Want more accurate AI Agents? Give them better data.
Everyone wants their AI agents to be accurate, but the most important factor in delivering that accuracy is also the most overlooked.
Accuracy doesn’t come from the model alone. It depends on how well the system helps the model get the right data for the task.
Retrieval is often treated as something the model will figure out on its own. Developers will hand the LLM a few general purpose endpoints that perform semantic search or other lookups, and expect the model to get back what it needs.
The LLM will attempt to query for the right information, but the data that comes back will often be insufficient for the model to prepare a comprehensive response to the user’s request.
This leads to inconsistent outputs that can have major impacts on the overall performance and accuracy of agentic AI systems.
The issue is not model quality. It is that the system has not given it a clear way to access what matters.
Fortunately, this is fixable. With a few targeted changes, you can give agents more structured ways to retrieve the data they need.
And as you’re about to see, it’s easier to get right than you might think.
Building an agentic retrieval system
The building blocks of retrieval are simple. Nearly everything you surface comes down to either operational data or knowledge.
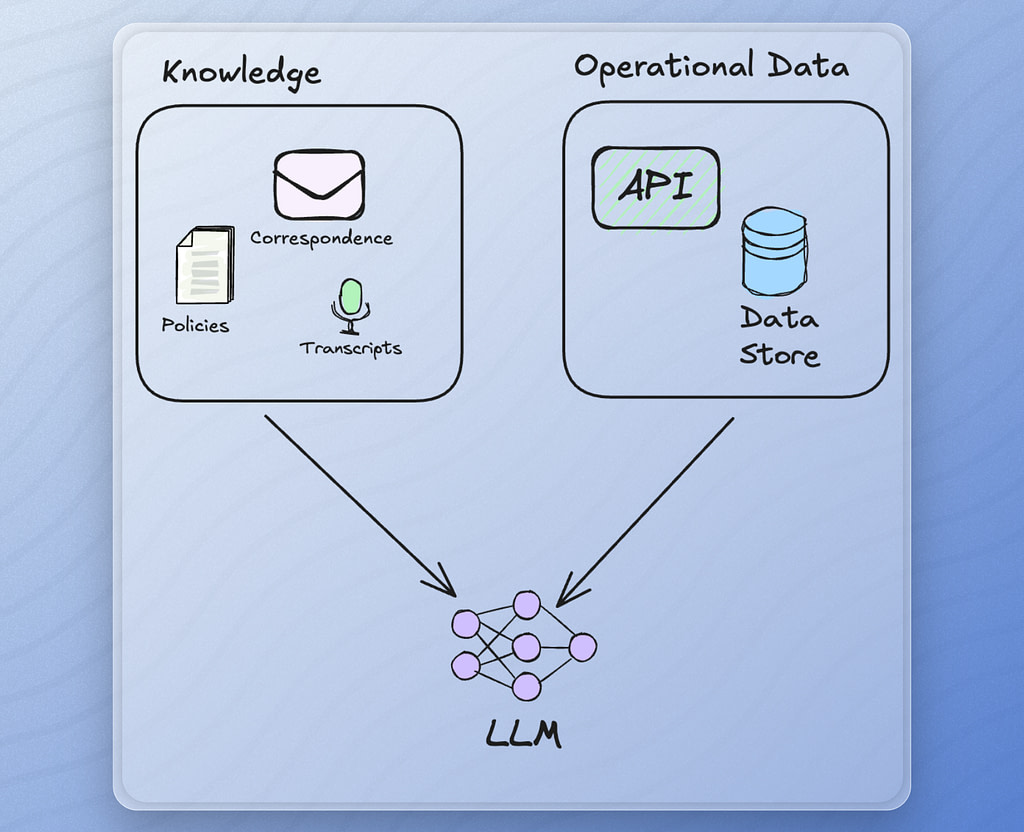
Operational data is structured, real-time, and tied to specific entities or events. Think support tickets, transaction records, or usage logs. Because it is well-defined and often retrieved through database queries, it is usually predictable and easy to control.
Unstructured knowledge is more complicated. Working with documents, contracts, onboarding guides, internal wikis, and any other freeform text requires additional processing to reliably connect it to your LLM. It is messy, inconsistent, and hard to align with a specific task. The only practical way to retrieve from it is through approximation.
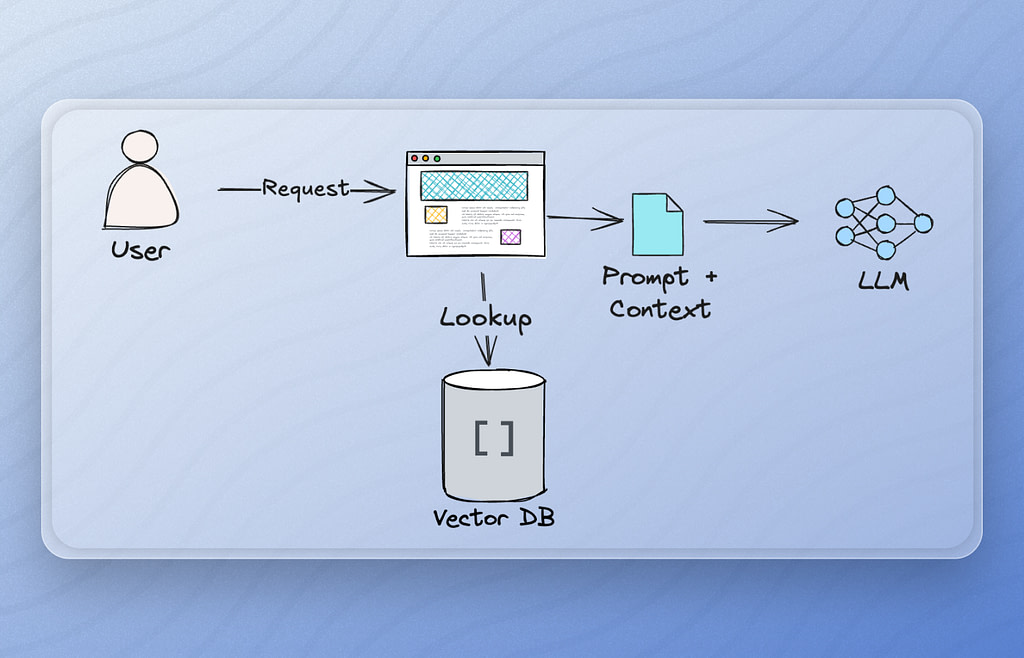
Semantic search is the default tool for this kind of data. It works by embedding both documents and queries into the same vector space, then returning the most similar matches. This avoids reliance on keywords and supports flexible language understanding.
Semantic search is the foundation of most retrieval augmented generation (RAG) systems. These systems typically rely on a vector database to perform semantic search and to retrieve the relevant context needed to respond to a user’s request in a conversational AI system.
This works well when relevance can be judged by meaning alone or when working with a small dataset. For example, if you’re trying to understand what the indemnity clause says across a small corpus of contracts, semantic search can surface the correct context, even if the wording varies. It is flexible and does not rely on exact phrasing.
That flexibility becomes a problem when the task requires precision. Say you’re reviewing indemnity clauses only from MSAs signed in the last year, governed by New York law. Semantic search does not understand contract type, jurisdiction, or version unless those details are stated clearly in the text and happen to influence the embedding. You may get clauses that sound relevant but come from the wrong kind of contract or an outdated version.
To fix this, we can enrich our raw document text with structured metadata. This allows us to narrow the set of content we’re working with to relevant documents before performing semantic search. This technique of metadata filtering is key to allowing AI agents to find the right context.
Enriching Vector Data with Metadata Automatically
With Vectorize, you can define and attach structured metadata to your documents as part of a RAG pipeline.
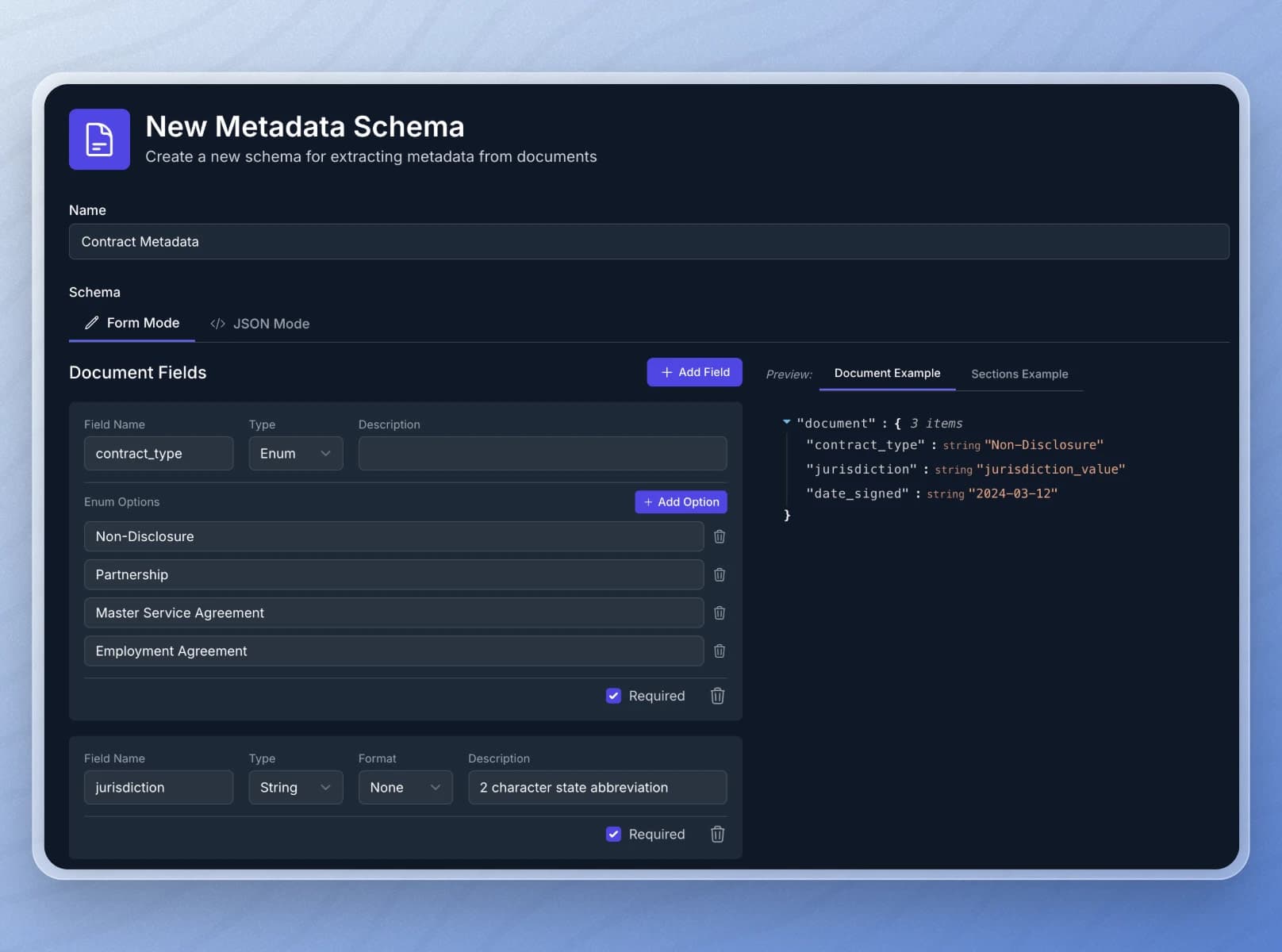
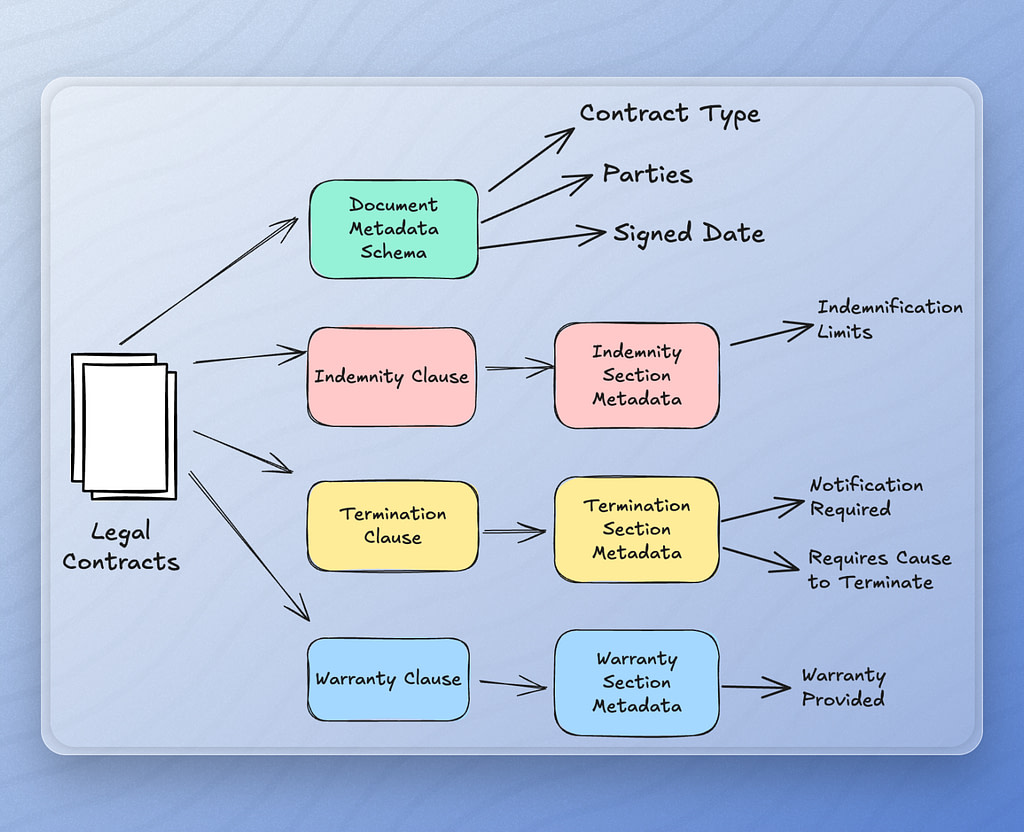
For example, when working with legal documents such as contracts, you may want to capture specific metadata properties like contract type, jurisdiction, and date signed.
The way you accomplish this is by defining a document schema.
Inside our schema, we can define the metadata fields we want to extract from each document in our RAG pipeline.
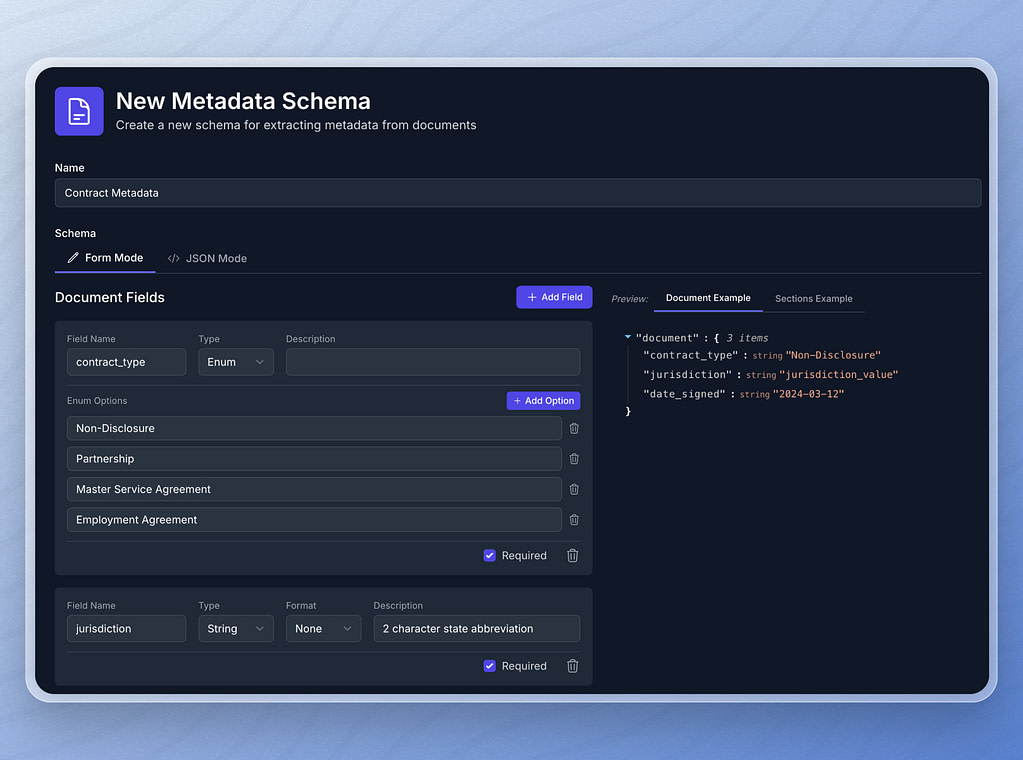
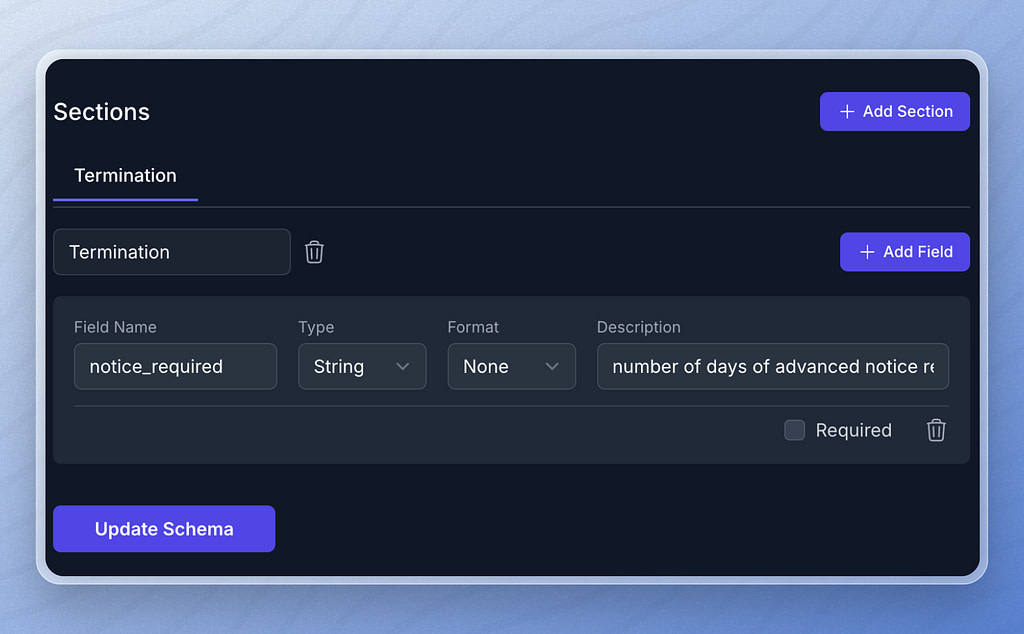
In addition to document level metadata, we can also define metadata about specific sections of our documents. For example, we might want to look for termination clauses to identify how much advanced notice we must give if we want to cancel a contract. Section level metadata allows us to define the termination section of a contract and the metadata associated with that section.
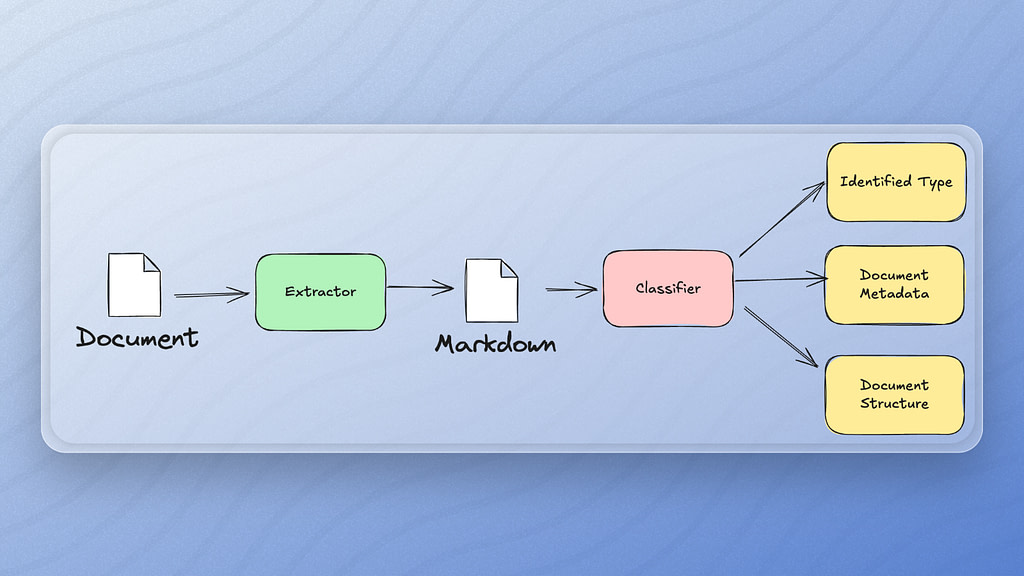
When a document is ingested into your RAG pipeline, Vectorize will attempt to classify the documents to match it with the metadata schema configured in your pipeline. This allows you to mix and match documents of different types in the same pipeline, ensuring each processed document has the correct metadata associated with it in your vector database.
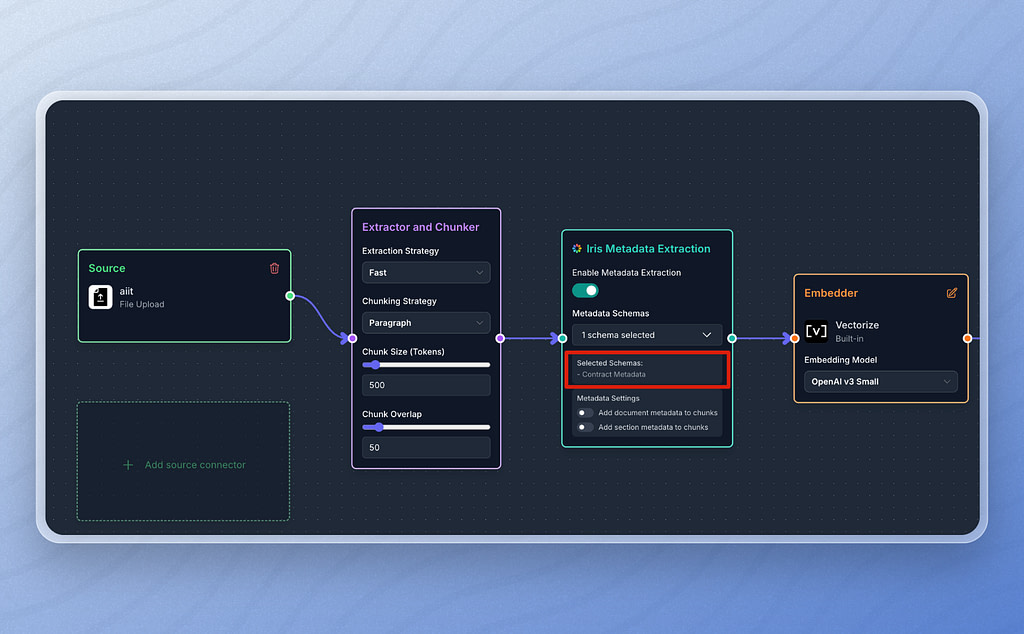
You can optionally include the metadata in the text of each document chunk that gets written to the vector database as well. This allows you to improve basic semantic search results for scenarios where you don’t want to perform explicit metadata filtering.
Curating Data Retrieval for Agents
As your knowledge base grows in complexity, the likelihood that the LLM will execute the right query to get the context it needs goes down. This is because generic search functions with complex metadata filtering options leave too much room for interpretation. The LLM will often make queries that are inefficient or off the mark, then attempt to use the returned context to generate a response based on suboptimal context.
Well defined, structured metadata enables you to create a cleaner, more descriptive retrieval layer based on the way you want the LLM to retrieve data.
For example, you may have a significant variety of legal documents such as vendor contracts, nondisclosure agreements, purchase orders, employment agreements and so on. Setting the right metadata filters can allow you to get at a specific set of data, but only if you set the filters correctly.
To faciliate this, we can curate the retrieval functions to mask the metadata filtering into simpler functions with clearer intent. For example, instead of handing the LLM a complex schema that has many different attributes which vary based on document types, we can instead create simpler functions and handle the metadata mapping in our function implementations.
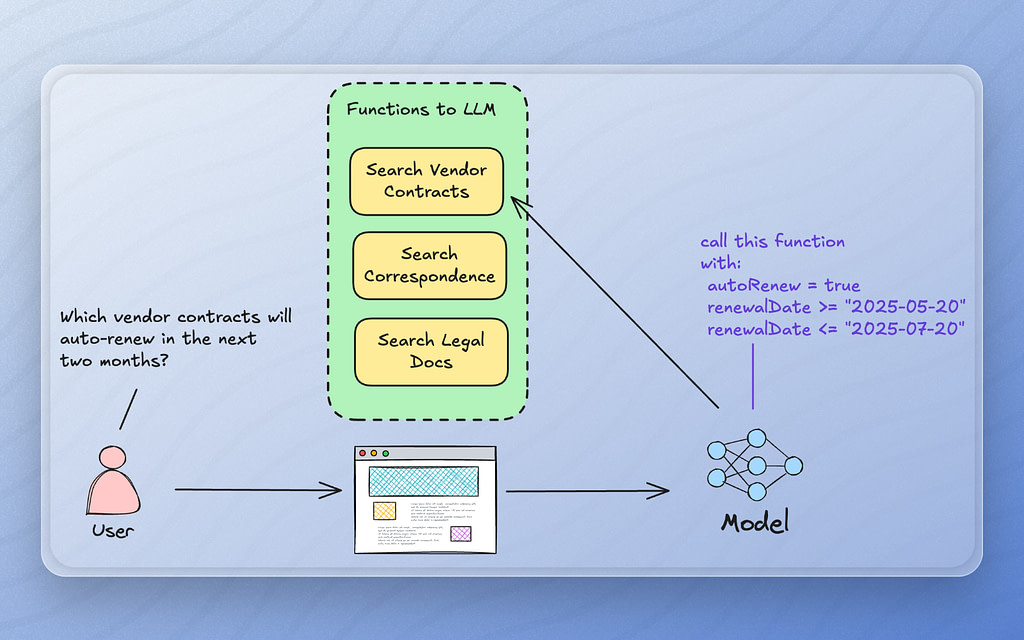
In this example, we can wrap common retrieval patterns for our legal documents to allow the LLM to search vendor contracts with certain combinations of parameters that make sense for vendor contracts. We can offer the LLM a more generic search function like “searchLegalDocs” that it can fall back on when no other options are available.
Building for Speed and Scale
Most enterprises have a growing backlog of AI projects, and getting them done is harder than it should be.
In most cases, the bulk of time, budget, and effort goes into two things: building accurate, reliable retrieval systems, and validating that the overall AI output can be trusted.
Vectorize shortens both paths. It lets you build high-accuracy, agent-ready retrieval pipelines in a fraction of the time. RAG evaluations help you choose the right embedding model and chunking strategy for your data. Metadata extraction gives your agents precise access to what they need, so you get better results with less testing and less guesswork.
Want to start clearing your AI backlog? Sign up for free and get your first RAG pipeline running in under 5 minutes.