Streamline Your AI Search Capabilities with Vectorize and Elasticsearch
Vectorize now integrates with Elasticsearch vector database!
Elasticsearch’s vector database is built for fast, real-time search and retrieval of vector data. Vectorize automates the creation and management of vector indexes, and keeps those indexes up-to-date so your large language model (LLM) provides accurate results. The combination of Elasticsearch and Vectorize gives you optimal performance without the burden of manual data preparation, and reduces the amount of time needed to build your AI applications.
With this integration, you can automate vector index creation and management, ensuring your AI applications deliver accurate, up-to-date results faster than ever.
Why Elasticsearch with Vectorize?
Elastic’s vector and hybrid search capabilities provide a robust foundation for handling large, complex datasets. With support for both structured and unstructured data, Elastic is a natural fit for real-world Generative AI (GenAI) models. Its semantic search functionality enhances contextual understanding, resulting in AI-generated outputs that are both accurate and relevant. This is particularly beneficial for tasks that require specialized knowledge, such as delivering personalized recommendations, improving product search accuracy, and tailoring conversations based on user behavior—among a wide range of other applications.

Build Accurate, Production-Ready RAG Pipelines
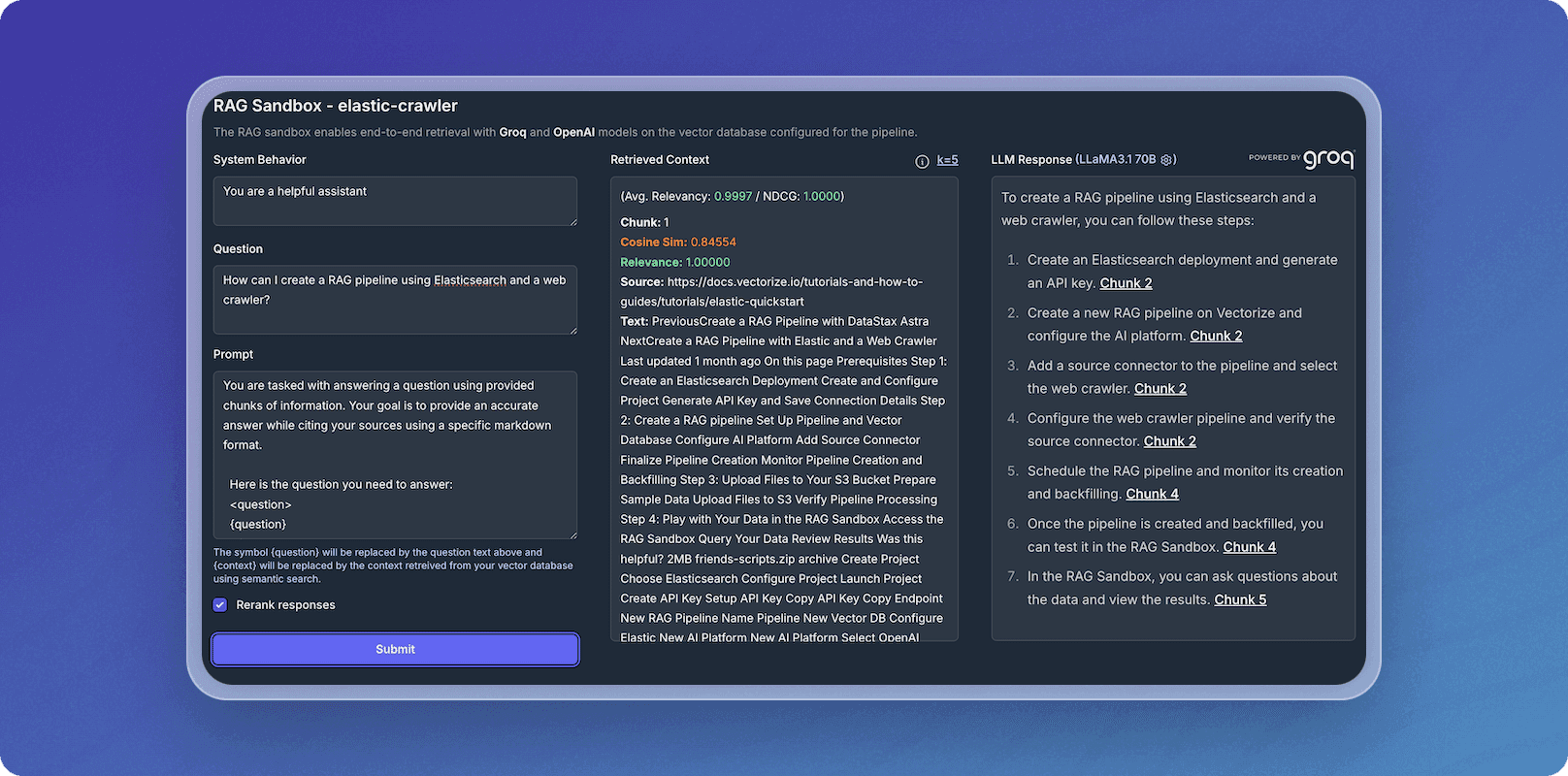
Building reliable RAG pipelines can be challenging, especially when fine-tuning data for the best search performance. With Vectorize, this process becomes data-driven and automatic. Vectorize’s RAG Sandbox lets you evaluate different embedding models and chunking strategies, allowing you to determine the best approach for your data before you build your pipeline.
To illustrate how Vectorize simplifies the process, we created a RAG pipeline which ingested Vectorize’s documentation via a web crawler and created search indexes in an Elasticsearch vector database. We then asked the LLM “How can I create a RAG pipeline using Elasticsearch and a web crawler?” In this screenshot you can see the response to the question, as well as the document chunks retrieved based on the query. You can change the LLM to see how different LLMs perform on your data, and determine which one to use in your AI application. Evaluating performance with the RAG Sandbox gives you hands-on control to compare models, tweak parameters, and ensure your AI delivers optimal results.

Once your pipeline is deployed, Vectorize continuously updates and optimizes the vector indexes, ensuring your LLM always has the latest data and delivers the most relevant results.
Integrating Vectorize with Elasticsearch helps you quickly build accurate, up-to-date AI applications. This allows you to focus on higher-level development, rather than spending time maintaining and optimizing vector indexes manually.
Get Started with Elastic Cloud and Vectorize
Ready to see how Vectorize can help your team take full advantage of Elasticsearch’s capabilities? Sign up for Vectorize and explore how easy it is to build production-ready RAG pipelines.