How to Get More from Your Pinecone Vector Database

Why are vector databases so popular right now?
Just a few years ago, vector databases were a niche technology that powered traditional machine learning use cases like recommendation systems and fraud detection algorithms. Today, the explosion in interest around generative AI has elevated vector databases to new heights. Among the most popular options for most developers and companies is Pinecone vector database.

Pinecone is a cloud native vector database. Interestingly, it is only available as a cloud service compared to other products which are often times available as self-hosted open source solutions.
Pinecone was one of the first vector database vendors to recognize how transformative this technology would be for generative AI use cases. In particular, techniques such as retrieval augmented generation (RAG) are driving a lot of Pinecone adoption by developers who want a highly scalable semantic search solution without the hassle of operating an open source alternative.
How do most people use Pinecone?
For a comprehensive explanation of vector databases, head over to our Ultimate Vector Database Guide. In a nutshell, Pinecone is a specialized type of search engine that is purpose build to provide fast, efficient querying of potentially vast amounts of vector data.
Vectors in this context are typically generated using a text embedding model like Open AI’s text-embedding-v3 or ada-002 models. Text embedding models are a type of machine learning model that is intended to accept some text as its input and produce a vector.

A vector is just an array of floating point numbers, but those numbers encode the semantic meaning of the input text. This means that when you query Pinecone, you’ll create a text embedding for some string, and Pinecone will hand back a set of the most similar vectors. This will also include the text that was used to create those vectors. In this way you can find the most similar content that Pinecone has in its search indexes.
This is a powerful technique that lets you connect your private data with your LLM to unlock new use cases.
So while ChatGPT doesn’t have the customer service handbook that your customer support team uses, Pinecone lets you find the relevant parts of that handbook when a customer asks a question. And combining those relevant results with your LLM integration, you can now improve the performance and accuracy of your gen AI applications.
Getting started with Pinecone and vector data
There are two ways to get started with Pinecone: the easy way and the hard way.
Pinecone the hard way
This approach involves writing code to populate your vector database with high dimensional vector data. You will typically accomplish this by identifying all the data you want to include in your vector indexes. You will identify the collections of documents from file systems, knowledge bases, traditional databases, and other SaaS tools.
You’ll usually use either python or javascript along with natural language processing libraries to extract the text from your source data. You’ll then break that text data into smaller pieces, called chunks.
For each of those chunks, you’ll either leverage an open source embedding model from the MTEB leaderboard, or you’ll use a commercial offering such as OpenAI or Voyage AI to generate text embedding vectors. Each vector corresponds to a chunk from your source data.
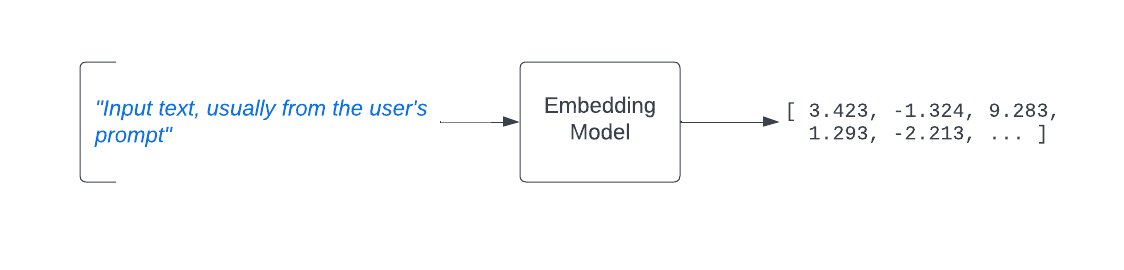
You’ll then use the user friendly api that is provided by Pinecone, often via the python or javascript library, to write that data into your Pinecone database index.
At that point, you are ready to start searching for similar vectors using the semantic search algorithms provided by Pinecone.
Now comes the hard part. You need to verify that the data stored in your indexes are going to deliver high performance, high accuracy results that are going to work well for your use cases in a real world environment.
This process involves creating a large number of example records, performing similarity search queries to retrieve your vector search results. You then must perform an assessment of how relevant those results are, and whether or not those values, along with any metadata, provide the necessary context to satisfy your users and their requirements.
Pinecone the easy way
The easy way to get started with Pinecone is to use Vectorize. Vectorize provides a simple step by step formula to ensure you end up with an optimized search index that is custom tailored for your data and your users.
Step 1: Start with a data-driven approach
There are many different ways to chunk your documents and other source data that you want to turn into vectors. There are also many embedding models you can use to turn those chunks into vectors. A common mistake developers make is to not put enough thought into which approach will work best for their data and their use case.
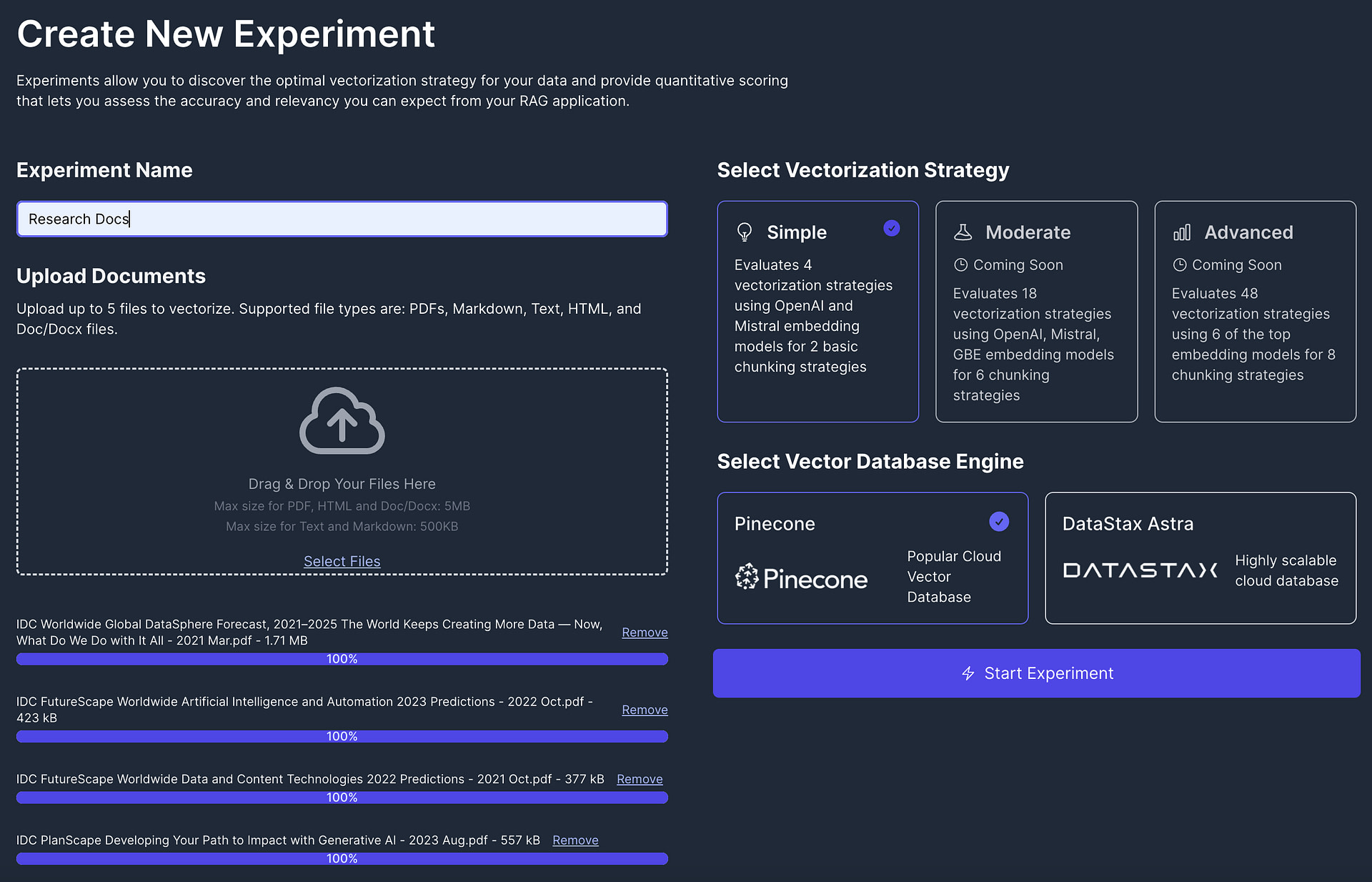
A better way is to leverage the free experiments feature in Vectorize. With experiments, you can take a representative sample of your data and immediately see how various vectorization strategies will perform for you.
You don’t even need a Pinecone instance setup to try this out, Vectorize will provide the vector database engine for you so you don’t need to clutter up your real database with experiment data.
You start by providing a description for your experiment and uploading a representative sample of your data in the form of PDFs, HTML docs, text files, or other document formats:
You can then start the experiment. Vectorize will tell you immediately the topics and categories of questions your data would be best at answering, then it will tell you which vectorization strategy is best at providing relevant context to help answer those questions.
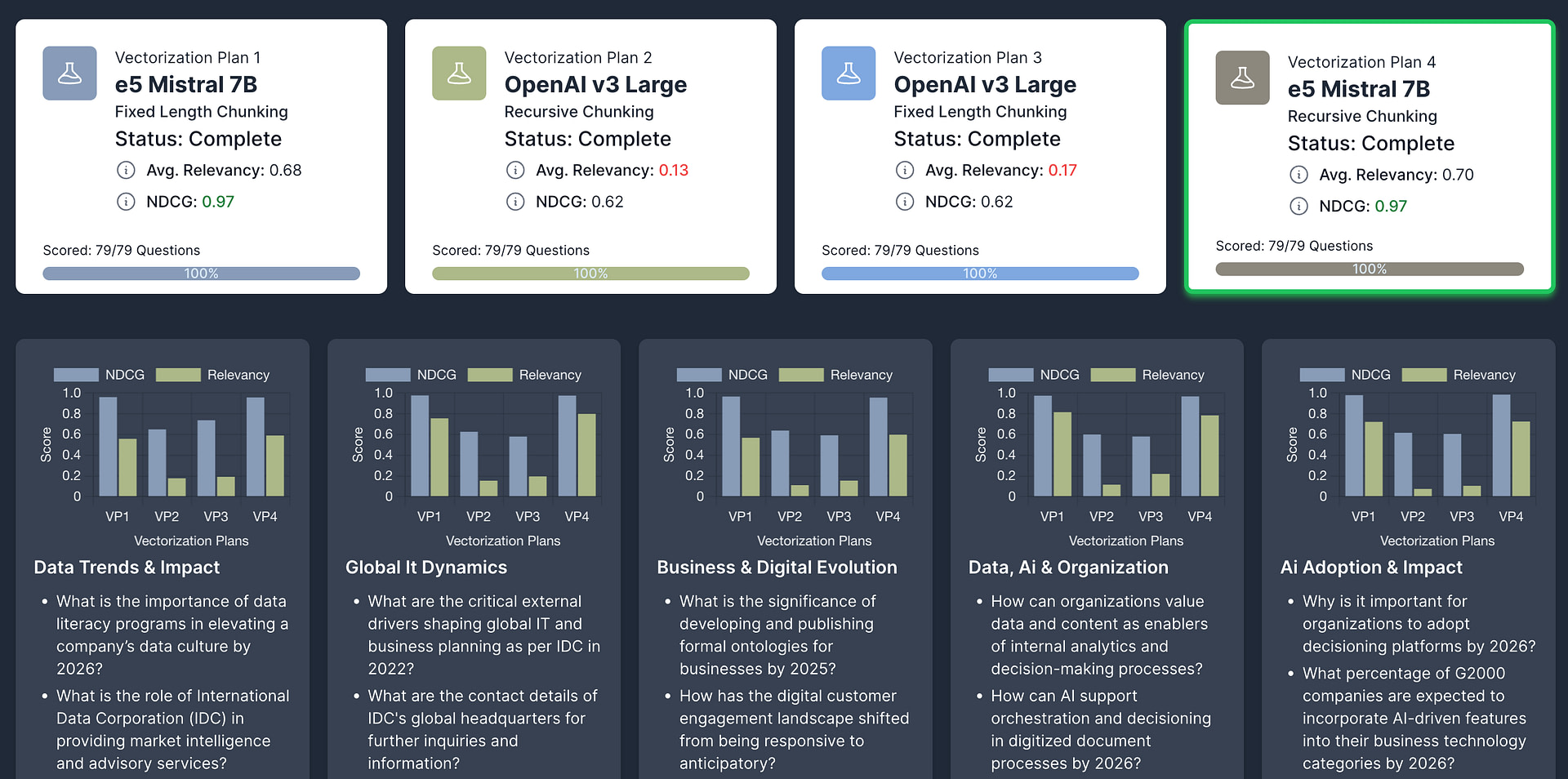
Now instead of relying on gut feel and optimism, you can make a decision on how to vectorize your data using definitive evidence that shows which option will perform best.
Step 2: Assess the vector search performance directly
Using the Vectorize RAG Sandbox, you can “chat with your experiment data” to see if the quantitative assessment of your semantic search results match up with your personal experience.
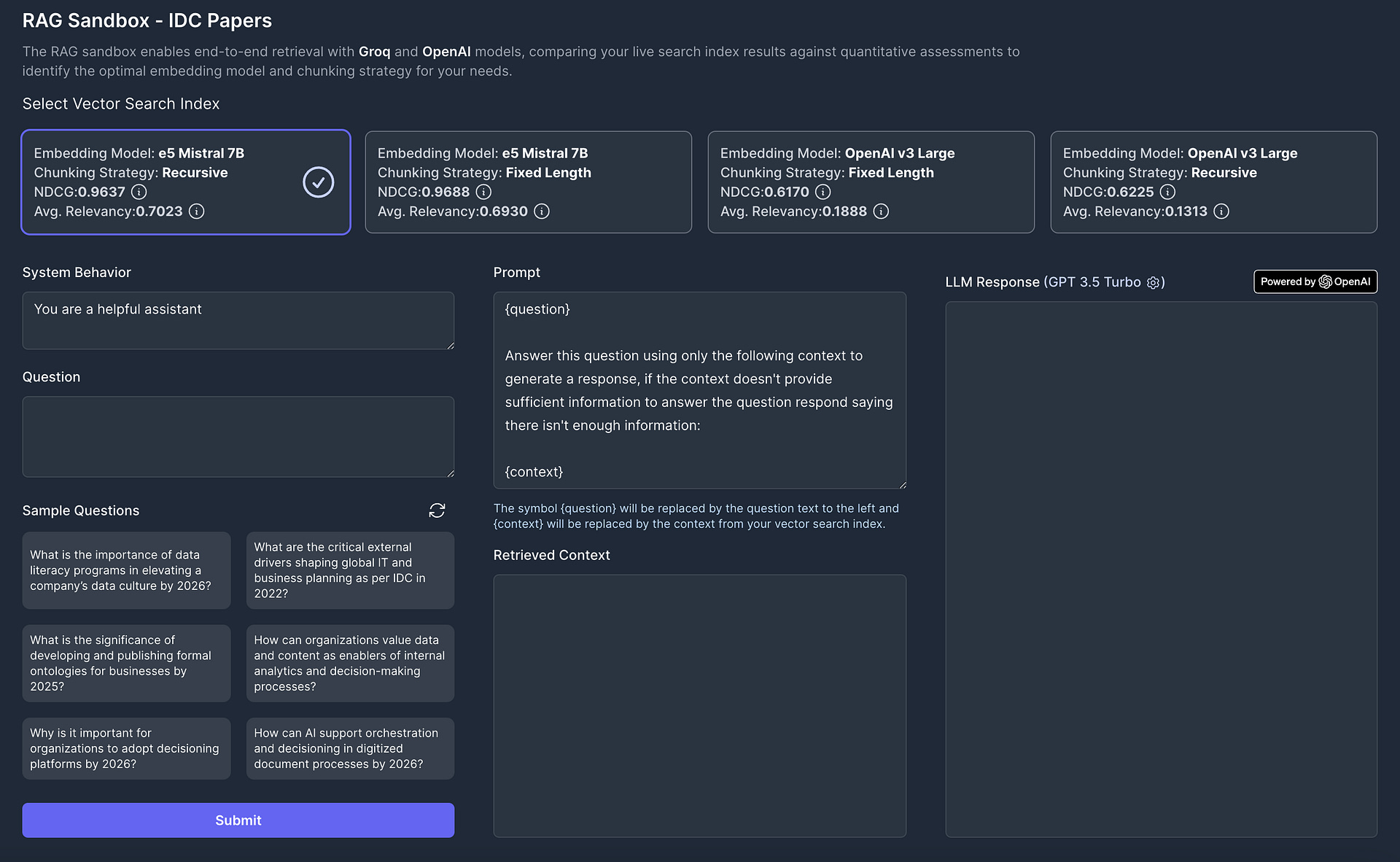
Here you can ask your pinecone vector database any of the questions generated in the experiment or anything you wish. Vectorize will automatically generate a query vector, perform a vector search using the pinecone client, and show you the top results. You’ll be able to see relevancy scores and normalized discounted cumulative gain scores for your results to help further inform your decision.
Step 3: Promote your experiment results into a production-ready vector pipeline
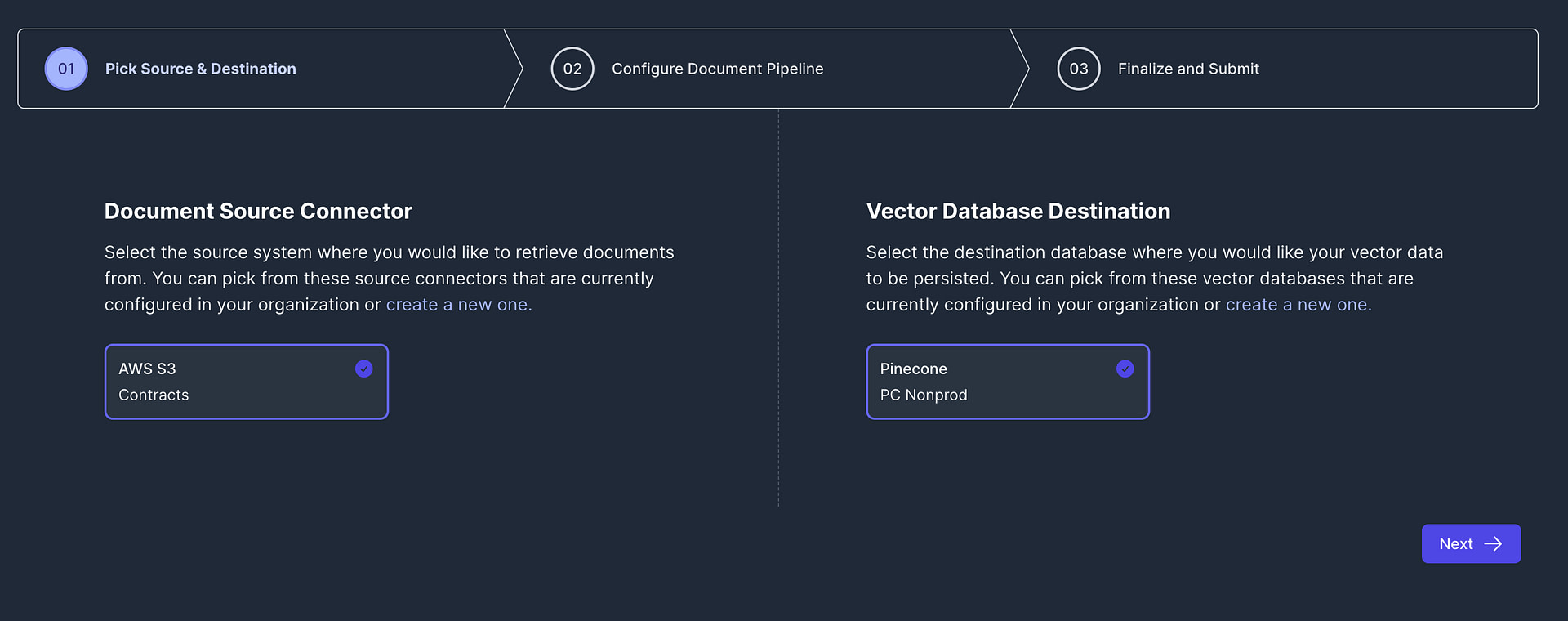
Once you are ready to populate your vector database with your real production data, you can use Vectorize to create a vector pipeline.
To do this, you’ll start by configuring access to your Pinecone using a destination connector.
Here you simply supply your API key and a name. For security, your api credentials are stored in an encrypted secret storage.
Next, you’ll configure the source connector where your data lives. Here you can select from the many file systems, knowledge bases, and SaaS platforms that Vectorize supports.
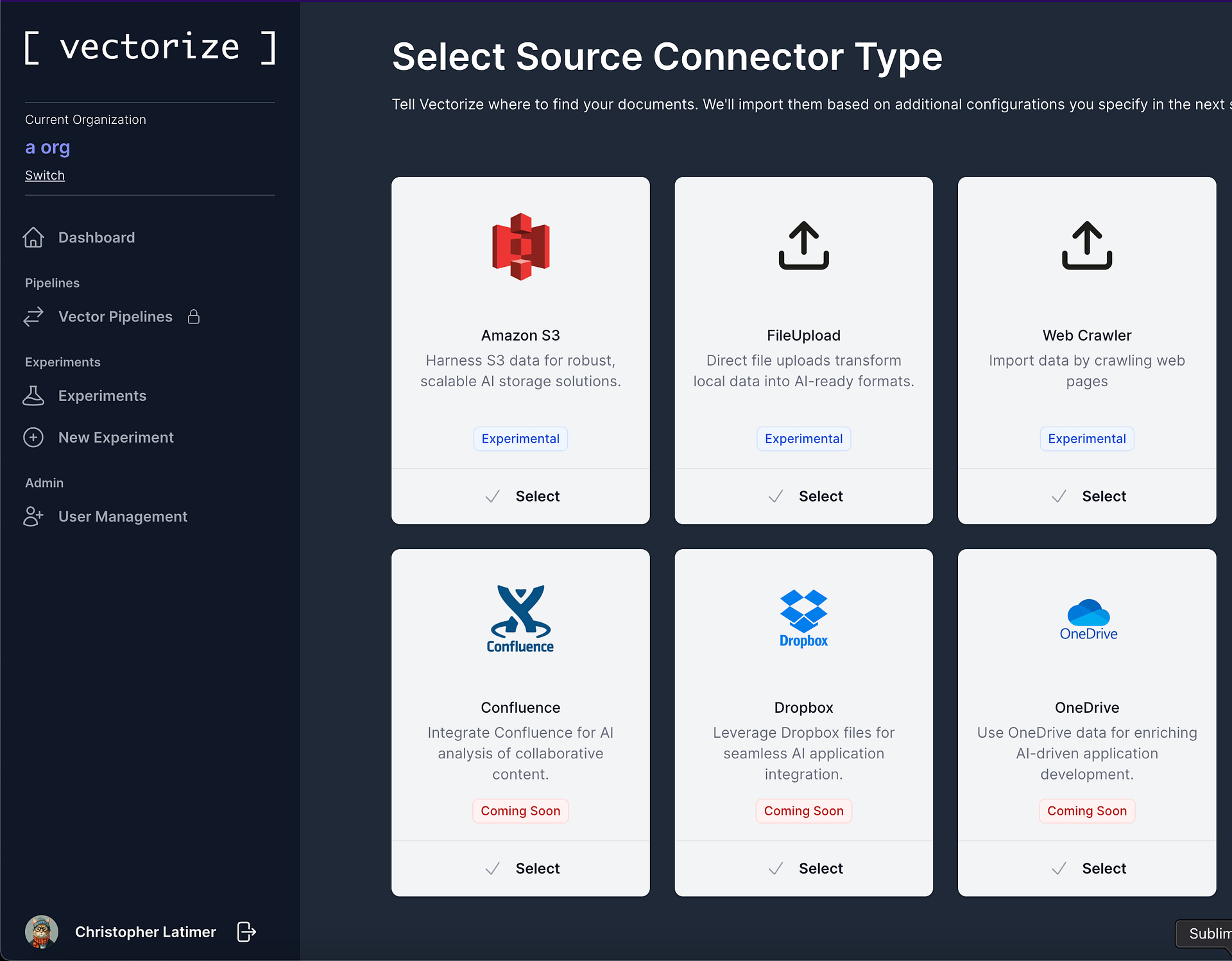
Once your source system and your Pinecone configurations are set up, you can create a vector pipeline to automatically populate your search indexes.
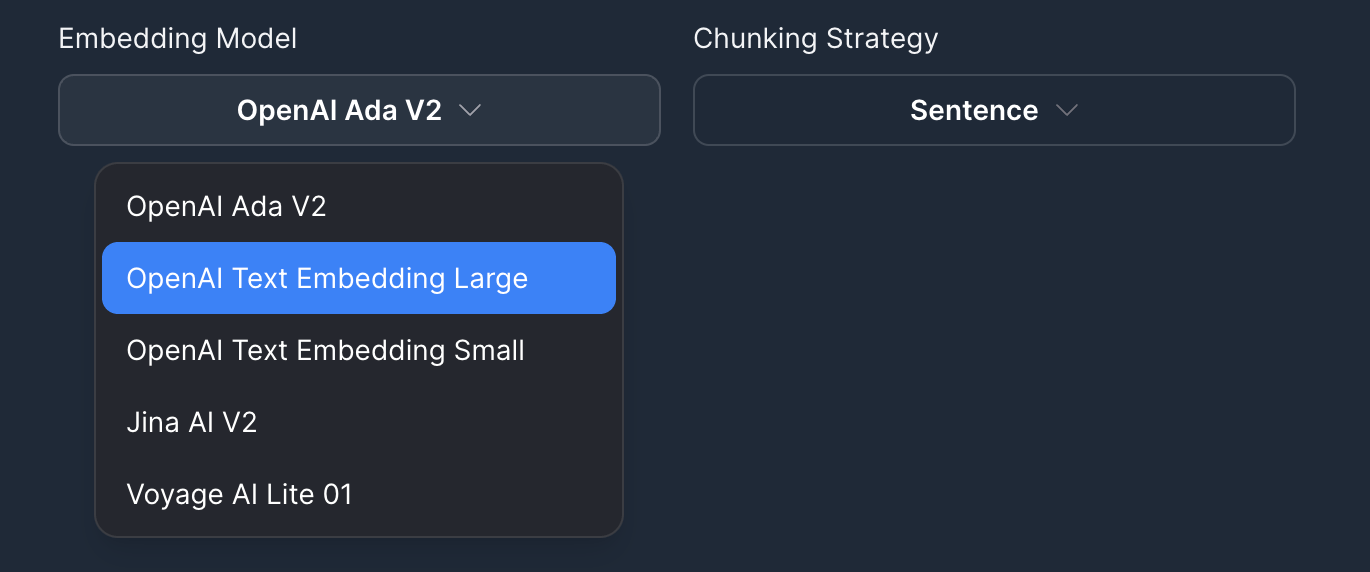
Within the pipeline, you will be able to select the embedding model and chunking strategy that worked best for you in your experiment.
Once this is in place, Vectorize will automatically populate your vector indexes in Pinecone. It will also trigger a watch process that will capture any new data or data changes and perform real time updates as needed. This ensures your Pinecone vector database remains up to date and your customers never .
Key architectural designs for Pinecone vector databases
Serverless or Pod Based?
Pinecone comes with two deployment options: serverless and pod-based and fortunately you can try both options in their free tier.
The Pinecone serverless database has a usage based pricing structure that allows you to start small with a price structure that grows with you. A key attribute of serverless is its ability to let you to scale elastically in response to growing or shrinking workloads.
Pod-based, on the other hand provides you with fixed capacity. While it would be nice if Pinecone could handle massive spikes in traffic instantly with no instability, they too are subject to the laws of computing.
With pod-based vector databases, you will have an easier time pre-scaling your clusters for peak loads. And while Pinecone generally can provide a high-performance search index in either deployment option, you have more control over the compute resources assigned to your database when using the pod-based option. Of course the trade off with this is that you will be paying for capacity that goes unused.
With either option, your costs will scale with the dimension size of the vectors in your index. Each index will require more compute for vectors that have a higher dimension size.
High-dimension vectors require large amounts of object storage and are more computationally intensive to search. Each query must compare each dimension and while indexes help make this process more efficient, it does have a cost to perform similarity searches.
Namespaces vs Metadata filtering
Using filtering
Most vector databases provide metadata filtering to make similarity search more efficient. The idea is to limit the number of values that must be compared in each index to achieve high performance semantic search. This makes vector search more efficient, faster, with better scale.
Using Namespaces
Pinecone extends the standard metadata filtering capabilities by also offering full featured partitioning of your vector data. When you query your data in this approach, you must specify the namespace. Pinecone will limit searching only to the partition within the database that matches the namespace specified. Compared to metadata filtering, this is not as flexible, but is much more scalable and help with use cases such as multi-tenancy or log data.
Implementing semantic search
Querying with a query vector value
Querying in Pinecone is very simple using either the JavaScript or Python client.
In python, you would use this approach:
from pinecone import Pinecone
pc = Pinecone(api_key="YOUR_API_KEY")
index = pc.Index("my-index")
index.query(
namespace="my-namespace",
vector=[0.4, 0.7, -0.3, 0.1, 0.9, 0.4, 0.5, 0.8],
top_k=5,
include_values=True
)Here, we are performing a similarity search using a query vector specified in the vector field. It’s important that the dimension size of your search vector matches the dimension configured on your index.
Querying with a metadata filter
Metadata filtering works very similar to the last example, but we can include a filter parameter which will narrow down the values searched and only records with matching metadata will be returned.
from pinecone import Pinecone
pc = Pinecone(api_key="YOUR_API_KEY")
index = pc.Index("my-index")
index.query(
namespace="my-namespace",
vector=[0.4, 0.7, -0.3, 0.1, 0.9, 0.4, 0.5, 0.8],
filter={
"color": {"$eq": "red"}
},
top_k=5,
include_values=True
)Conclusion
Pinecone makes it easy to accomplish the task of building a similarity search based on vector data. While the Pinecone client offerings are easy to use, Pinecone has many of the same challenges as other vector databases when it comes to ingestion and verifying that your vector indexes will perform well. However, using Vectorize with Pinecone makes this process a breeze.