Microagents: building better AI agents with microservices
“This thing is a tangled mess.” I was relieved to hear the presenter say the words I was thinking. He had just finished walking me through a new AI agent, which I’m going to call Sherpa throughout this article. Sherpa was a proof of concept for a new AI agent their team had been working on.
Built by the innovation group within an online retailer, Sherpa was intended to be a one stop solution for customer service. They wanted the agent to be able to answer questions about customer orders, product details, recommendations, and anything else someone might want help with.
While their solution showed promise, it also had grown unwieldy. As they added more capabilities, the quality of the responses was going down along with the maintainability of their code base.
What is an AI Agent?
If you’re new to AI agents, I recommend checking out this article that covers the basics of an AI agent architecture. For the purposes of this post, I’ll mention the key characteristics that distinguish an AI agent from other types of software.
AI agents have agency
AI agents are given a task and expected to figure out how to accomplish that task on its own. This differs from traditional procedural logic that provides step by step instructions to define behavior throughout the entire system.
In the case of Sherpa, customers would ask a question or make a request and Sherpa would need to figure out how to solve it. As an online retailer, we had access to historical questions that users asked about and had a list of the most common topics: where’s my stuff, how can I return an item, can I cancel my order being among the most frequent.
This self-deterministic capability is a hallmark feature of an agent, but in order to accomplish its task, the team had to give Sherpa the necessary tools to do so.
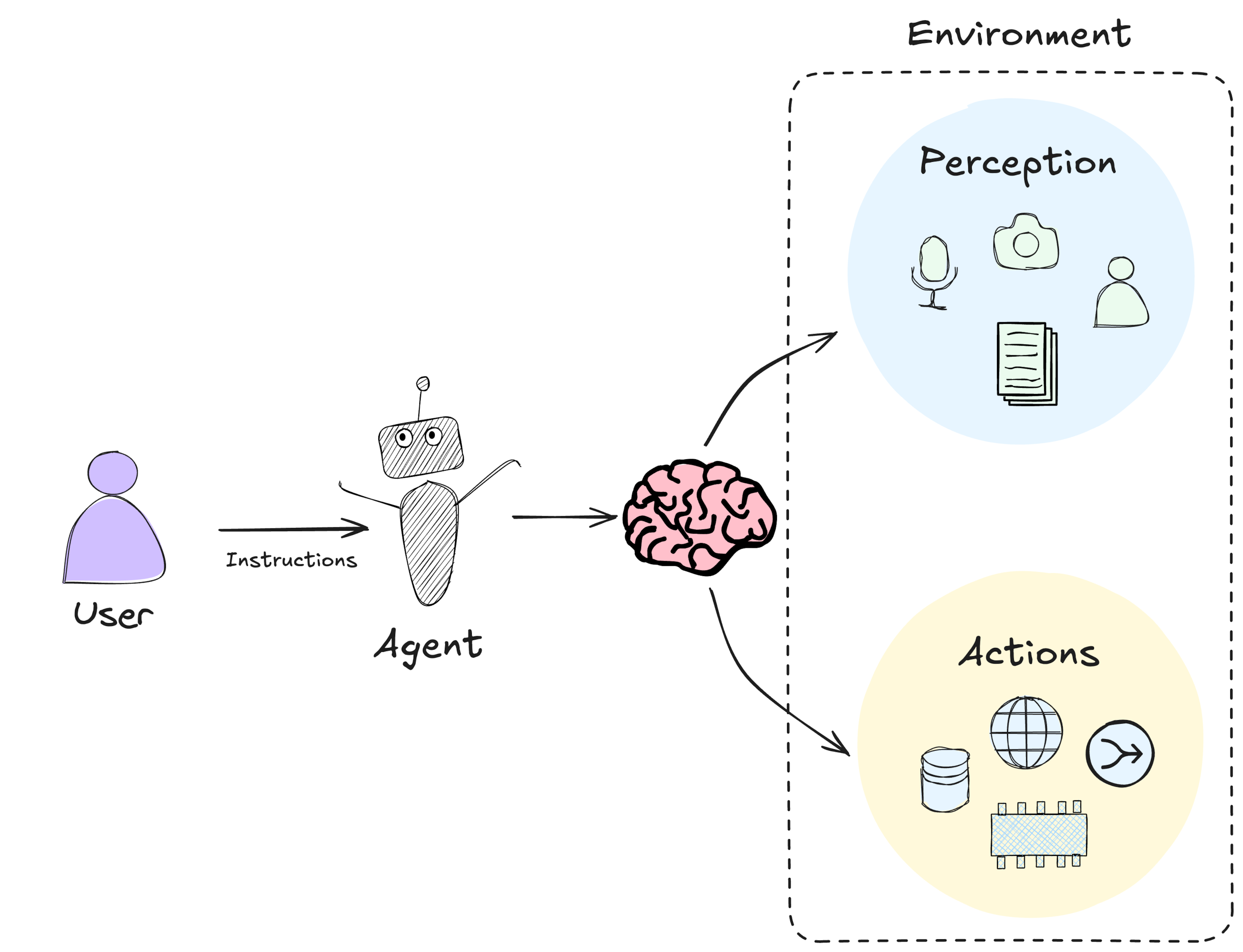
AI agents can interact with the outside world
In addition to its task, an AI agent has access to mechanisms that let it interact with the world around it. These mechanisms will vary based on the nature of the agent. A robotic vacuum will have mechanisms such as cameras, sensors and motors. Agricultural AI agents may use sensors to detect moisture levels in the soil and weather data. One day, AI agents may take a more active role in surgical procedures and rely on image processing and robotic arms to precisely carry out procedures on human patients.
In the case of Sherpa, the agent ran entirely as software. It had mechanisms like API calls and data retrieval functions. These included calls to the Shopify API, to their post-order management system to process returns, chat histories to find examples of how similar questions were answered in the past, and several others.
AI agents also need some form of reasoning to decide which tool to use and how to best complete the task it’s been assigned. LLMs are becoming the most common approach to supplying this intelligence today.
LLM-based agents
In this article, we’re going to focus on use cases where large language models acts as the central brain for the entire application. Language models are provided with a task and instructed to generate a series of actions to accomplish those tasks.
The Sherpa team used Google as their cloud provider and relied on Gemini to provide reasoning and intelligence to their AI agent.
How AI Agents Work: Architectural Overview
Sherpa started off as a Node.js application with an API interface that could be used to invoke the agent.
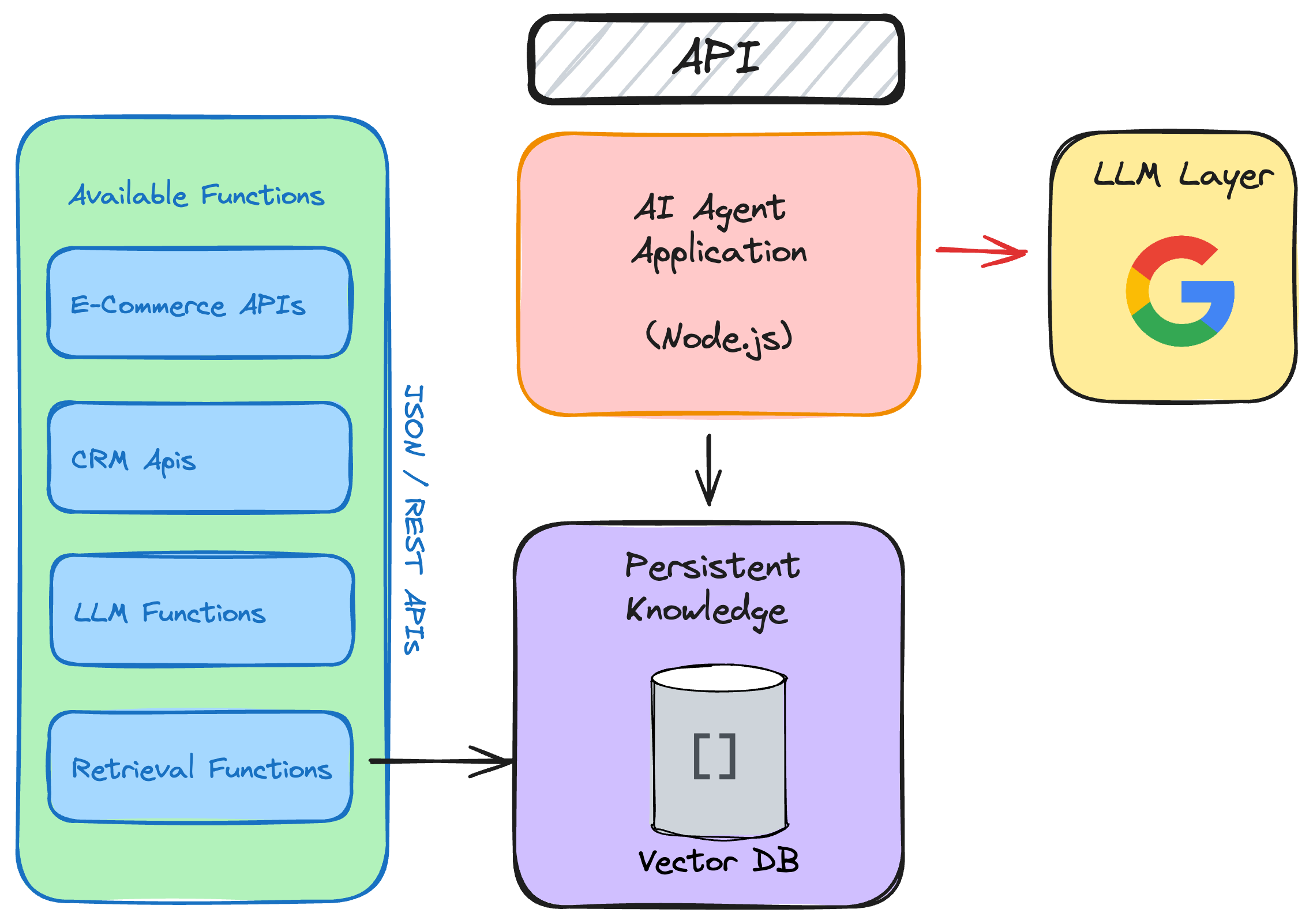
Initially, Sherpa had access to a small number of functions it could call. It could lookup order histories and orders and confirm that the order was received. The architecture of Sherpa was made up of several key components.
Processing Loop
Like most AI agents, the heart of Sherpa is a processing loop. This loop is responsible for determining what action to take next to get closer to accomplishing the desired task. Each time through the loop, Sherpa performs an action. It then evaluates the results of that action and the processing that has occurred in previous iterations through the loop. If the agent determines it has accomplished the intended task, it will terminate its processing.
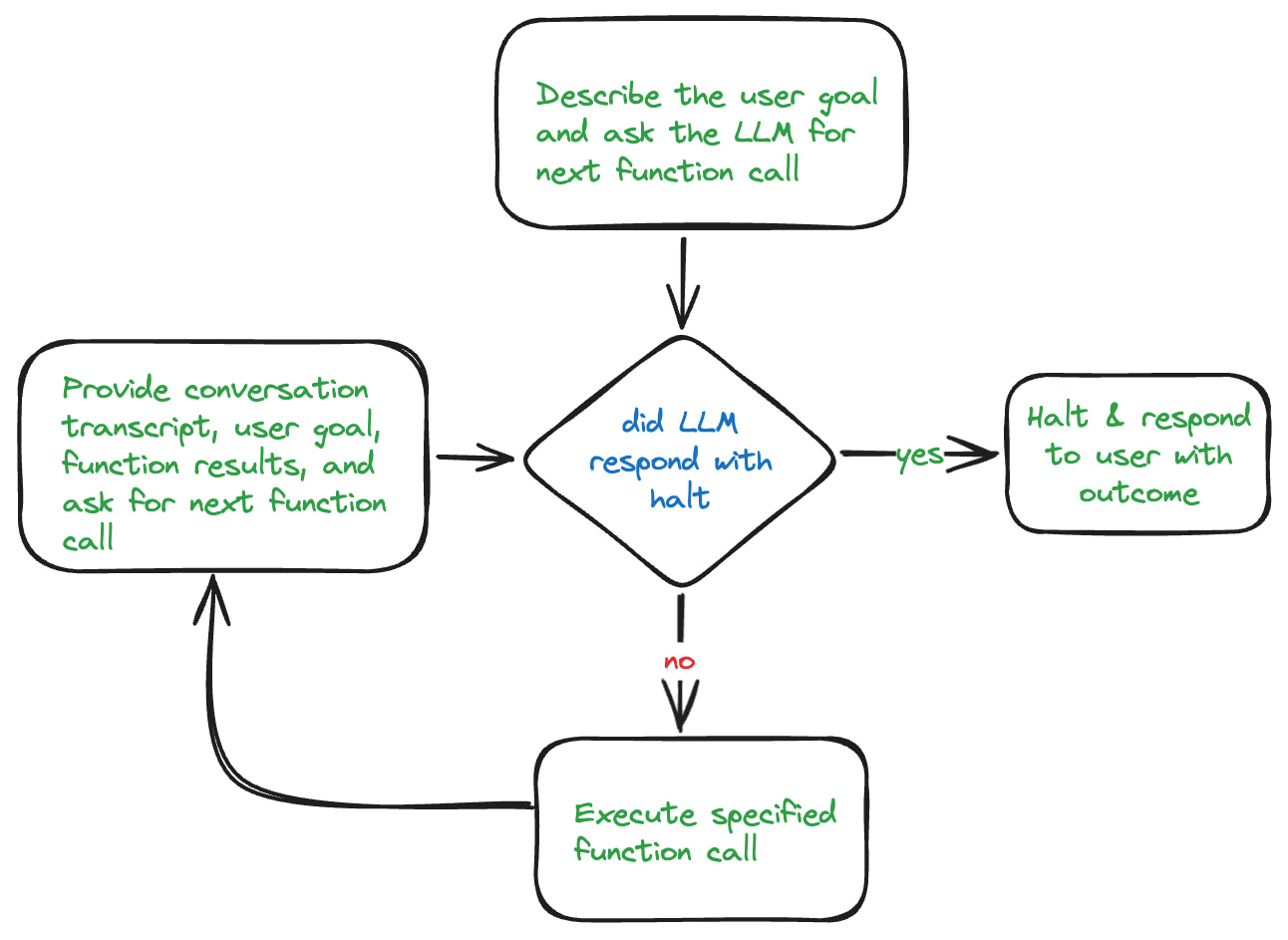
It’s important to note that sometimes the agent may need to give up. This can happen for many reasons. The agent may have exhausted the actions it knows how to take. It may have reached the maximum number of actions it was told it could take to achieve the outcome. It could simply decide that the desired outcome cannot be achieved with the actions it has at its disposal.
Tools and Functions
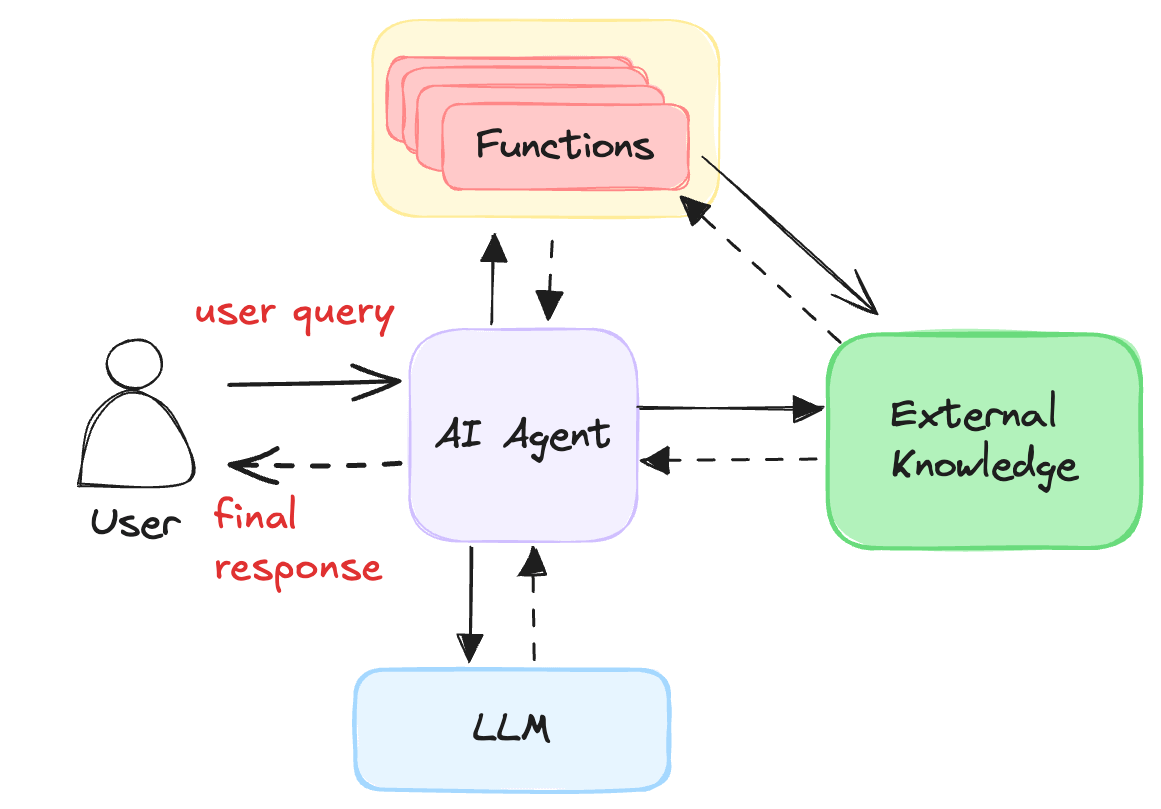
Initially Sherpa has a set of functions that could perform rudimentary order lookups. Then that was combined with calls to perform package tracking. The team built a knowledge base of policies to hand questions about returns and refunds. It then got product catalog information. Then access to the return management system. Then inventory data.
By the time the team shared the details of Sherpa with me, it had access to around 25 API endpoints and 5 search indexes they had populated in their vector database.
Scaling challenges
As I dug deeper into Sherpa’s architecture with the team, they shared more about the challenges they encountered as the AI agent grew. What started as a straightforward agent with basic order lookup capabilities had evolved into something much more complex. That complexity brought significant scaling challenges.
The first signs of trouble emerged as they added more tools to Sherpa’s toolkit. The prompts that told Sherpa how to use these tools grew increasingly complicated. Teaching AI agents how to coordinate between 25 different API endpoints was like trying to write an employee manual that covered every possible scenario. Each new capability multiplied the complexity.
The team found themselves struggling with state management. Even though Sherpa could process large amounts of context, keeping track of where it was in complex multi-step workflows became increasingly difficult. For example, when handling a return request, Sherpa needed to maintain awareness of the original order details, the return policy checks it had already performed, and any customer preferences – all while carrying on a natural conversation.
Quality began to suffer too. The team showed me their test case results, which revealed a clear pattern. As they added more capabilities, the success rate of interactions started to decline. When Sherpa only handled order lookups, they could easily verify its behavior. But now that it was juggling orders, returns, inventory, and customer policies, the number of ways things could go wrong had exploded.
Error handling became another major headache. In early versions, Sherpa only had to worry about one or two API calls failing. Now it was orchestrating complex workflows across multiple systems. If the returns management system went down in the middle of processing a return, Sherpa needed to know how to gracefully handle that failure and keep the customer informed.
Perhaps most frustrating was how difficult it became to debug issues when they arose. When a beta tester complained about a poor interaction, the team had to wade through logs spanning multiple systems to figure out where things went wrong. Was it a bad decision by the model? A failed API call? Inconsistent data? The root cause could hide in any number of places.
At this point, we knew we needed to think about breaking up Sherpa into multiple services.
Monolithic architectures vs Microservices architectures
As with many systems, Sherpa started as a monolithic application all in one code base. From a local development perspective, this was fantastic. We had one thing to build, one thing to run, straightforward dependency management.
Sherpa ran into common monolithic architecture problems. Changes to one part of Sherpa would cause downstream problems throughout the system. We couldn’t test parts of the agent in isolation, and any changes required deployment of the entire system, making updates risky and time-consuming.
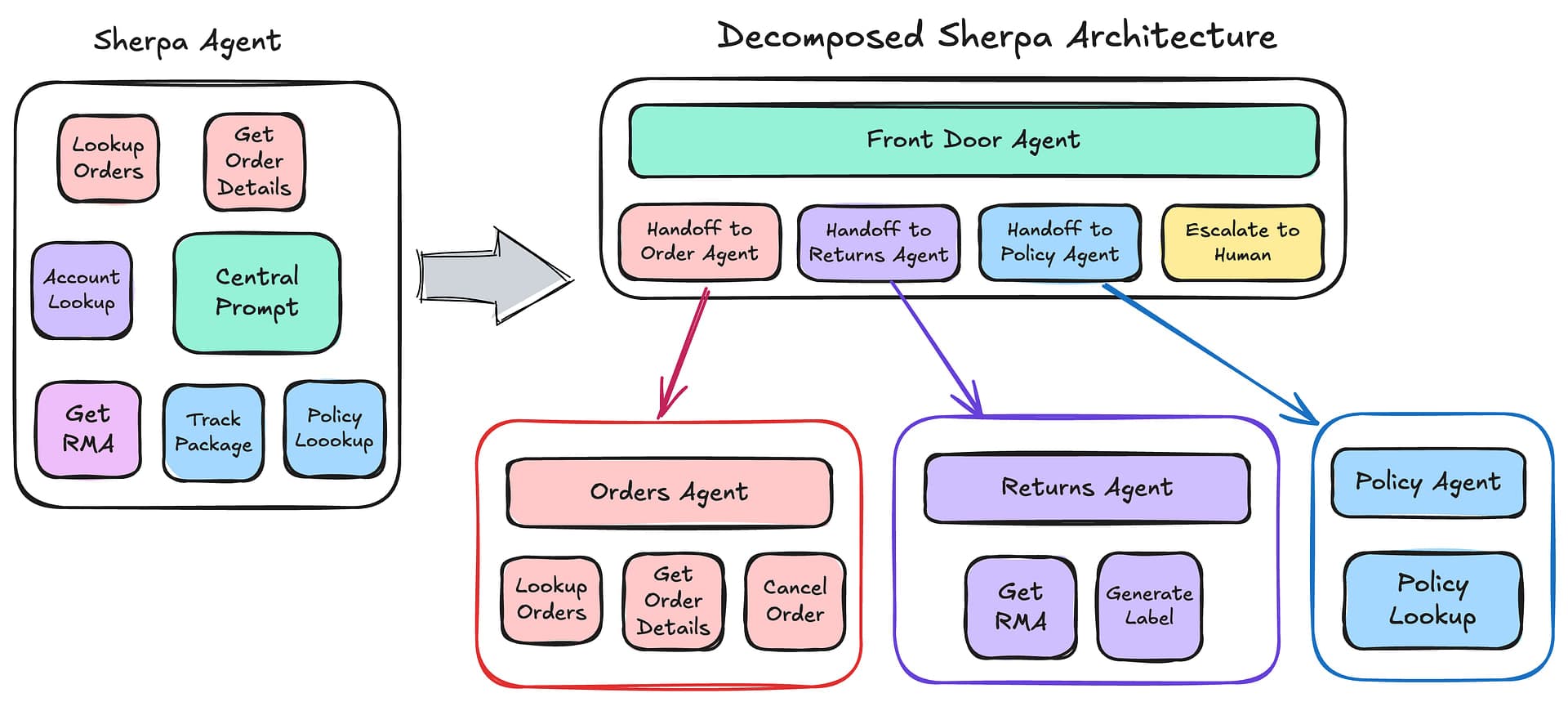
We wanted a better way to architect the system. Our solution was to break Sherpa into multiple “microagents” working collaboratively to achieve the goal. Each microagent service had its own bounded context – a clearly defined responsibility and domain. We designed a system where microservices communicate to dispatch requests to the appropriate microagent service, ensuring each component handled only what it was specialized for.
The goal was to build an architecture of loosely coupled services that could operate independently yet work together seamlessly.
At the same time, we wanted to manage the operational complexity of the system and retain the benefits of a monolithic architecture when testing and running locally. We didn’t want to spin up a Kubernetes cluster or run dozens of Docker containers in order to have a local runtime environment.
Microagents: applying a microservices architecture to AI agents
Breaking Down Sherpa’s Integrations
Sherpa had grown into a complex web of integrations. The agent needed to interact with Shopify’s API for order details, a separate fulfillment system for tracking information, a returns management system for processing refunds, a knowledge base for company policies, and a customer account system. Each of these integrations added more complexity to Sherpa’s prompt and more potential failure points.
We reorganized these capabilities into specialized microagents – smaller services, each with clear responsibilities.
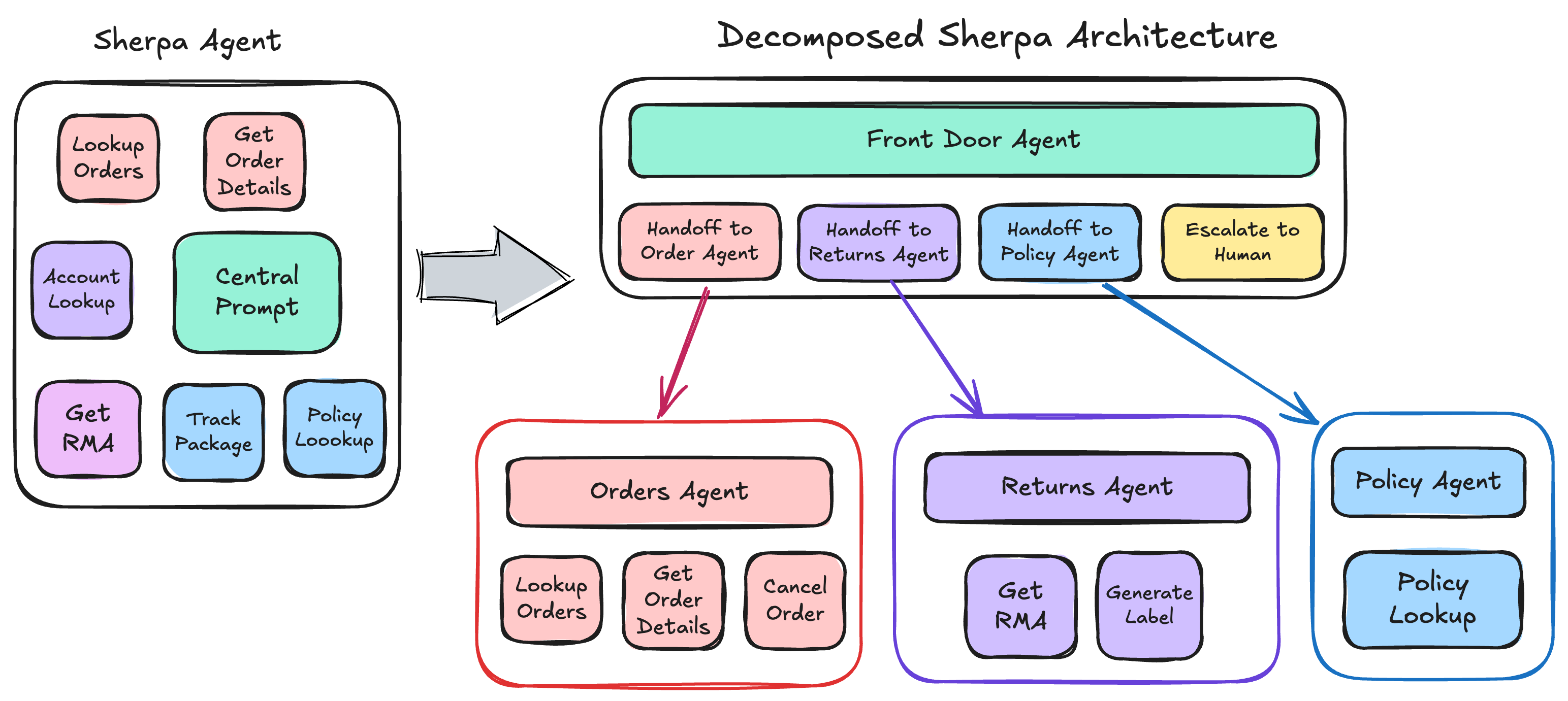
Order Management Microagent
This agent specialized in everything related to existing orders. It integrated with Shopify and the fulfillment system, allowing it to answer questions like “Where’s my stuff?” with deep knowledge of order statuses, shipping updates, and delivery estimates. Instead of teaching one massive agent about every detail of the business, this agent could focus solely on being an expert in order fulfillment.
Returns and Refunds Microagent
Returns require complex logic – checking return windows, processing refunds, generating shipping labels, and updating inventory. This microagent service integrated with the returns management system and handled the entire returns workflow. It could focus on being an expert in return policies and procedures without getting bogged down in other areas of customer service.
Policy and Support Microagent
This agent became our expert on company policies, shipping methods, and general customer service questions. It had access to our knowledge base and historical chat logs, allowing it to provide accurate policy information without needing to understand the technical details of order processing or returns.
Understanding Bounded Context
This concept comes from Domain-Driven Design, and it’s crucial for building effective microagent services. A bounded context defines the specific domain where a microagent service operates – what it’s responsible for and, just as importantly, what it’s not responsible for.
To accomplish this, we had to take a look at the functions that Sherpa was using throughout the AI agent application.
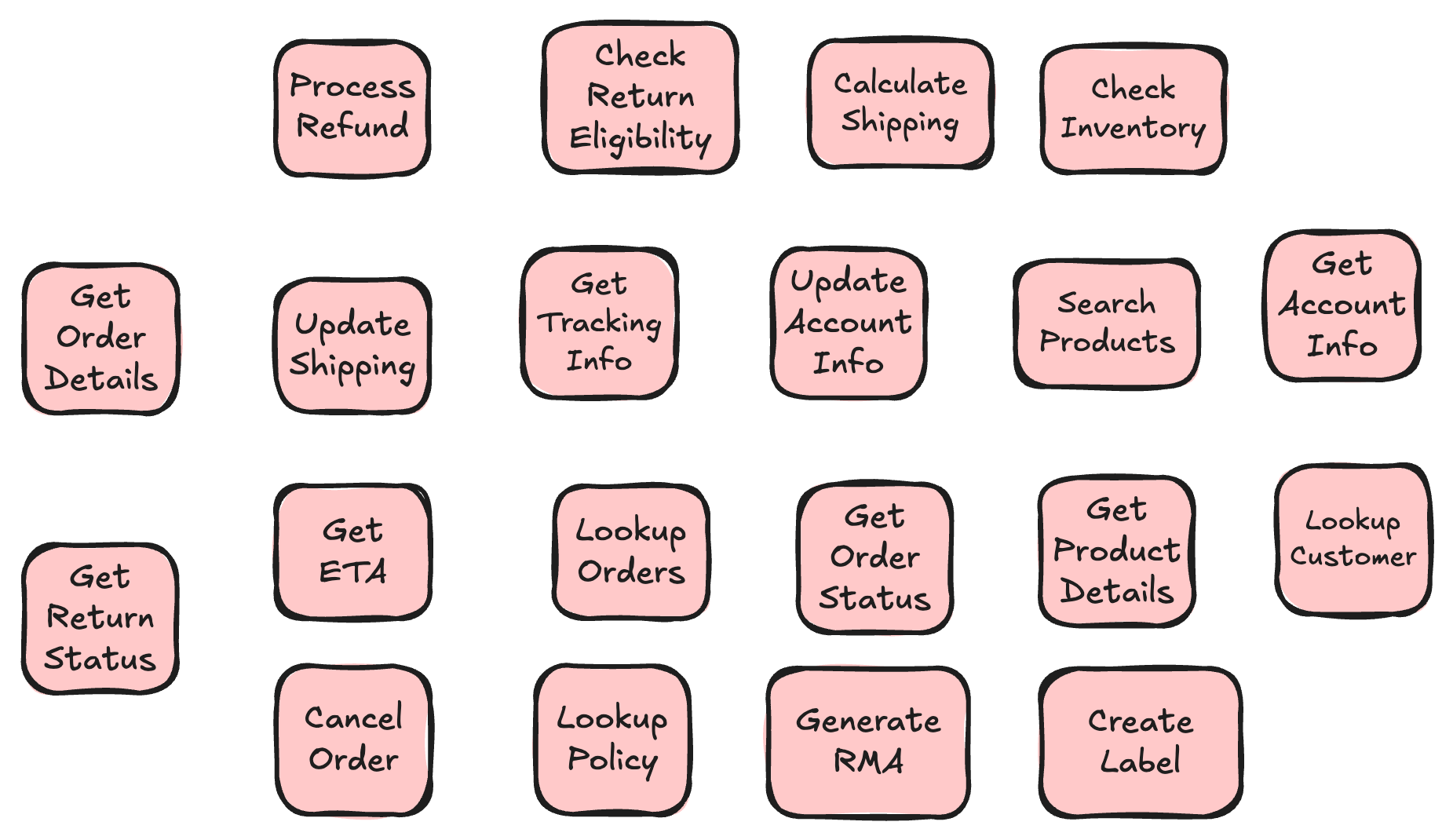
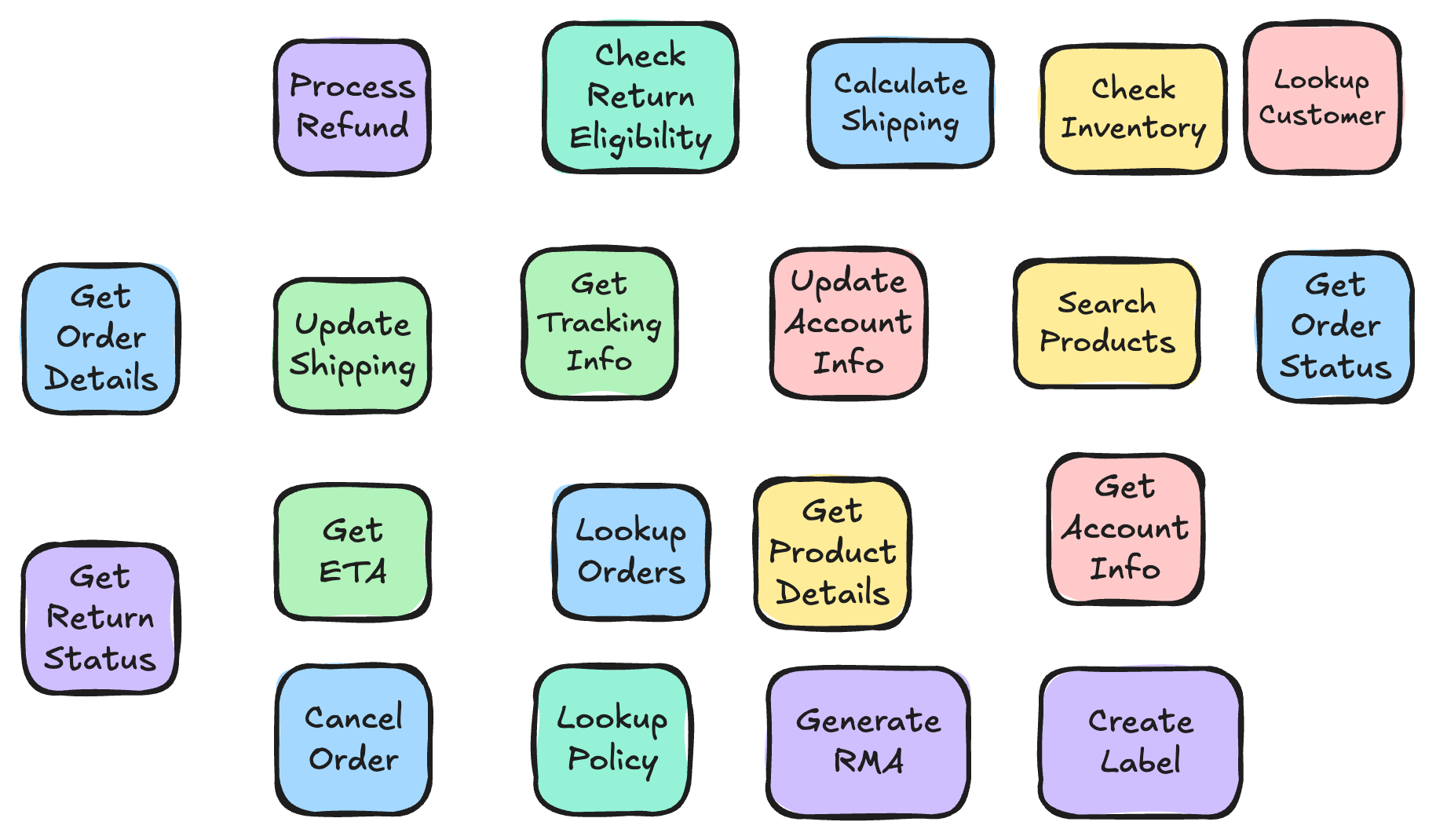
We tried to group similar areas of functionality:
Once we had our capabilities we organized the related functionality into the microagent service that would be responsible for handling tasks related to each functional area.
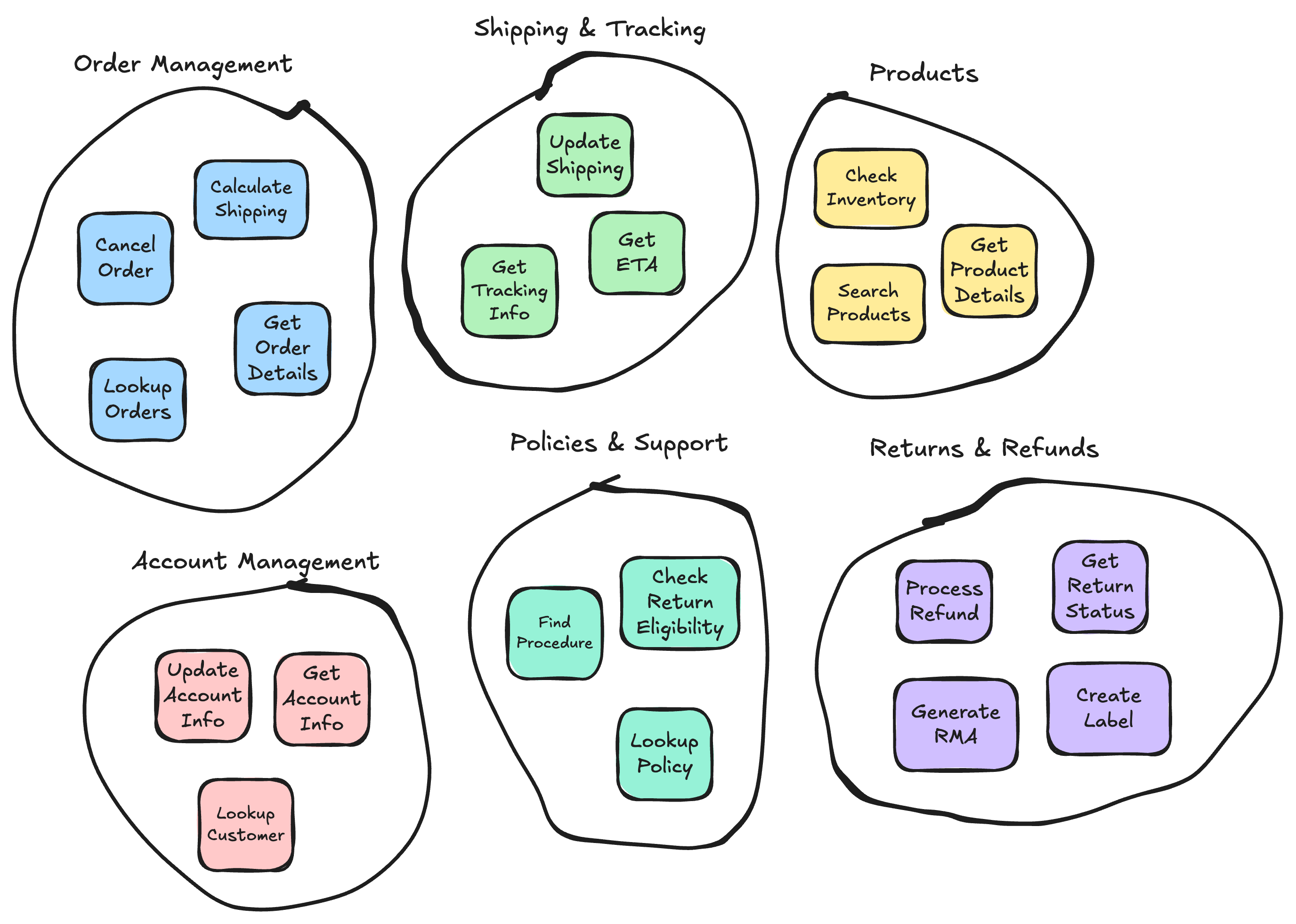
Let’s look at how we defined the bounded context for our Returns Microagent service:
Responsibilities (What’s in context):
- Determining if items are eligible for return
- Processing return requests
- Generating return shipping labels
- Handling refund processing
- Updating return status
Not Responsibilities (What’s out of context):
- Original order lookup (delegates to Order Management)
- General policy questions (delegates to Policy Support)
- Account management tasks
- Product recommendations
Coordinating Between Microagents
Dispatching requests to microagents
In our initial implementation, we deviated from a pure microservices architecture by retaining the mono-repository approach for the codebase. The work that is currently underway seeks to change this in a way that avoids the common headaches associated with a microservices architecture.
The way we are solving this is via configuration that leverages options for both local and remote dispatching.
When running locally, all the microagents are locally dispatched. That is, they work like a monolithic application where hand offs from one agent to the other operate as local function calls in the same local memory and runtime.
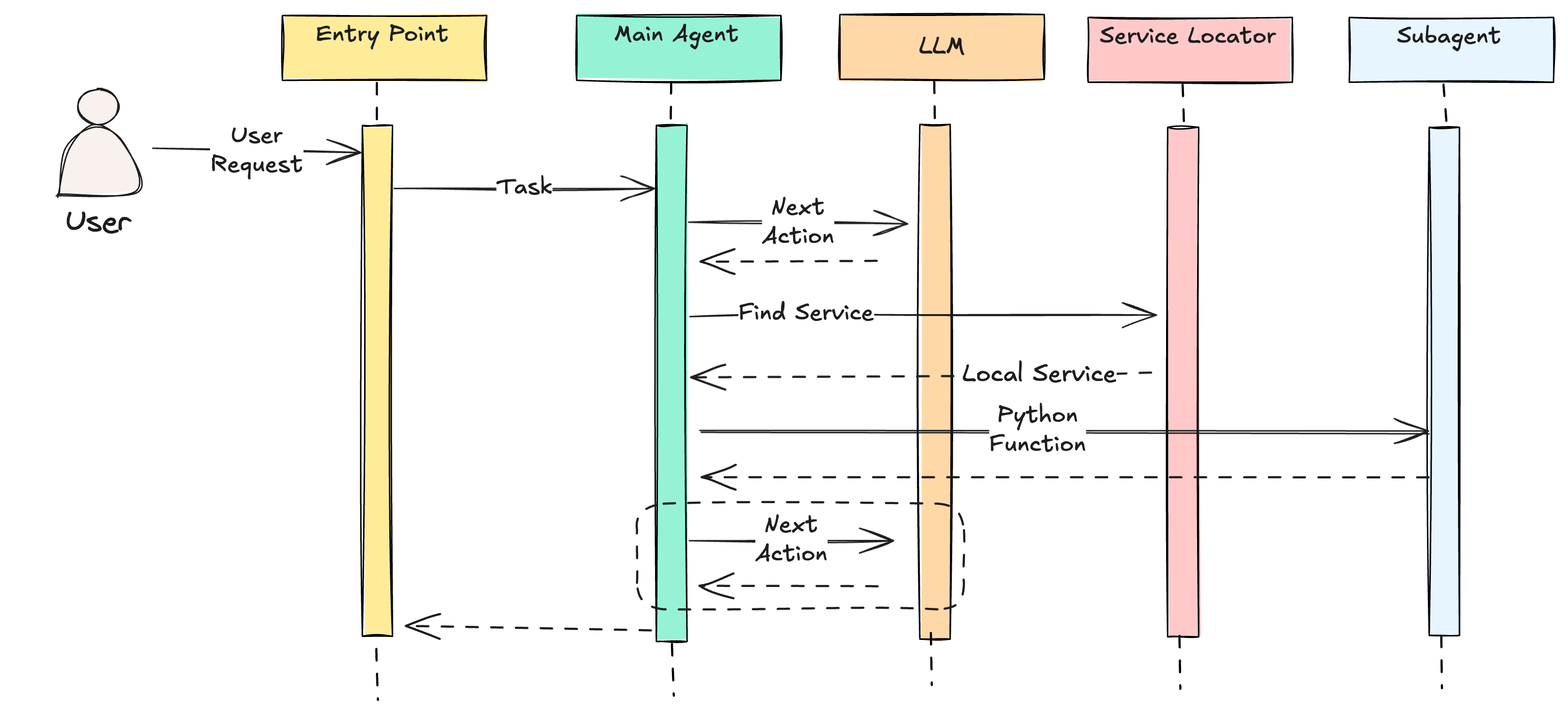
However, when deployed into staging or production, the microagents are deployed independently as separate containers. The service discovery process is managed using etcd.
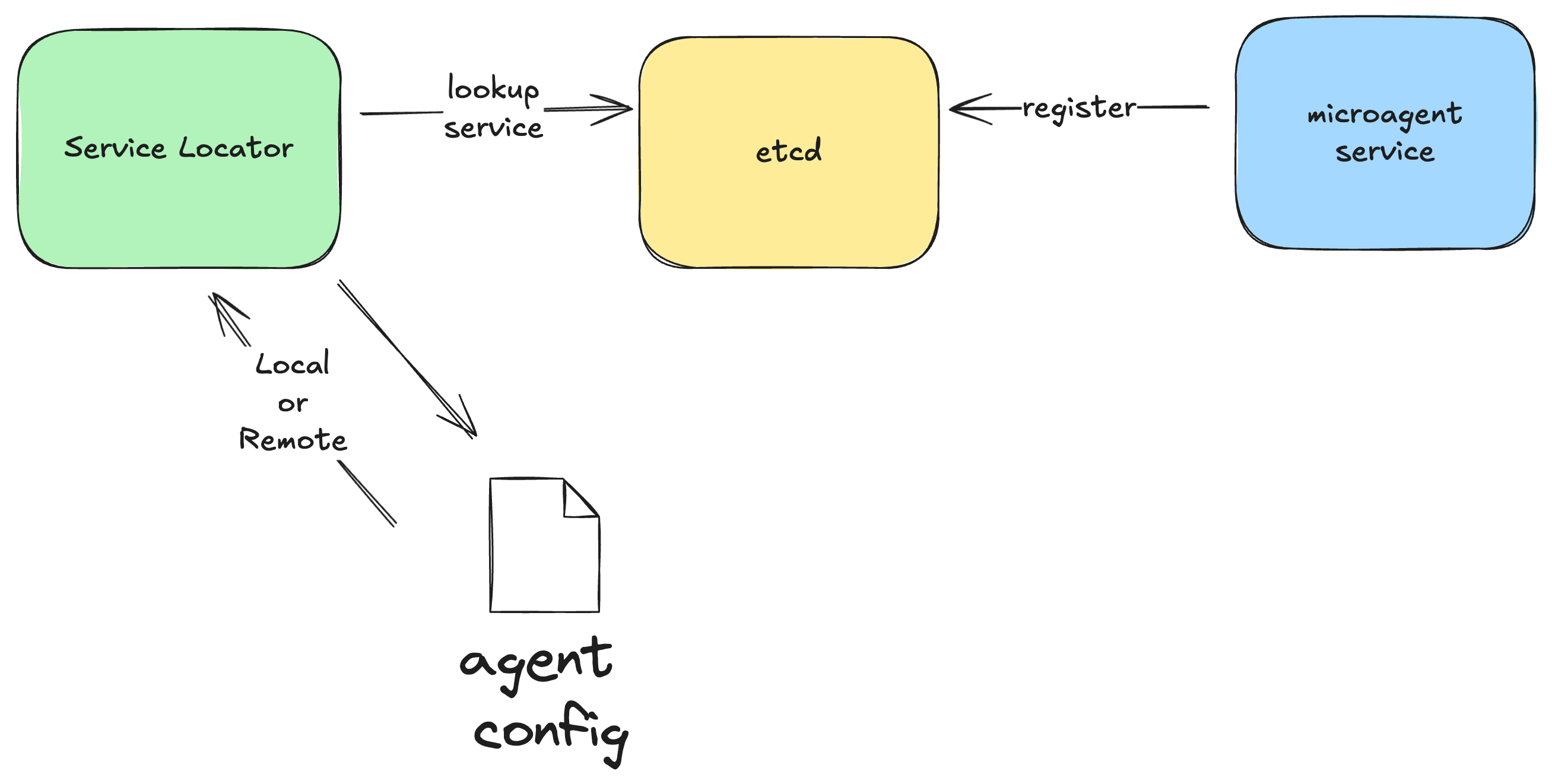
Microagent services register with the configuration management service and a lookup is performed when requests need to be dispatched from one service to another.
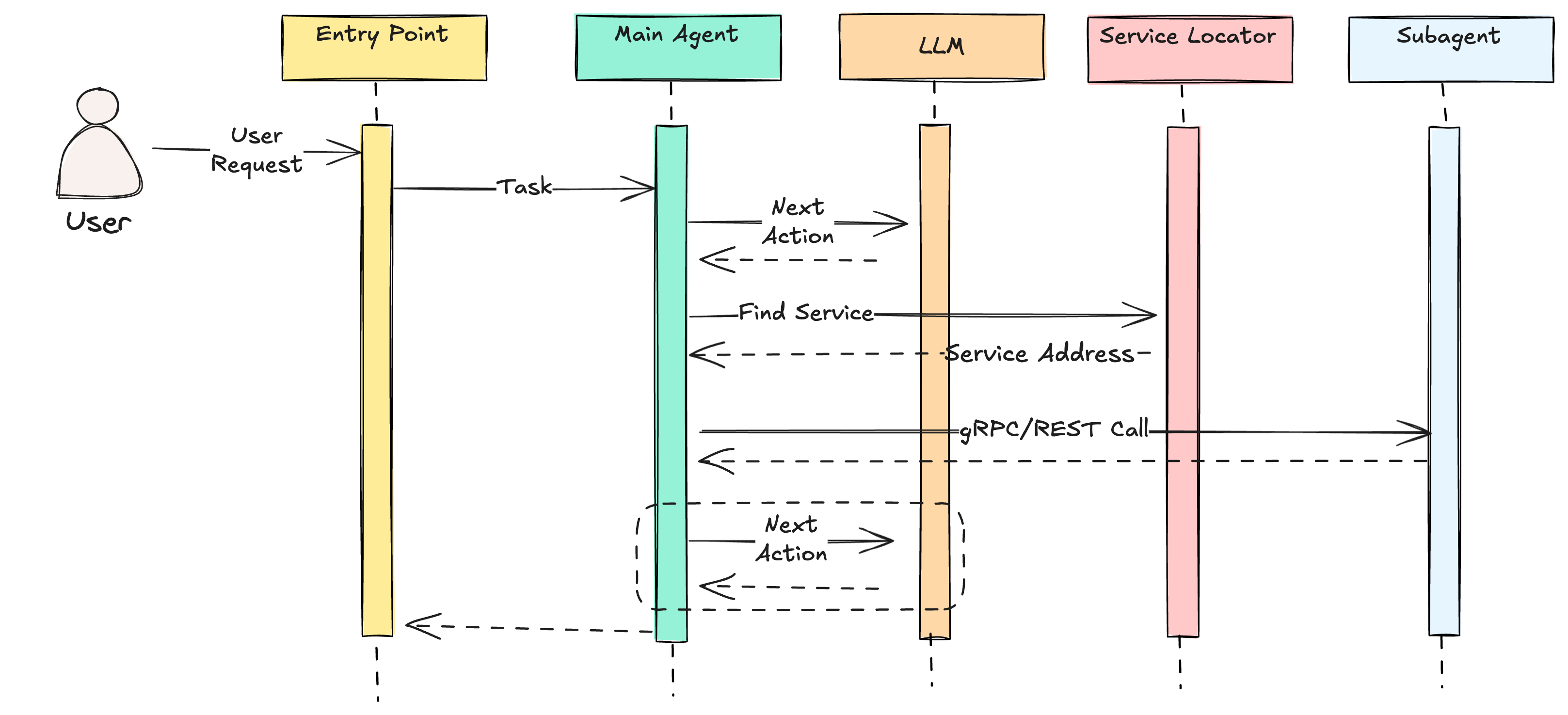
This approach provides a convenient approach to software development where iterations on AI agents can be done quickly in a local runtime environment with improved productivity. At the same time, we can achieve benefits of distributed systems such as services that are scaled independently and deployed independently as new features and new capabilities are ready to launch.
Best practices for building reliable microagents
When building intelligent agents as loosely coupled services, we identified several best practices that help ensure reliability and maintainability:
APIs and Retriever Functions
Almost all agent actions will be implemented as either APIs or retriever functions. Depending on the scale of your system, you’ll need to consider requirements such as using an API gateway for load balancing and security.
APIs for operational data access and manipulation
Each microagent needs to understand not just its computational responsibilities, but its data ownership. Individual services should be self contained and have access to the business rules and other services required to respond to customer queries.
Microservices communicate through well-defined interfaces. With AI agents, additional dimensions of state management introduce additional complexity to service orchestration. For example, your message history may contain results of an initial fetch that was performed earlier in a conversation. Subsequent interactions can result in interactions with lower level agents that must perform data manipulation to accomplish specific tasks.
Data consistency using RAG
When working with unstructured data, one of the main requirements we needed to solve for was data freshness. It took considerable effort to build vector search indexes in the vector database to return the correct context to the agent.
However, as soon as the vector indexes were populated we also needed a way to ensure the data remained fresh and accurate. For this, we used a RAG pipeline using Vectorize:
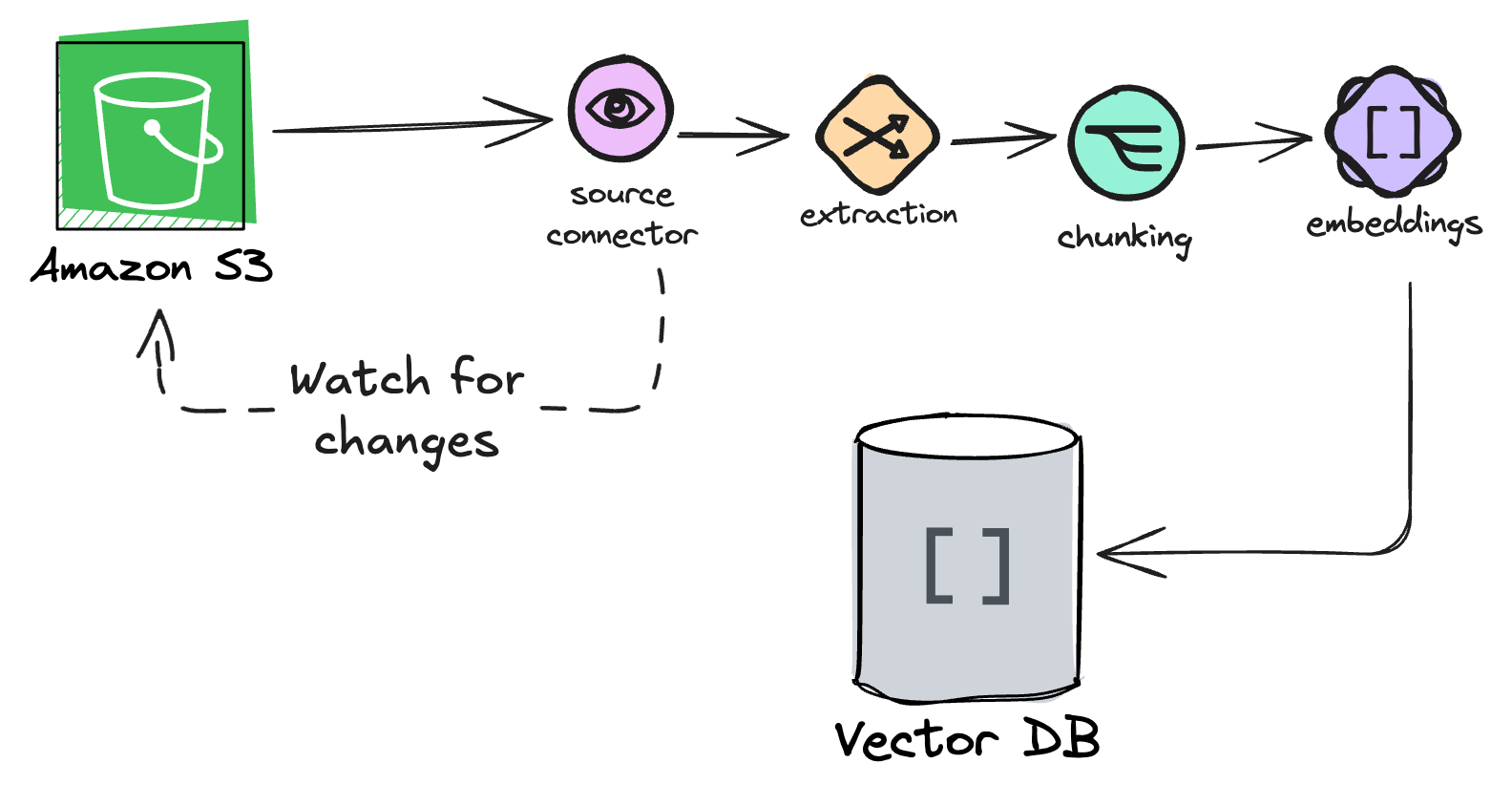
This allowed us to ingest unstructured data and build RAG-optimized indexes. It also let us ensure that the data we retrieved from our indexes was always fresh.
State management across agents
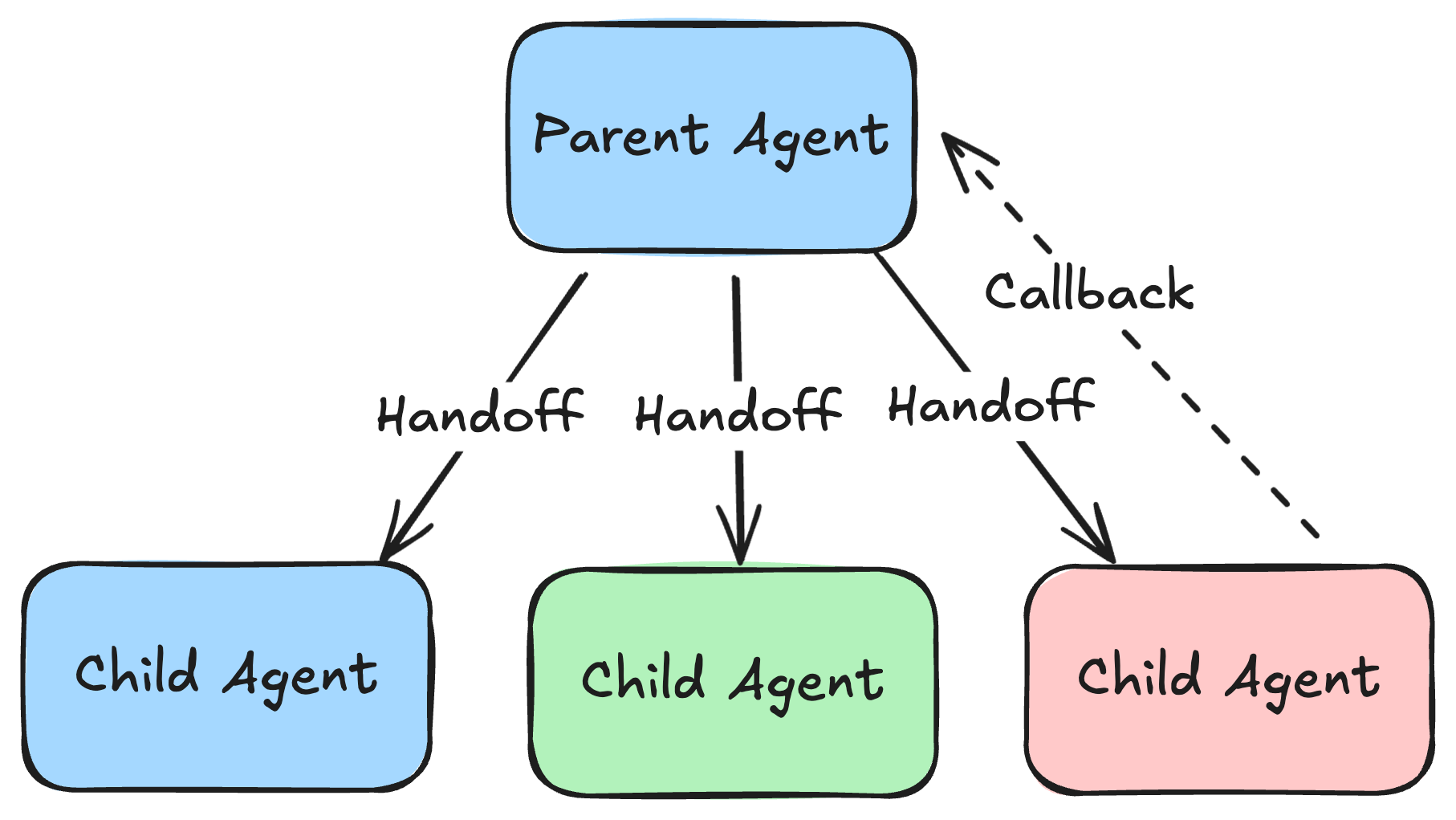
Idealized models often focus on hierarchical agents that dispatch a request from a one service to a child service to accomplish a task. This model works well for goal based agents which are given a task at the start of a process then terminate at the conclusion.
For software applications that are conversational in nature, this becomes more challenging to manage.
Human Intervention and Human-in-the-Loop
Complex tasks sometimes require human intervention. We built safeguards into our AI agents to recognize when they needed to escalate to a human. Each microagent had clear thresholds for when to hand off to human agents:
- Confidence thresholds: If an agent wasn’t confident in its understanding or planned actions
- Policy limits: Certain high-value refunds required human approval
- Edge cases: Unusual situations outside the agent’s bounded context
- Customer escalation: When customers explicitly requested human assistance
Challenges and Limitations of Microagents
While breaking down our monolithic architecture into microservices architectures solved many problems, it introduced new challenges:
- Coordination Overhead: Having services communicate between multiple microagents adds complexity and potential failure points
- State Management: Tracking conversation context across service boundaries requires careful design.
- Testing Complexity: While individual services can be deployed independently, testing interactions between microagents requires comprehensive integration testing
- Performance Considerations: The distributed nature of microagents means accepting network latency and optimizing inter-service communication becomes crucial
Future of Microagents
While there are other frameworks to build AI agents, so far, there are few options for building agents using a microservices architecture in a way that addresses the operating concerns enterprises need.
The initial Sherpa project was mostly based in Node.js. However, the folks at OpenAI had a similar idea they implemented in Python called Swarm. I took that platform and forked it, and updated it to be an LLM-agnostic solution named Microagent.

The idea behind Microagent is to create a lightweight framework for building and managing multiple services that enabled coordinated agent collaboration to delivery AI-driven business capabilities.
The design goals for Microagent are to:
- Create a simplified local development environment for building sophisticated AI agents where all communication and handoffs can happen locally.
- Support distributed deployments of individual microagents as separate containerized workloads that can be independently scaled and updated.
- Provide service lookup and discovery capabilities to simplify service to service communication and handoffs in a distributed systems environment.
- Establish patterns for handling cross-cutting concerns like logging and monitoring across agents
- Offer these capabilities on a permissive open source foundation
If you like the ideas presented in this article, give the Microagent a star on GitHub and track the progress we make as we incorporate many of the approaches discussed here.