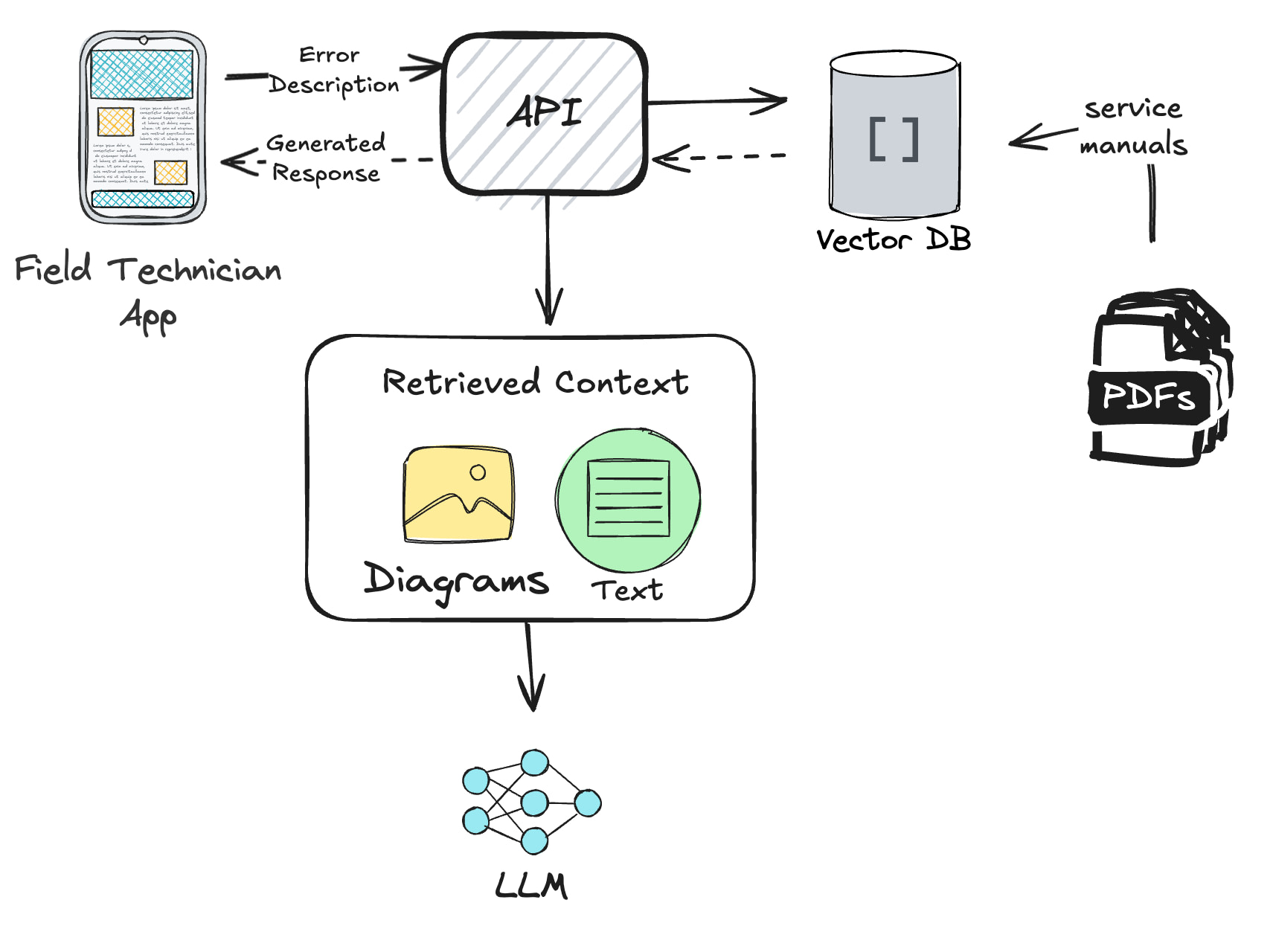
The PDF manuals contained diagrams showing the internal workings of appliances along with instructions for performing repairs and diagnostics. In this case, serving both text and the actual image to the application was necessary to assist the technician and provide the most relevant information.
When building a multimodal RAG system, the retrieval patterns for your non-text data will drive major design decisions in your architecture.
Multimodal RAG Design Patterns
Just like any software development project, the more we can leverage established design patterns, the faster we can deliver high quality software. Multimodal AI applications are no different. Let’s start by looking at the simplest pattern we can use.
Pattern 1: Embedding text descriptions of non-text data types
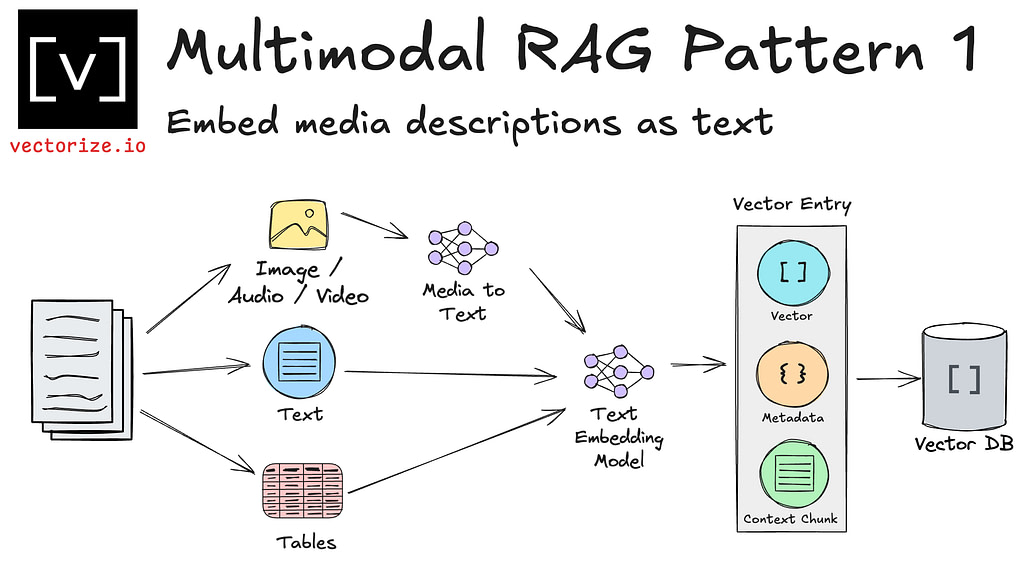
For cases where you don’t require direct multimodal retrieval in your application, you can often rely on text-to-image or a multimodal LLM to describe the contents of your multimodal data.
Once you have the textual representation, you can load it into your vector database just like you would pure text data. Standard text embedding models will generate vector representations, and you can use kNN queries to find the most similar context using cosine similarity or another similarity metric.
Pattern 2: Multimodal embeddings and media storage in your vector database
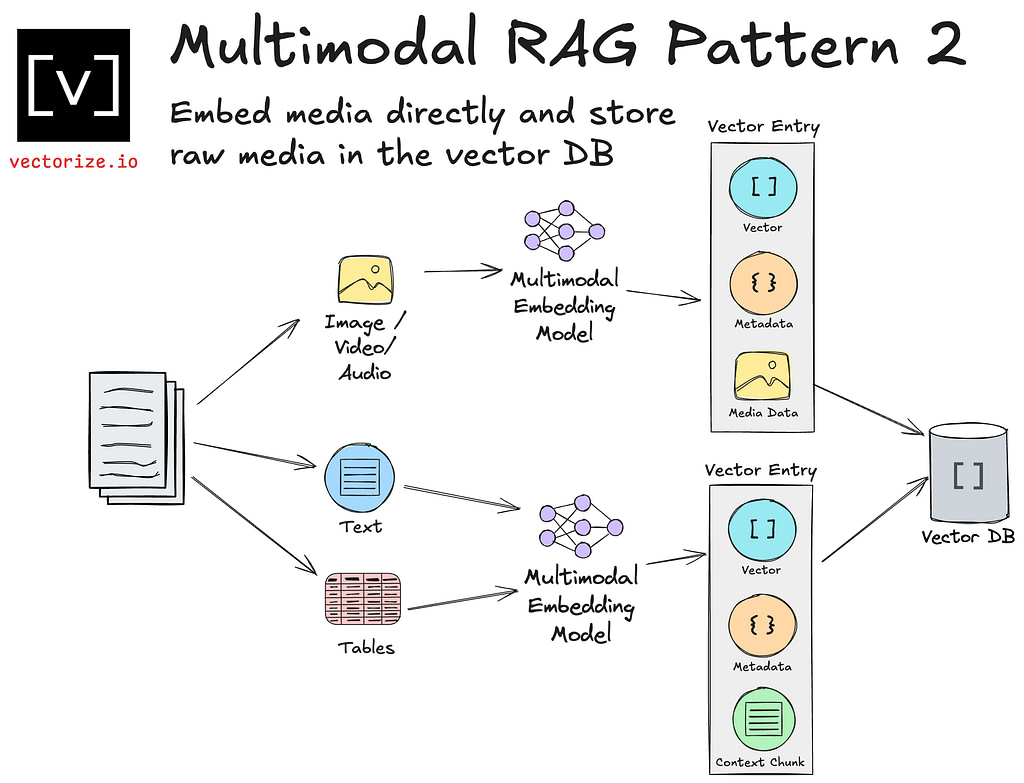
With this we can use a multimodal embedding model to generate a vector representation of our non-text data directly. For example, models like Amazon Titan will take JPG or PNG images and generate embeddings in the same semantic vector space as text.
Depending on your database, storing media like images in your database may or may not be a recommended pattern. Relational databases which support binary data types such as BLOBs can suitable for image storage in simple use cases.
As your requirements scale to include high volumes of multimodal data, the prospect of scaling your persistence engine to support file storage is likely a poor tradeoff. Likewise, as your requirements require scaling the number of users, fetching images can become a bottleneck.
In these situations, you may want to consider our next pattern.
Pattern 3: Text embeddings with a raw media pointer stored as metadata
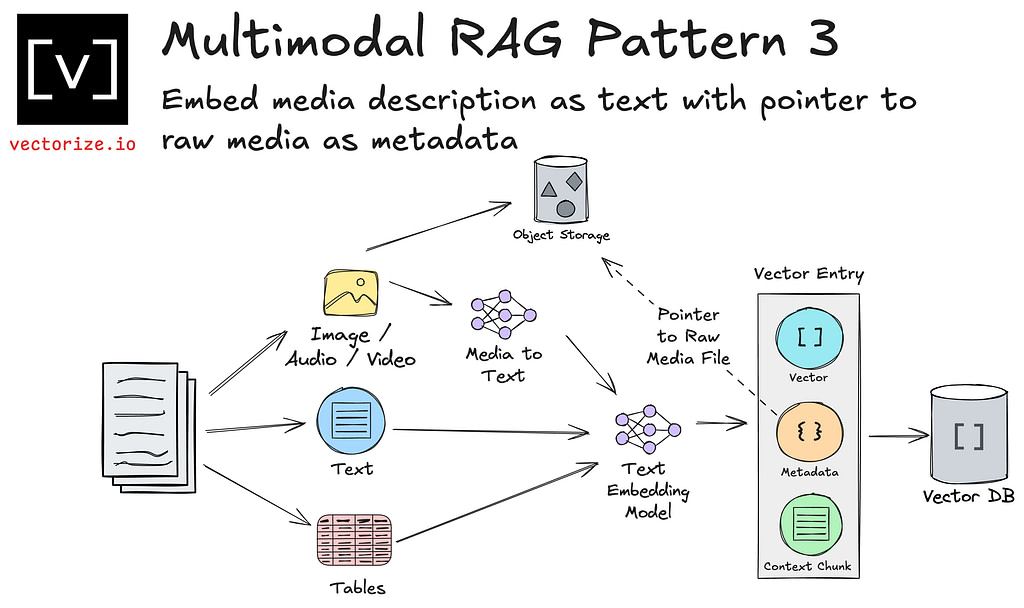
If you want to avoid direct object storage in your vector database, you can instead host your images or other media in object storage. This gives you an inexpensive way of scaling your media independently of your vector database.
For situations where your users are globally distributed and you need to serve images or other media in your application, a CDN can be another good option.
When you submit your prompt to the LLM, you can then include the URL of the relevant media. If your LLM is producing a result such as HTML or Markdown, it can include image tags or other embedded media in its response.
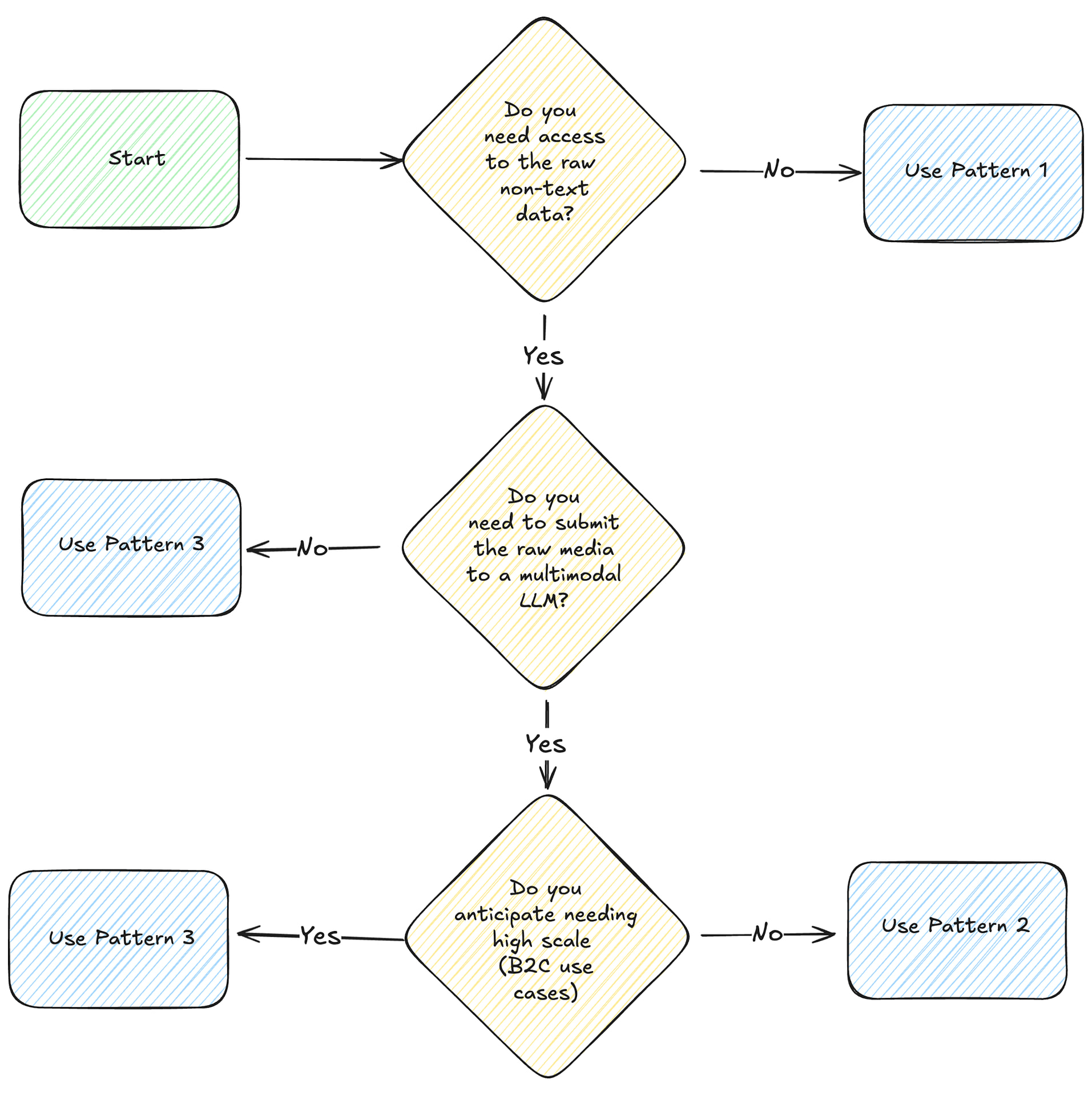
When to use each pattern?
Ultimately, you need to look at the options and decide based on your requirements which approach is going to give you the right tradeoffs in terms of complexity, scale, and capabilities. As a starting point, this flowchart can give you an idea of when each pattern is most suitable.
Metadata extraction with multimodal data
Multimodal data is often spread across multiple modalities, such as images, text, and audio. Each one of these data types has metadata that can prove useful inside of a retrieval augmented generation system.
Some of this metadata is easily extracted. File names and last updated timestamps are data elements that are readily available. More sophisticated metadata will require additional preprocessing to extract.
Let’s take an example from a use case I was recently working on. We had a PDF of building codes that contained both images and text. Most of the images were illustrations, each illustration was numbered, and each image had a description.
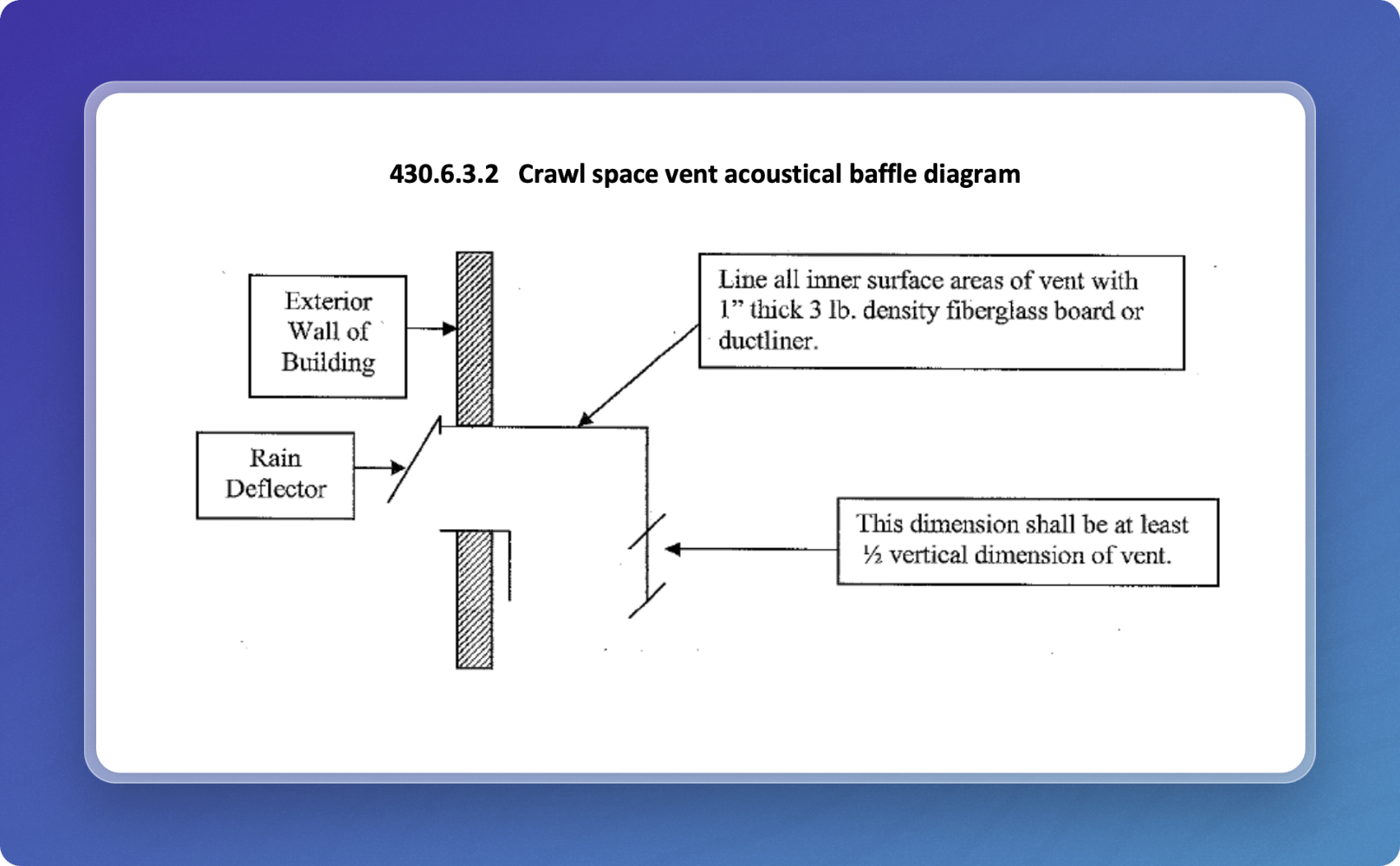
Our image-to-text model for this image gives us a description of:
The diagram shows the construction of an acoustical baffle for a crawl space vent. It includes a vertical wall labeled as the 'Exterior Wall of Building.' A rain deflector is placed at the top of the vent opening to prevent water entry. The inner surfaces of the vent are lined with a 1-inch thick, 3 lb. density fiberglass board or duct liner for sound insulation. Additionally, a dimensioning note indicates that a key dimension of the baffle should be at least half the vertical dimension of the vent.This is what we would actually send to the text embedding model to generate our vector.
When we perform our retrieval, we would retrieve this chunk. We would also like to retrieve metadata to allow the LLM to contextualize these images and better understand how to “think” about them. For this, we need to identify a metadata model.
In the case of the building codes, we may be working with hundreds of documents that span cities and counties or even countries. We want a metadata model that is simple and generic enough to work across all of them. For images, we could represent the data as a JSON schema like this:
{
"$schema": "http://json-schema.org/draft-07/schema#",
"type": "object",
"properties": {
"chunk": {
"type": "string",
"description": "The text description of the image"
},
"documentTitle": {
"type": "string",
"description": "Title of the document from which the image is extracted."
},
"jurisdiction": {
"type": "string",
"description": "City, state, or governing body responsible for the building code."
},
"sectionTitle": {
"type": "string",
"description": "The section or chapter where the image is located."
},
"imageCaption": {
"type": "string",
"description": "A short caption or title for the image."
},
"pageNumber": {
"type": "integer",
"description": "The page number in the document."
},
"fileSource": {
"type": "string",
"description": "The original file name or identifier from which the image was extracted."
},
"imageFormat": {
"type": "string",
"description": "The format of the extracted image (e.g., PNG, JPEG)."
},
"resolution": {
"type": "string",
"description": "The resolution of the image (optional)."
},
"documentType": {
"type": "string",
"description": "The type of document (e.g., Building Code, Fire Code, Zoning Ordinance)."
}
},
}When we insert our extracted image into our vector database, the accompanying metadata would then look something like:
{
"chunk": "The diagram shows the construction of an acoustical baffle for a crawl space vent. It includes a vertical wall labeled as the 'Exterior Wall of Building.' A rain deflector is placed at the top of the vent opening to prevent water entry. The inner surfaces of the vent are lined with a 1-inch thick, 3 lb. density fiberglass board or duct liner for sound insulation. Additionally, a dimensioning note indicates that a key dimension of the baffle should be at least half the vertical dimension of the vent.",
"documentTitle": "2022 Denver Building and Fire Code",
"jurisdiction": "Denver, CO",
"sectionTitle": "430.6.3.2 Crawl Space Vent Acoustical Baffle Diagram",
"imageCaption": "Crawl space vent acoustical baffle diagram",
"pageNumber": 124,
"dateExtracted": "2024-10-26",
"fileSource": "2022-denver-building-and-fire-code.pdf",
"imageFormat": "PNG",
"resolution": "768x1241",
"documentType": "Building Code"
}Representing metadata across different modalities allows you to provide more rich context to the LLM and will impact the overall quality of the results you get from your multimodal RAG application.
Multimodal Retrieval Techniques
Using multimodal models or converting multiple modalities to text are two techniques you can use to embed all modalities into the same vector space. If you want to simplify your RAG architecture, having a unified vector space is key.
However, this brings up a few implementation questions touched on in the design patterns above. Let’s look at two cases in particular.
Rendering images back to your user
Rendering images from your LLM output is a very common requirement. You may want the LLM to return HTML or markdown that you’ll render client side.
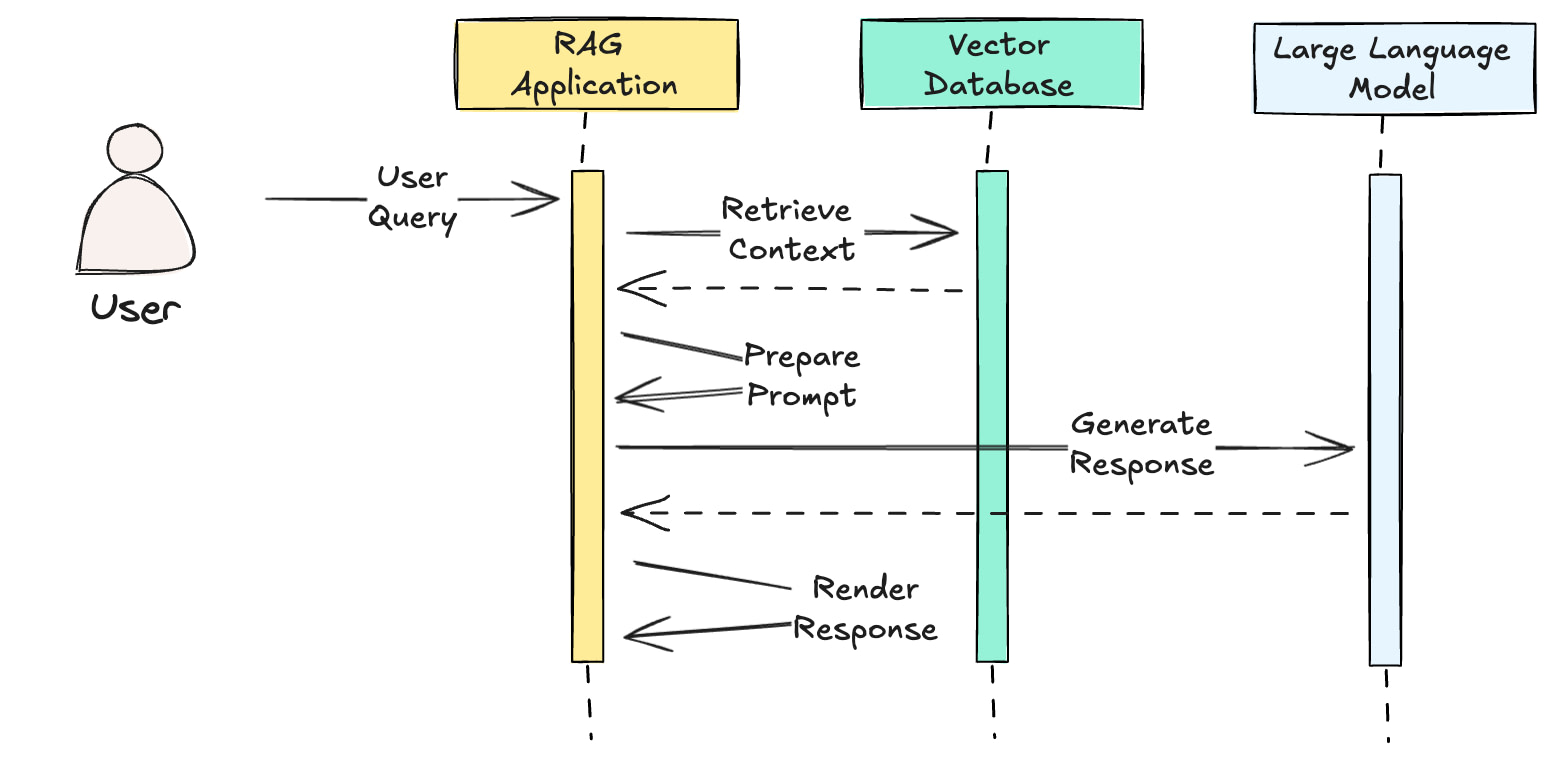
We can support this requirement with both patterns 2 and 3 above. However, pattern 2 will have a few significant drawbacks:
Persisting raw images in your vector database will result in larger responses and add latency to your vector query retrieval time.
You’ll need to include raw image bytes in your response back to the browser to render the images.
You’ll either burn through tokens having the LLM generate image tags with encoded image bytes, or you’ll need some mechanism to post-process the LLM’s output to inject the image into the rendered response sent back to the client.
As you’ll see coming up, with pattern 3, we would build our RAG pipeline to include a URL for each image in our metadata model. This creates a simplified approach in the RAG application that feels familiar to anyone who has ever built a web application; we’re just using vanilla image tags and URLs.
Providing images as input to multimodal models
Sometimes you’ll encounter requirements to generate images. In these situations, passing raw images into a multimodal model can help achieve the visual characteristics you want. Compared with image captioning, this approach give the model additional context to help it produce similar concepts better than textual representations alone. That’s because multimodal models have been pretrained with techniques such as contrastive representation learning to solve this specific set of problems.
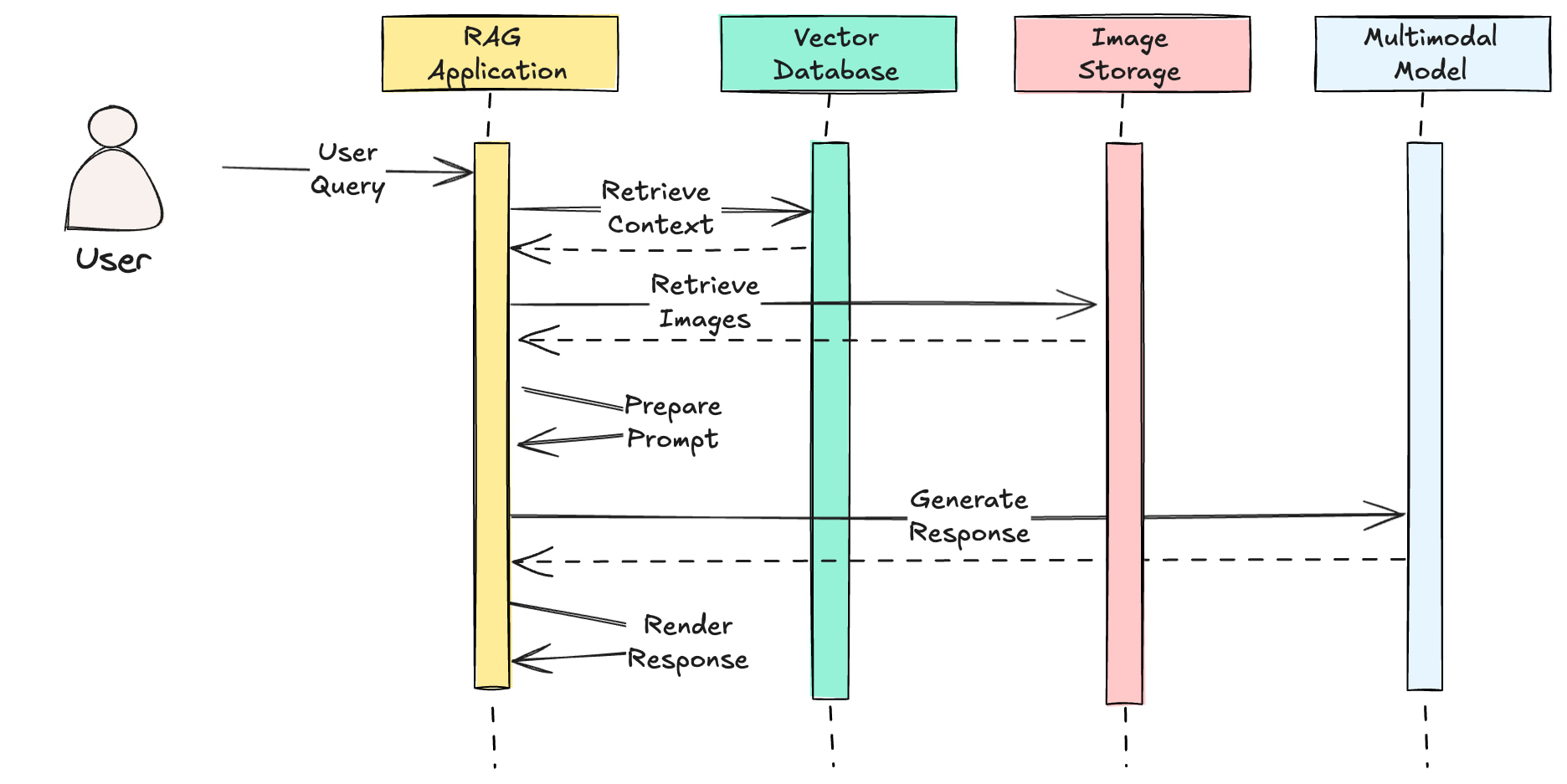
Either pattern 2 or pattern 3 above can support these use cases. Pattern two has the benefit that you can get the context and the retrieved image in one step instead of two. If your image is stored as metadata in your vector database, you can execute a single query and get back everything you need to prepare your prompt to the model.
This still carries all the tradeoffs we touched on earlier, but you simplify your data architecture and avoid additional points of failure that you have to consider when building your multimodal RAG application.
Building a Multimodal RAG Pipeline
The data sources you’re working with will impact the complexity of your RAG pipeline. The trickiest pipelines tend to be the ones where you need to separate different modalities of data from a single source. For example, documents that contain both text and images.
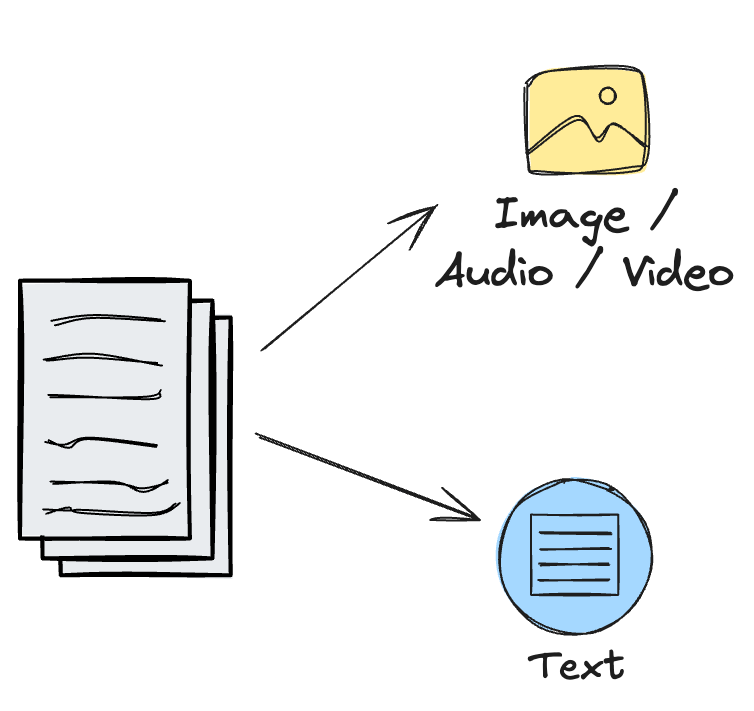
For cases where different data types are already extracted, the pipeline process becomes simpler since you can rely on a multimodal embedding model to generate vectors for each data type without mapping them into different vector spaces. Your preprocessing becomes a lot simpler.
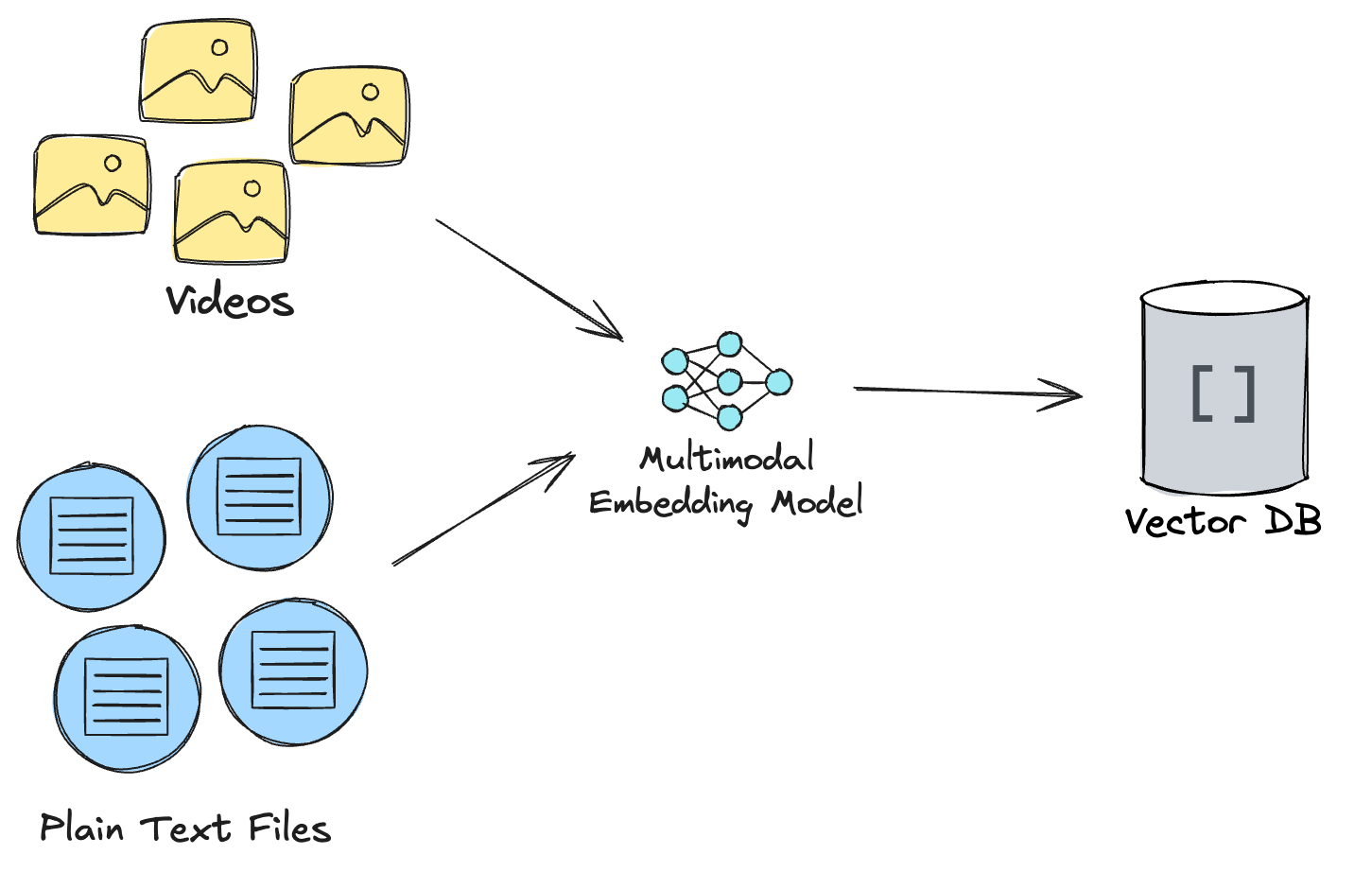
We’ll look at the more complex case here since it’s a more interesting problem and how to solve it is less obvious.
Preprocessing Multimodal Data
Just like any RAG pipeline, we need to source our data and address preprocessing tasks like extraction, data cleansing, chunking, and embeddings.
Layouts are more important with multimodal data
So far we’ve talked mostly about text and images. However, another common requirement you’ll encounter when working with documents is tabular data.
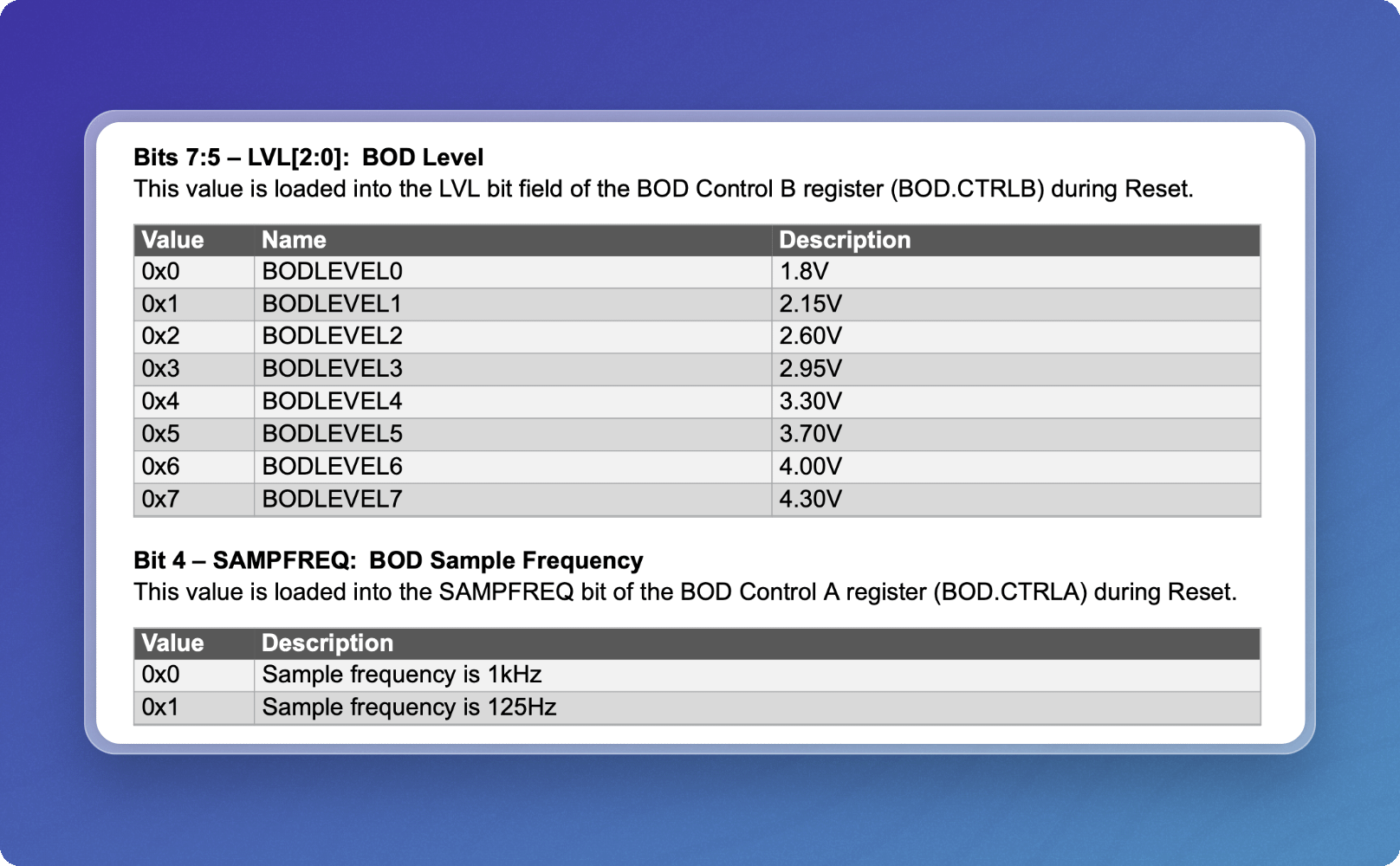
If we use the basic/fast parser in Vectorize to extract and chunk this table, we’ll get a reasonable text representation, but we’ll miss important context that tells us more about the data contained in this table and when to use it.
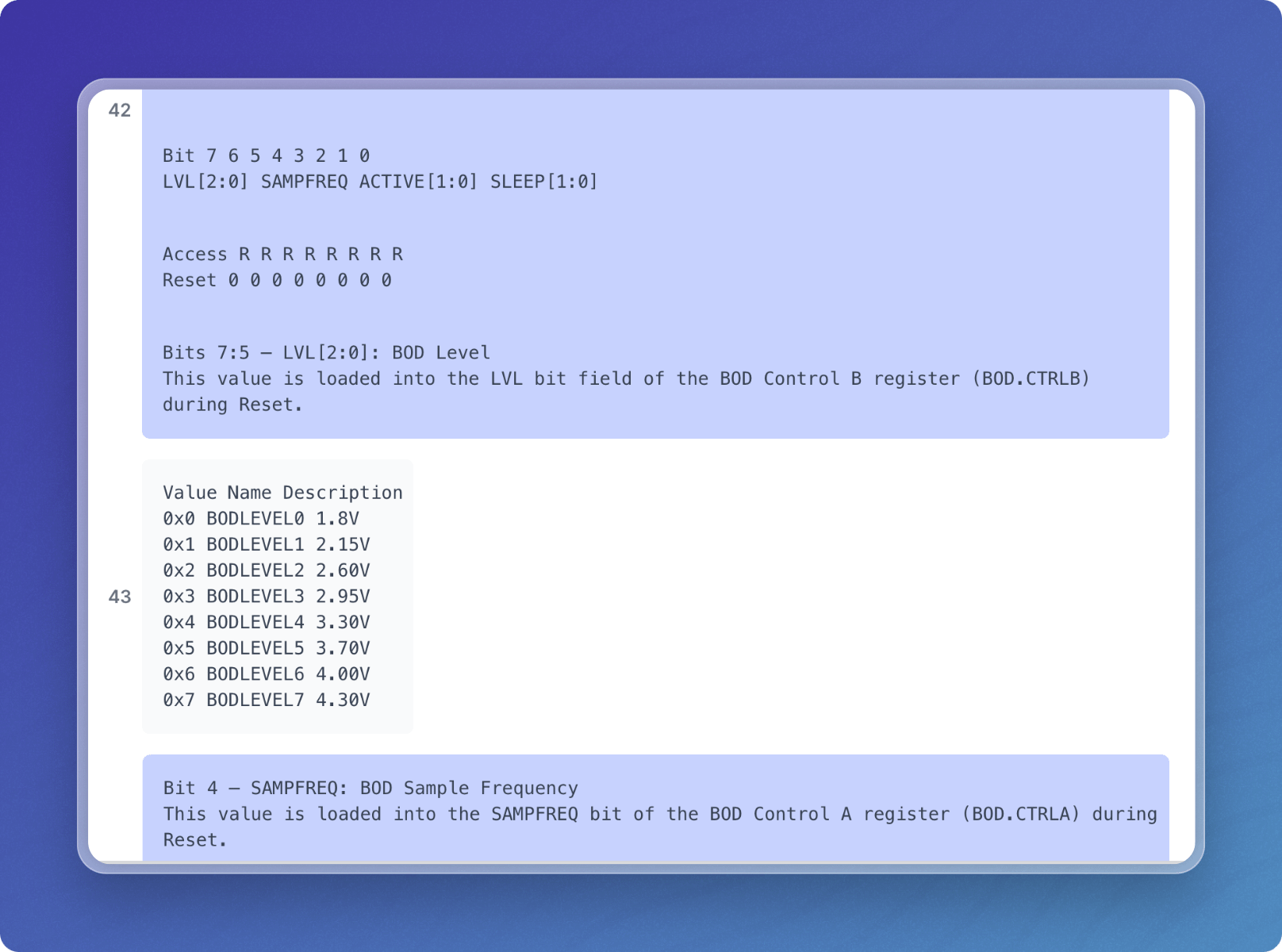
However, using the advanced extractor which leverages a finely tuned, layout aware model, we can see that our chunking does a better job taking into account the surrounding context. Model-based extraction can use natural language processing techniques to provide semantic chunking and capture related data inside your chunks.
Aligning your RAG pipeline with your multimodal RAG design pattern
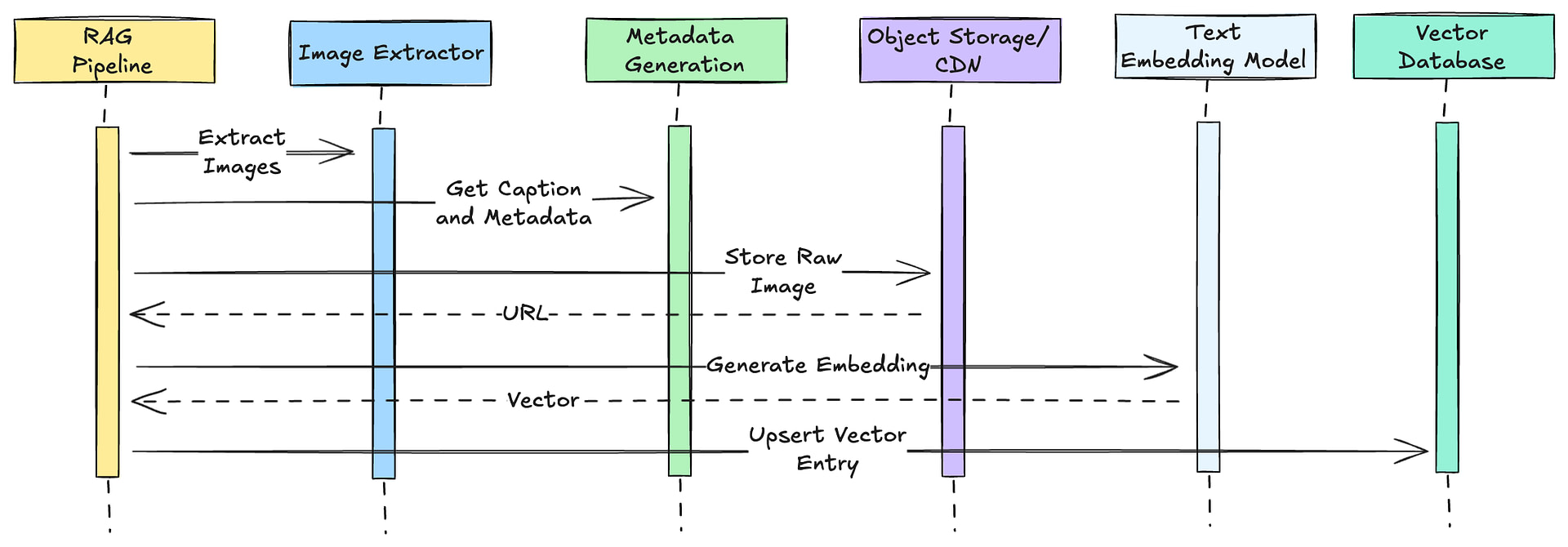
Your RAG pipeline should reflect the design pattern that you plan on using in your multimodal RAG system. For example, if you’re planning to use pattern 3, you would have a pipeline that looks a lot like this:
Picking a Vector Database
There are certainly no shortage of vector databases available to pick from. You shouldn’t expect much difference using multimodal embeddings vs. text embeddings in terms of nearest neighbor performance using cosine similarity or other similarity metrics.
However, if you plan to use pattern 2 and store multimodal data in your vector database, you will find that some databases have limitations on how much metadata you can include in a vector entry.
Keep this in mind when making your database selection. If you’re going to base64 encode images, you can quickly run up against these data size limits.
Implementing RAG? Check out Vectorize
I started Vectorize with my co-founder Chris because we kept watching people build RAG applications that didn’t work very well. They’d get their vector indexes populated, then find out they were sending their LLM all sorts of irrelevant content. We built Vectorize to solve the difficult, painful problems so developers like you can focus on the interesting, fun parts of AI development.
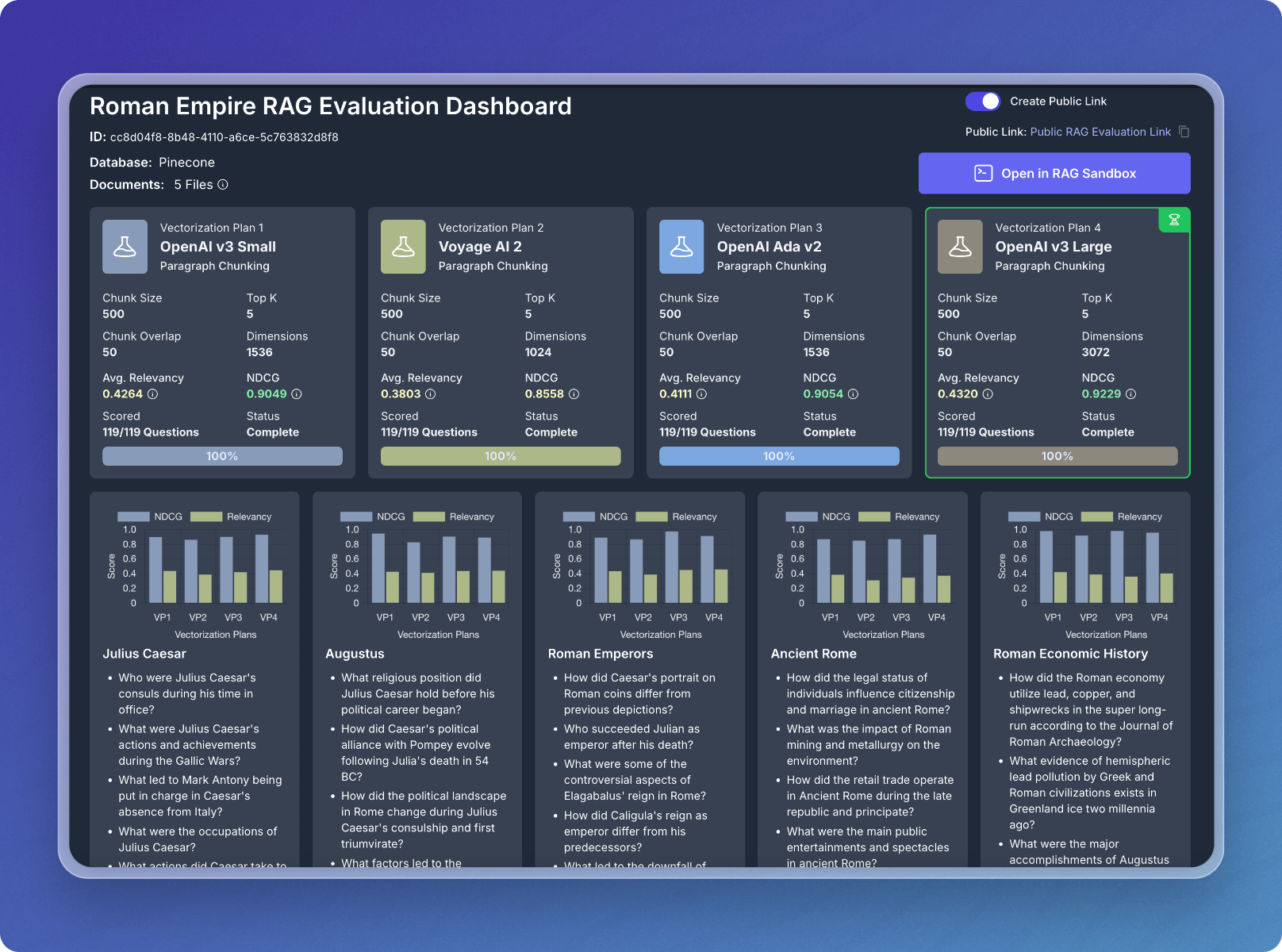
RAG Evaluation
Do you love the idea of writing a bunch of throw-away code trying out different embedding models and chunking strategies with your vector database? Neither do we. That’s why we built a RAG evaluation engine that tells you the best vectorization strategy for your unique data.
RAG Pipelines
Do you wake up in the morning excited by the prospect that you might get to troubleshoot all the annoying problems that can happen when you’re ingesting data into your vector database? I didn’t think so.
That’s why we built our RAG pipeline architecture to handle those problems for you. Error handling, retries, back-pressure, exponential backoffs are all built into every pipeline.
Source system unavailable? Don’t worry, we’ll keep retrying and giving the system time to get healthy. Big influx of changes? We’ll buffer it so your vector database doesn’t get overloaded.
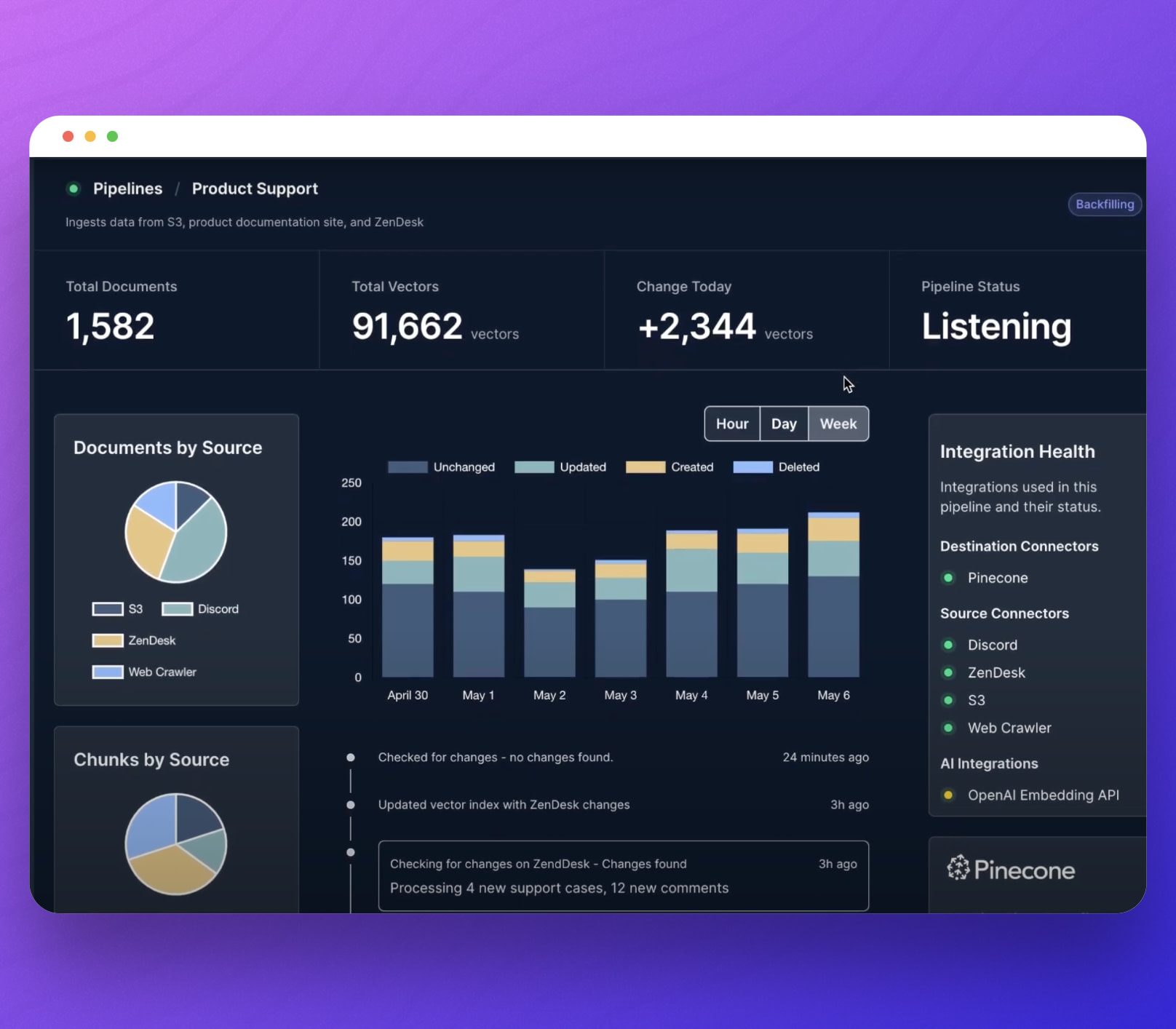
And of course you’ll get real time visibility into your vector data so you can see exactly what’s been processed.
Use Vectorize for Free
Vectorize gives you a forever free tier that’s made for developers. You can find the best vectorization strategy with our RAG evaluations, build a pipeline and update your data weekly without ever paying a cent.
I hope you give it a try! If you do, I’d love to hear what you think.