How I finally got agentic RAG to work right
“LLMs suck at reasoning” I lamented to my co-founder. “They suck at reasoning and they suck at generating JSON when I tell them to.” I had just spent the better part of two days fighting with OpenAI, Claude, and Llama3. I wanted them to reason their way through helping a mock customer resolve simple product issues. I was tempted to dismiss the excitement around AI agents as irrational exuberance (and to be fair, there is quite a bit of irrational exuberance to be found), but I decided to press on. I’m glad I did.
Traditional Retrieval Augmented Generation (RAG) vs Agentic RAG
Agentic RAG is just retrieval augmented generation used alongside an AI agent architecture.
With both traditional RAG and agentic RAG, you populate your search indexes using a RAG pipeline. The process looks something like this:

If someone asked you to look at this diagram and determine if this was going to support agentic RAG agents or some random conversational AI chatbot, you would have a hard time saying for sure. In both cases, you need to retrieve information. That involves optimizing retrieval processes. That involves RAG pipelines.
There were three data sources that contained information that could help our agentic RAG system answer common user questions. (I was doing this work for a customer and want to respect confidentiality. For that reason, I’m going to avoid mentioning exact technologies we were pulling data from to stay on the safe side of any privacy and security concerns.)
Community Support Forums: Here, customers could chat in real time with each other and with the community support team. There was a lot of great information. There were also incorrect answers and the usual trial and error that people go through trying to resolve product problems.
Documentation: Product docs contained lots of great information about all the features the product contained. If someone wanted to know if the product had some specific feature, then there was a good chance the docs has the answer.
Internal Knowledge Bases: This was an internal collaboration/content platform where people could publish articles or documents for knowledge sharing. This knowledge base was used by the support team, and had internal support playbooks and how-to articles.
You might be wondering: if we’re just going to retrieve information like usual, is the entire idea of Agentic RAG just a catchy buzzword? Not entirely.
To understand why, we have to look closer at how an AI agent architecture works.
Evolution of RAG: from traditional to agentic
What makes an AI agent “agentic”
I’m sure academic textbooks have a much more rigorous definition, but in practice there are two things that your application needs to do in order to be called an AI agent.
First, it needs to have some ability to make decisions on its own, that is, it needs to have agency. If you write a program that executes a series of steps and one step is to call a large language model – congratulations! You’ve built a procedural workflow that calls an LLM – and there’s nothing wrong with that. Just don’t call it an AI agent. AI agents don’t orchestrate the exact series of steps to take. Instead, an agent uses an AI model to decide how to solve a problem rather than defining this imperatively in code. That’s what gives it agency.
AI agents also need to have some way of interacting with their environment. In the case of software, that means making API calls, retrieving data, sending a prompt to an LLM, among other things. The mechanism that LLM providers give us to do this is named tools. It turns out that most LLMs only support one type of tool: functions.
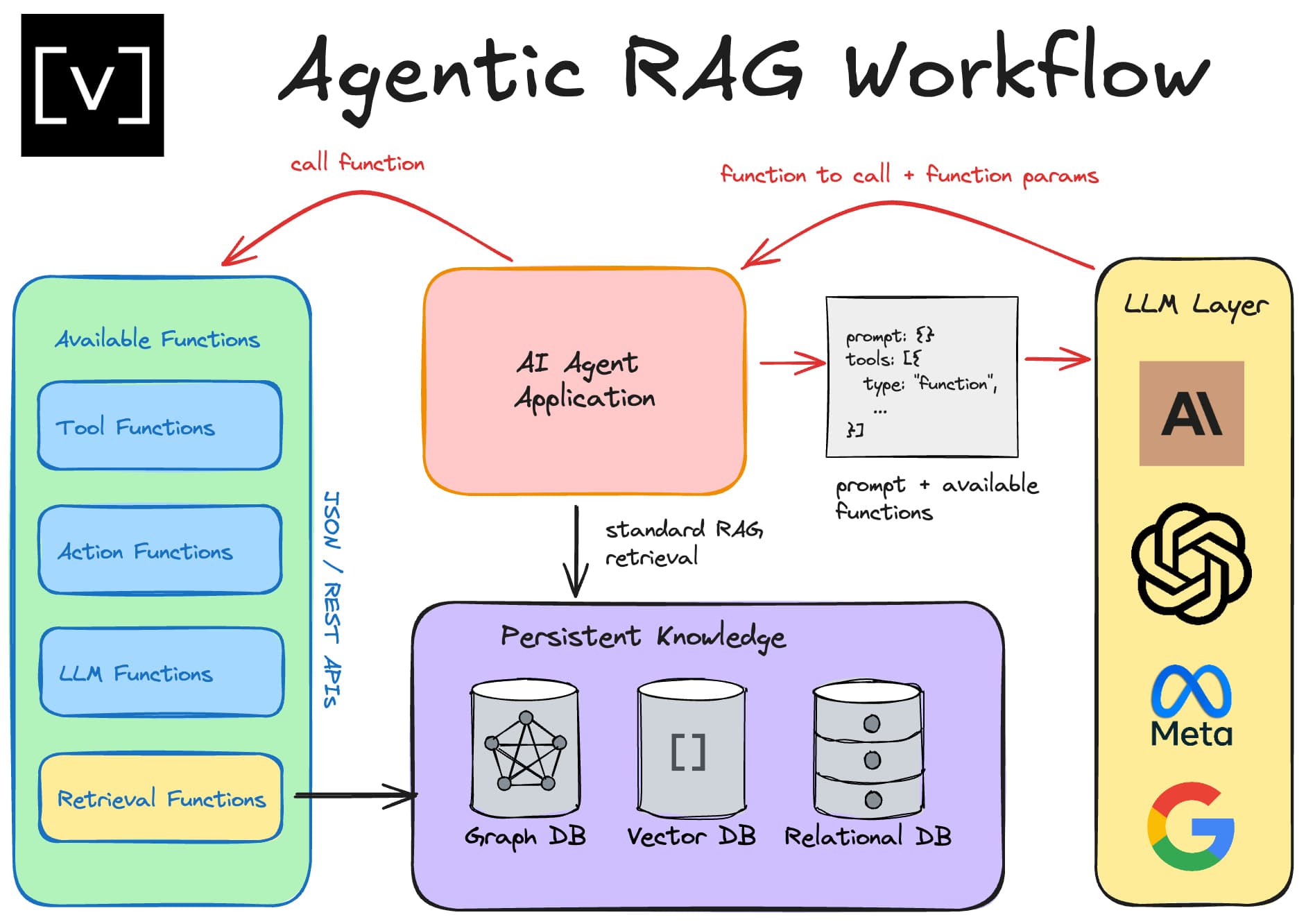
The basic application architecture for an AI agent looks like this:
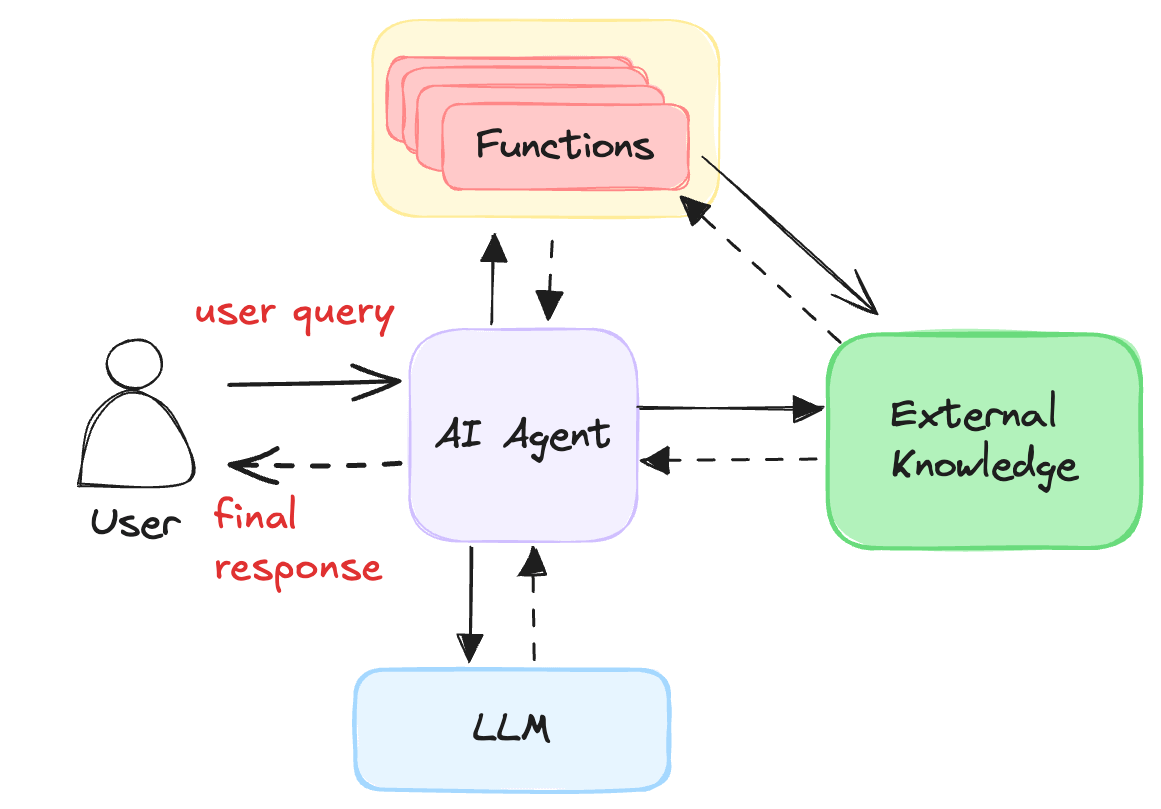
Agentic RAG processing loop
AI agents use a processing loop similar to the diagram below. The loop starts off by taking the user query and performing an initial data retrieval to get useful context. It then passes this to the LLM along with a description of the user’s goal. It also includes a list of appropriate tools that the LLM can use. Each function/tool is defined using JSON schema to describe the supported parameters and allowed values. The LLM is instructed to only respond with a function call and nothing else. When the LLM generates a response, it should be in a standard structure defining the function call that should be performed next. The AI agent is responsible for executing the function the LLM specified in its response. It then passes the function result along with the conversation history to the LLM for the next trip through the loop.
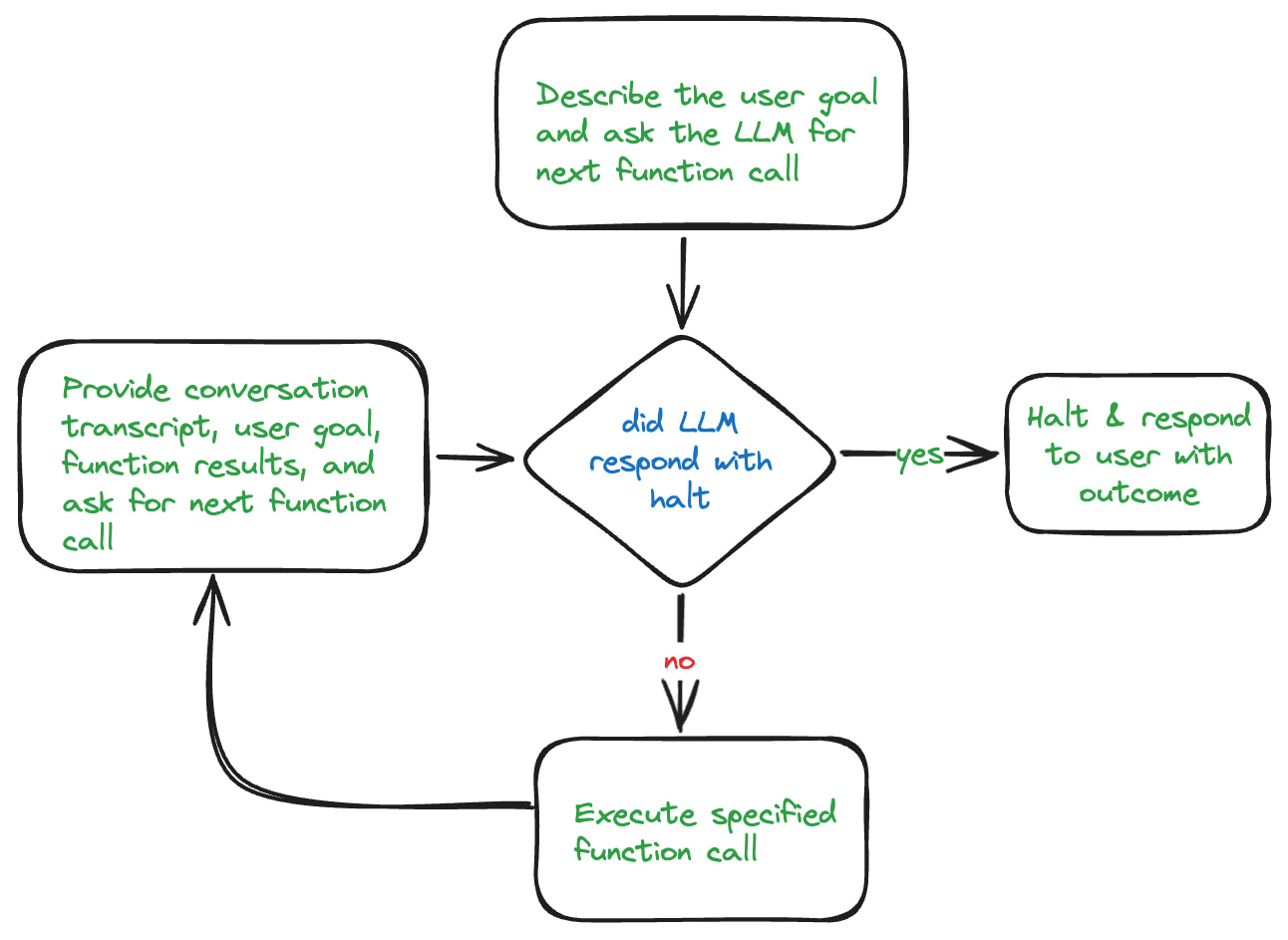
In the case of my AI agent for answering support questions, I wanted the LLM to be able to utilize tools to do things like:
Lookup product information from the documentation
Find relevant data from the customer support forums from customers who had similar problems
Identify relevant information from the internal knowledge base that could help
Terminate the solving process because it had identified a solution
Escalate to a human because the AI agent has done all it can, but can’t solve the problem.
The key to agentic RAG systems: retrieval functions
Getting down to brass tacks, the key design difference between building traditional RAG systems and agentic RAG systems is the idea of retrieval functions. You still need RAG pipelines to populate your vector databases. But as you’re building your search indexes, you need to think ahead to the functions that will create an interface to your search indexes. These functions need to be designed to anticipate the actions your AI agent will need to take to solve the problems you want it to solve.

Designing functions to optimize the retrieval process
In one of the first agentic RAG implementations I tried, I created a function that was a passthrough to the vector database I was using.
I loaded all three of my unstructured data sources into a single vector index and populated metadata to let me retrieve chunks from multiple documents within each system. For example, setting the metadata filter source=docs allowed me to limit my search to context from the product documentation.
My initial findings with this approach were quite poor. The function calls I got from the LLM with the passthrough approach often made no sense at all. It would set metadata filters to search for documentation in the community forums. It would use various metadata fields in odd combinations that didn’t work well.
As you can imagine, when the retrieved data is bad, the generation process is going to be poor as well.
Smaller, more specific functions worked better than functions that allowed complex queries
One of the first optimizations that made a noticeable improvement was breaking out my pass through function that supported complex queries into smaller functions. This abstracted the underlying data sources and made it easier for the LLM to identify the appropriate tool to try next.
For example, having a function called searchDocs that would take a query string and prepopulate the necessary metadata worked better than a vectorSearch function that required the LLM to figure out that source=docs was the way to search the docs.
This was true even when using descriptive JSON schema definitions to describe the allowed values for the source parameter.
Building intelligent agents with dumb LLMs
Large language models are bad at reasoning out of the box, but some models were better than others. The smallest model I tried was Llama3.1 8B and it performed the worst.
It often ignored function calling instructions and the agent application would often need to handle JSON parse exceptions because the generation process would return invalid JSON.
The 70B version was better, but still not great.
JSON mode
When I first started this project, gpt-4-turbo was the latest available model from OpenAI. Even with JSON mode enabled, the response generation would still give me back invalid JSON once every 4-5 attempts.
Agentic RAG and prompt engineering
Prompt engineering is an important component of any RAG system. Creating intelligent agents that rely on agentic RAG are no different. Effective data management strategies will help you achieve performant information retrieval, but they will only get you so far.
The starting prompt
As a baseline, I wanted to see how far we could get by giving the LLM broad instructions to solve the user’s query and handing over our function definition.
You are an automated AI technical support assistant for a company that provides a software platform. You are responsible for helping users with their technical issues and questions.
The user's input is as follows. Your goal is to assist the user in achieving their goal to the best of your ability. Of course, the call to the chat API also included a set of function definitions.
Right answers only
As mentioned above, it was around this time that I broke out the retrieval functions into more constrained, fine-grained pieces.
With the starting prompt, both Claude and GPT-4-Turbo would often generate incorrect responses to the input query.
To address this, I updated the prompt to tell the LLM to not respond with an answer unless it was sure it was correct.
You are an automated AI technical support assistant for a company that provides a software platform. You are responsible for helping users with their technical issues and questions.
You have access to the product documentation, which contains detailed information about the company's products and services. You have access to an internal knowledge base with how-to articles. You also have access to a community forum where users often seek assistance. You can use this information from these sources to help users with their questions and issues.
Unless you are sure you have an accurate answer to the user's question escalate the issue to a human support person using the escalateToHuman function. Do not make up an answer if you are unsure.
The user's input is as follows. Your goal is to assist the user in achieving their goal to the best of your ability. Chain of Thought with agentic RAG systems
This problem required the LLM to performing reasoning such as:
Deciding what steps to take next to get closer to solving the user’s problem.
Deciding when it had found a solution to the problem
Decide when to give up and bring a human into the loop
My first thought was to consult the Chain of Thought research to see if we could apply those advanced reasoning mechanisms here.
For my use case, I didn’t see much improvement using CoT. The techniques used in that paper center on mathematical word problems. Solving these problems involves a step-by-step, repeatable approach and have a specific correct answer. That was not the case with my agent.
Iterating to a working agentic RAG solution
Getting explicit about past interactions
Even though I was passing in the chat transcript each time through the processing loop, I found the LLM would sometimes ignore discoveries it has already made.
It would use agentic RAG to search the docs, get a response, then search the knowledge base. Then it would search the docs again for either the exact same query or a very similar one.
The fix for this was adding the instruction:
Consult the transcript for any other discoveries you have made. Afterwards, the LLM did a better job of remembering what it discovered so far and taking that into account in subsequent paths through the loop.
Breakthrough moment: structured responses
While I was working through implementing agentic rag for this use case, OpenAI launched their `gpt-4o` models and introduced structured responses.
At that point, the agent was getting better at ensuring data completeness in its responses and using information retrieval to get the information it needed. I was still experiencing frequent cases where the LLM produced invalid JSON responses which would interrupt the processing loop.
Using structured responses with strict=true improved this issue. Whatever scientific research OpenAI has been doing in this area seems to be paying off.
With structured outputs, my agentic RAG approach to building AI agents is starting to produce reliable and trustworthy outputs.
Lessons learned
Best Practices from traditional RAG still hold for agentic RAG
Just like traditional RAG, agentic RAG relies on contextually relevant content to help the LLM generate more comprehensive response. Data quality matters a lot.
Building a downstream rag pipeline from your unstructured data sources to support comprehensive information retrieval is necessary to solve the problems agentic RAG addresses. Just like with traditional RAG, agentic RAG needs up to date information.
Don’t rely solely on the LLM’s ability to reason
Your agentic RAG system will make mistakes. Agentic RAG development is often an art more than a science. You’ll want to consider ongoing quality assurance mechanisms and other external tools that can help you monitor the performance of your agents over time.
The hard part of agentic RAG is still the RAG pipeline
I have the same gripe about every RAG framework that I’ve tried. They tend to focus on the parts of the problem that are the easiest to solve. Data retrieval and interacting with the LLM are not a difficult thing to do.
Handling the many nuances and challenges of data engineering around unstructured data sources to provide up to date information that’s optimized for information retrieval is the tedious part of retrieval augmented generation.
Looking ahead: autonomous agents and multi-agent systems
I’ve been spending a lot of time building agentic RAG systems with customers here at Vectorize. There are two particular areas of focus I’m going to spend some time writing about in the coming weeks.
Making multiple agents collaborate
Building agentic RAG systems for single agents involves a number of design challenges and hurdles. As the complexity of the tasks increase, it’s natural to refactor responsibilities into multi agent systems. When multiple agents collaborate with one another to create intelligent systems, you must consider a new set of architectural concerns.
Familiar requirements such as secure communication protocols and working with sensitive or confidential data still need to be addressed. Managing system resources, access controls, and implementing robust data protection measures also come to the forefront when you implement agentic rag in an architecture requiring multiple agents.
Agentic RAG with autonomous agents
For many agentic RAG use cases, there is no end user interacting with the agent. Instead, autonomous agents identify and solve problems on their own.
Use cases such as content moderation, copyright infringement, and quality assurance systems require agentic RAG agents that are autonomous.
This adds a new dimension to the processing loop. Often these agentic rag agents rely on event-driven triggering and must not only identify the best way to solve a specific goal, but also identify the goal.
Here, agentic RAG systems that require access to textual and visual data, vast knowledge graphs, and natural language understanding. An agentic RAG approach still relies on information retrieval, integration with a large language model and external tools. But it can also involve more complex queries and processing logic to help the agentic RAG agents operate autonomously.
Next steps
If you’re building AI agents, RAG systems, or are interested in learning more about this space, I encourage you to try out Vectorize. With Vectorize, you can use our RAG evaluation platform to identify the embedding models and chunking strategies that will yield the best performance for your unique data.

Armed with this information, you can build a RAG Pipeline to ingest data into your vector database.

Vectorize lets you offload the data engineering challenges associated with building a production-grade RAG system, and focus on the more interesting parts of your application. To get started with Vectorize, visit https://platform.vectorize.io to create a forever-free account today.