How to build a better RAG pipeline

Introduction
In a short period of time, large language models (LLMs) and the applications they power have become an integral part of the way we work. For those of us who have embraced tools like ChatGPT and Claude to serve as our sounding board, help us write code, and just generally get more done, it’s becoming harder and harder to imagine going back to a world where we don’t have these tools to rely on.
Data Driven Vectorization Use our free experiments to find the best performing embedding model & chunking strategy. Try Free NowHowever, as useful as these tools have been at enabling personal productivity, they have yet to live up to the hype of transforming businesses and revolutionizing society. At least for the moment, generative AI feels more like a very useful new tool in our toolbox rather than a disruptive technology that makes the toolbox obsolete all together.
Large language models do not know your data
One of the biggest barriers to using generative AI to completely automate common, repetitive tasks is its lack of access to relevant information. Out of the box, LLMs are limited by the information contained in their training data. They have no contextual understanding of domain specific knowledge which limits how useful they can be on their own.

For instance, let’s imagine that you notice your 2019 Toyota Camry is starting to make a weird noise. You can ask ChatGPT what this might mean and it will answer questions to the best of its ability. It will base those answers on information included in its training data such as public car forum threads and the car manual provided by Toyota.
Examples of data that ChatGPT wouldn’t know about include things like new manufacturer recalls that have been announced since its last training cutoff. Likewise, it has no awareness of the work done recently on your particular 2019 Toyota Camry. You can see that without this up-to-date information, it is very difficult for the LLM to generate responses that can definitely make a diagnosis as to the root cause of the annoying noise.
This same limitation exists for almost all potential LLM applications.
Retrieval augmented generation (RAG) overview
A new approach called retrieval augmented generation (RAG) has emerged to address this challenge. The idea behind RAG is to provide a bridge between the LLM and your proprietary information. This includes relevant context which may be stored in external knowledge bases, file systems, large documents, SaaS platforms and many other potential places.
On paper, the idea behind retrieval augmented generation is pretty simple as shown here:

The user starts by submitting a question or request to a RAG application. The application then takes that user query and performs a similarity search, usually against a vector database. This allows the LLM application to identify chunks from the most relevant documents to then pass to the LLM. Using the user query along with the retrieved data allows the LLM to provide more contextually relevant responses that takes into account a more complete view of all available data.
Retrieval augmented generation typically combines techniques of prompt engineering with information retrieval. A typical RAG workflow involves injecting relevant chunks into a prompt template so that users get more accurate answer answers with fewer hallucinations from the language models.
The power and challenges of unstructured data
Certainly, the need for relevant information is nothing new in application development. However, one of the unique aspects of solving this challenge while building generative AI features is the heavy reliance on unstructured data.

Relevant information often comes from unstructured data sources
In order for the LLM to have the necessary contextual understanding to provide accurate responses, it often requires access to data that is not readily accessible using traditional information retrieval techniques. There is no SQL interface to your Google Drive. There’s no API to retrieve the 5 most similar customer service requests to the one a customer has right now.
This has led to the rapid adoption of vector databases to provide a work around to this problem. Using an embedding model, developers and AI engineers can extract the relevant information from external knowledge bases and turn that information into a set of high dimensional vectors. This lays the foundation for very effective semantic retrieval, which is at the heart of any retrieval augmented generation system.
Data engineering for unstructured data is lagging
You might be wondering why this is a problem at all. After all, aren’t we just loading data into a database? We already know how to do ETL, what’s so special about this one?
The biggest differences between a traditional data pipeline and a RAG pipeline are threefold. First, most traditional data engineering solutions are optimized to handle structured data integration. In these cases, you have a well defined data structure at both ends of the pipeline. Here, you have a completely unstructured input on one end, and a numerical vector representation at the other. It’s not clear up front how many vectors a given piece of unstructured data should produce, or if the vectors that get generated are going to work well for your use case.

Second, the connector ecosystem for most data engineering platforms has poor support for both unstructured data sources as well as for vector databases destinations. And finally, the process of transforming your unstructured sources into an optimized vector search index, is completely absent in most data engineering solutions.
All of this has led to the need for a new type of pipeline, purpose built to power retrieval augmented generation (RAG) use cases. This type of pipeline is unimaginatively referred to as a RAG pipeline or sometimes a vector pipeline.
The key data requirement for LLM-powered apps: RAG pipelines
What is a RAG pipeline?
At least in this article, when we talk about a RAG pipeline, we specifically mean one where the source is some sort of unstructured data. That data could exist in the form of files on your Google Drive or Sharepoint, it should exist as notes in relational database table, it could be emails exchanged between customers and a support team, or many other possible options.

The destination for a RAG pipeline is a vector database. And along the way, there are a number of transformation and document pre processing steps that help to achieve a scalable, robust RAG architecture.
Primary objective of a pipeline
The primary goal of a RAG pipeline is to create a reliable vector search index, populated with factual knowledge and relevant context. When done correctly, you can ensure that the retrieved context provided by the vector store also reflects up to date information.
In this way, you can ensure that anytime a user query requires information from an external knowledge source to generate an accurate response, your large language model will have the necessary context to respond the user query correctly.
Retrieval augmented generation pipelines: A step by step breakdown
A RAG pipeline typically follows a standard sequence of steps to convert unstructured into an optimized vector index in your vector database. Let’s start by looking at the end-to-end flow of a simple RAG pipeline:
Ingestion
To build a RAG pipeline, you must first understand the sources of domain specific, external knowledge that you want to ingest data from. This could be a knowledge base, web pages, or custom datasets sourced from SaaS platforms. For retrieval augmented generation use cases such as question answering tasks, it’s important to identify the source documents that contain the most relevant information for your anticipated user queries.
Extraction
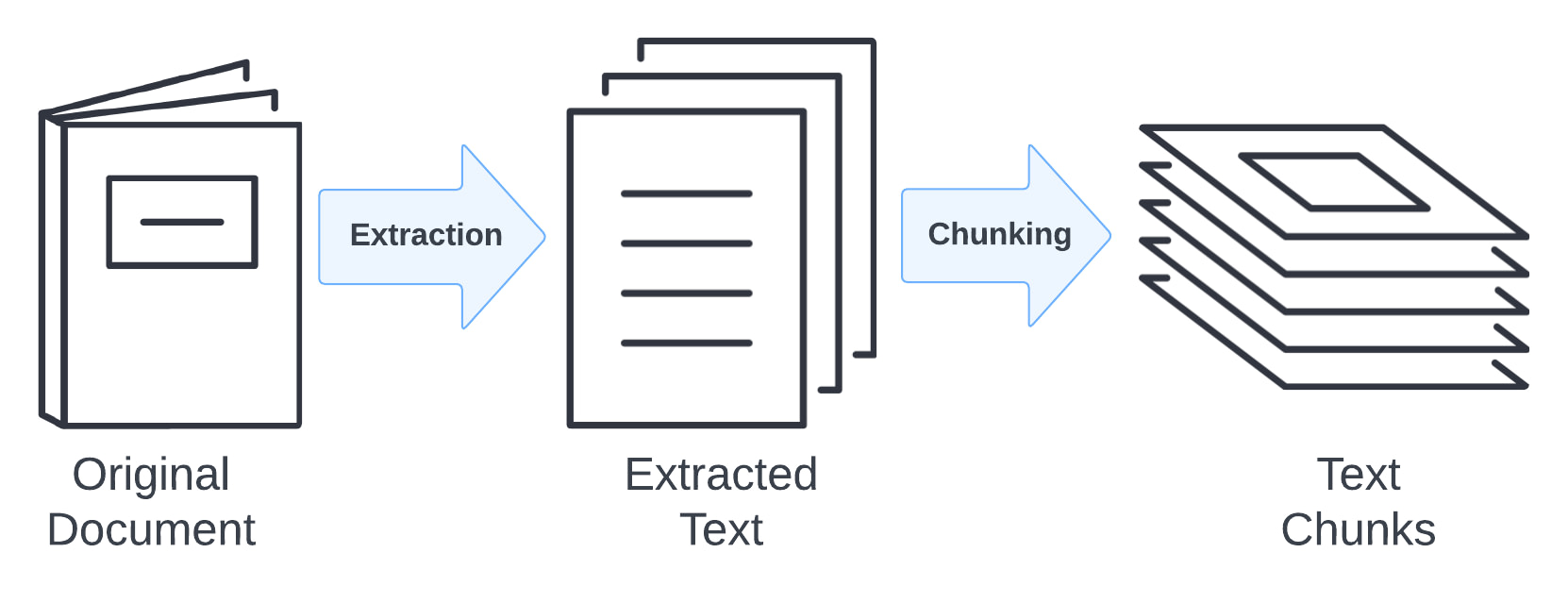
Because many sources of unstructured data require some processing to retrieve the natural language text data contained inside them, we need to include extraction logic in our RAG pipeline. Data extracted from data sources may or may not be immediately useful.

For example, PDF documents in particular are notoriously tricky to convert into useful text. Document pre processing with open source libraries work in simple cases. However, for complex PDFs you may need to rely on something more purpose built for knowledge intensive NLP tasks to arrange the extracted natural language into a form that more closely resembles the way a human would read the document. Other advanced options, such as AWS Textractor, rely on solutions rooted in neural networks and other machine learning techniques to power this process. This approach has several advantages in terms of accuracy of the extraction, but comes with increased costs.
Chunking/Embedding
Chunking and embedding are two independent steps but are very closely related to once another. Chunking refers to the process of taking the content extracted from the source data and converting it into a set of text chunks.
The chunking strategy used here is an important factor in retrieval augmented generation (RAG). That is because the text chunks you create in this step will be used later by your RAG application to supply context to the LLM at runtime.
The embedding step is where we actually turn the text chunks into document embeddings that will ultimately get stored inside our vector database. These vectors are generated using an embedding model such as text-embedding-ada-0002 or text-embedding-v3-large from OpenAI or of the many options from companies like Mistral AI. Most embedding models are general purpose, although companies like Voyage AI are experimenting with fine tuning these models for domain specific use cases like finance or legal.

Persistence
The vectors that are produced from an embedding model will usually have a fixed number of dimensions in each vector. When you create your search index in your vector database, you will typically define the number of dimensions for the index, and any new data inserted into the index must have the specified dimension length.
Refreshing
Once your vector database is populated, you’ll need to think about how to keep your vector data synchronized with the source data which was used to populate it. Otherwise, you retrieval augmented generation use case will eventually encounter problems as the retrieved documents are out of date, and your language models will generate incorrect responses to user queries.

Building an architecture for your RAG pipeline
Anyone who has experience in data engineering can tell you that building reliable pipelines is more difficult than you might expect. Vector pipelines for retrieval augmented generation are no exception as we’ll examine in this section.
Lessons learned at Vectorize
Before launching Vectorize, the founding team spent around three years building out a cloud native event streaming platform together at DataStax. As you can imagine, they learned a lot about data engineering and building reliable, mission critical data pipelines for many large companies.
Data Driven Vectorization Use our free experiments to find the best performing embedding model & chunking strategy. Try Free NowThey also learned a lot about retrieval augmented generation and vector databases since DataStax also offered a leading cloud native vector database. Vectorize is basically the platform they kept wishing they had as they were working with customers to help them get retrieval augmented generation apps into production.

Think like a data engineer
Vectorize isn’t focused on solving simple “chat with a PDF” type use cases. The mission is to help developers and companies productionalize their data capabilities around retrieval augmented generation (RAG). From a KPI perspective, this means maximizing retrieval accuracy and accelerating application development for any generative AI feature or applications that rely on vector data.
Real time vs batch
Initially, you might find limited success with using a schedule-based solution, such as cron, to update your vector database. However, as time goes by, it will become increasingly certain that you will encounter use cases that require immediate, real time updates to ensure your RAG applications have the latest context.

Avoiding accidental DDOS
Even more important than having accurate, up to date information is that you can actually respond to your user’s query with retrieved information. This is difficult to do if you inadvertently overwhelm your source system or vector database with a denial of service attack because of a poorly designed RAG pipeline.
Generally speaking, this is another reason why real time data architectures are preferable to batch ones. With an event-driven approach, you have an event topic acting as a buffer between the source and destination. If you have a huge burst of changes, you can throttle the updates to your vector database to avoid service interruptions.

Errors are a fact of life
No matter how well constructed your RAG pipeline is, you will always be at the mercy of the upstream and downstream systems you’re connecting to. Building a resilient system means accepting the fact that errors will happen and having a strategy to deal with those errors when they occur.
API failures
API failures are extremely common. These could be APIs used to retrieve custom data from a knowledge base. It could also be an API to retrieve a set of document embeddings from a service like OpenAI’s embedding endpoint.
Vector database failure scenarios
Just like any piece of infrastructure, your vector database could experience a temporary or sustained outage. These could range from simple timeouts that resolve on their own to more prolonged major outages.

Tokenization & context window challenges
Try as you might, it is sometimes tricky to know exactly how many tokens a given chunk will produce for your embedding model. You may encounter scenarios where your tokenized input exceeds the maximum context window for your embedding model.
Event streaming is the only solid foundation
While we certainly could have used an approach that relies on batch jobs, schedulers and polling to solve the RAG pipeline pipeline problem, that would have been a brittle and naive implementation. Instead, we opted to build on top of an open source event streaming platform called Apache Pulsar.

Pulsar is basically Apache Kafka++. It has all the ultra-reliable event streaming of Kafka plus multi-tenancy, more elastic scalability, and an architecture that is made for Kubernetes. It also has protocol-level compatibility with Kafka, so there’s literally no downside.
Integration with source systems
One of the advantage of using a streaming platform is that you get a connector framework for free. Why is that a big deal?
Let’s say you are relying on batch scripts and polling to perform your initial ingestion or to process changes from some knowledge base. Now let’s imagine you have a lot of data and changes you need to process all at once. With connector frameworks like Kafka Connect and Pulsar Functions, connector instances are stateless and scalable. If a huge burst of changes come through, you just scale the number of connector instances. On Kubernetes, you can even scale them automatically.
Integration with vector databases
Likewise, you get similar benefits on the destination side when it comes to writing vector data into the vector database. One other big advantage of using streaming is that you also have greater control over the throughput of writes into your database.

If your database is healthy you can keep pushing up the ingestion rate. However, if your vector database is under load or you want to avoid costly scaling events (e.g. addding another database pod from your vector database provider), you can let the change events back up in the topic while you process them at a more comfortable pace to reduce risk.
Event stream processing
Throughout the pipeline, you’ll often want some level of lightweight event processing and at times more full featured event stream processing. Examples here might include tasks like document pre processing to generate the appropriate metadata for your source data.
It could also include mediation and data scrubbing tasks to address data privacy requirements.
Retries and dead letter queues
Finally, the key to a resilient pipeline is error handling. Errors will happen. Your APIs will return with HTTP 503 and other error codes. Your vector database will get into an unhealthy state periodically.
A well designed vector pipeline will provide approaches to be resilient to these situations. This means implementing retry logic to account for the case when the processing of a document fails. To avoid overwhelming the source or destination system when retries are necessary, it means relying on techniques like exponential backoffs to give the problem time to resolve.

When things simply can’t be fixed, it means providing dead letter queue capability so problems aren’t swallowed and there’s a mechanism to complete processing once the system becomes healthy again.
Building a RAG pipeline using Vectorize
Vectorize is the easiest way to turn your unstructured data into perfectly optimized vector search indexes in your vector database. Using experimentation, Vectorize assists you in identifying the best performing embedding models and chunking strategies for your unique data.

To see how easy it is to improve the performance of your RAG application, sign up for a free Vectorize account now.
Conclusion
As generative AI continues to be top of mind for developers and companies alike, having a solid strategy to ensure your LLMs always have access to the right data couldn’t be more important. Choosing the wrong approach now is likely to come back to haunt you later. By following the guiding principles in this article, you can build a robust, reliable set of capabilities to ensure your retrieval augmented generation applications provide innovative, accurate user experiences.