OpenAI text-embedding-3 Embedding Models: First Look

Earlier today, OpenAI announced two new embedding models: text-embedding-3-large (v3 Large) and text-embedding-3-small (v3 Small). Interestingly, these are the first embedding models with a dynamic, configurable number of dimensions. By default, v3 Large produces a whopping 3,072 dimension, although you can configure it to use as few as 256 dimensions. v3 Small defaults to 1,536 dimensions – the same as its predecessor Ada V2 – but can be configured to use just 512 dimensions.
My fellow co-founder and I decided to spend the evening testing out these new embedding models. Recently, we have been conducting a bunch of experiments with one of my favorite datasets, the Advanced Dungeons and Dragons (AD&D) 2nd edition rule books, which we decided to use for this effort since we had them handy. Lately, we’ve been spending a lot of time building capabilities into Vectorize that enable users to quickly assess if their unstructured data is well suited to answer the types of questions they expect their users to ask. We’ve built some pretty neat capabilities to produce quantitative scores that tell you just how well your data should perform for a given set of topics when you use various strategies to chunk and vectorize your data. As you’ll see, this work ended up being really useful for this first look analysis.
Qualitative First Look
We started by vectorizing our dataset using a simple paragraph chunking strategy then applying 3 embedding models to these chunks: Ada v2 (1536 dimensions), v3 Small (512 dimensions), and v3 Large (3,072 dimensions). In total we created 6,373 chunks/embeddings for each of these embedding models so do keep in mind that our results may not be representative of what you’ll see at scale – we are only 12ish hours since this was available after all, and this is just a first look.
One quick note on the speed of generating embeddings. Certainly not a scientific assessment, but in our testing we used a batch size of 20 chunks when calling the embedding endpoint. In terms of embedding generation performance, we got predictable results. The v3 Large embeddings at 3,072 dimensions were slightly slower to create and the v3 Small embedding at 512 dimensions were significantly faster to create compared to Ada v2.
| Model | Response time / batch (ms) | % of Ada v2 time / batch |
| Ada v2 | 333.54 | – |
| v3 Large | 367.70 | +8.93% |
| v3 Small | 261.41 | -22.56% |
Once the vector indexes were populated, we used the retriever comparison capabilities in Vectorize to get an intuitive feel for how the results compared for a series of questions and to compare the similarity scores of the retrieved context with the question we were using – this approach is known as (or at least we call it) naive RAG, and it’s not going to produce optimal results for a production RAG system, but since we were more interested in comparing the previous embedding models with the new ones, we felt that was a good place to start.

With this tool, we simply generate an embedding for the search input field, then perform a kANN search on the vector database. In this case, we are using AstraDB from DataStax. The first thing that jumped out at us were the significantly lower similarity scores on both the v3 Small and v3 Large compared with Ada v2. However, this is not necessarily a bad thing. In fact, it’s somewhat surprising from a semantic similarity perspective just how similar the Ada v2 embeddings are compared to the embedding of the search input. Our suspicion here is that the v3 Large embedding model will likely reflect lower overall similarity scores compared to Ada v2 simply because the larger hidden state of the embedding model allows for more subtle differences to be represented. While we somewhat expected the v3 Small model to produce worse results, it seemed to retrieve generally relevant context in this unscientific examination of sample questions we came up with on the fly.
Performing a Quantitative Assessment
I mentioned earlier that one of the key features of Vectorize is the ability to tell you what questions your data is good at answering, then telling you how to best vectorize that data to make it perform well in your applications, especially applications that rely on Retrieval Augmented Generation or RAG.
In the case of our AD&D dataset, the types of questions that Vectorize tells us our dataset is best at answering includes things like:
- Spells and Magic
- Combat and Actions
- Weapons and Equipment
- Creatures and Monsters
- Game Mechanics and Rules
Again, here we leveraged some of the work we’ve been doing around scoring and quantifying how well different vectorization strategies will work to support your use case. One of the metrics we consider is the context relevancy score from the Ragas framework. This score essentially looks at every sentence that you want to provide as context to the LLM (even if you don’t chunk by sentences), then counts the number of sentences that are labeled as “relevant” compared to the total number of sentences passed in as context. Typically, this score is pretty low, so rather than comparing absolute scores we looked at relative context relevancy of the v3 Large and v3 Small versus what we retrieved using Ada v2. This is what we observed:
| Question Category | v3 Large vs Ada v2 | v3 Small vs Ada v2 |
|---|---|---|
| Adventure and Quests | +30.12% | +0.04% |
| Character Abilities and Skills | +16.98% | -46.19% |
| Character and Race | +471.52% | +1285.30% |
| Combat and Actions | -34.03% | -33.88% |
| Creatures and Monsters | +530.37% | +417.49% |
| Creatures and Summoning | -41.58% | -41.88% |
| Dungeons and Environments | +81.34% | +72.77% |
| Environmental Effects | -4.05% | +126.41% |
| Fantasy and Role playing Games | +68.63% | +106.94% |
| Game Mechanics and Rules | +106.63% | -10.42% |
| Locations and Movement | +2.89% | -7.72% |
| Magic Resistance and Saving Throws | -25.14% | +100.62% |
| Magical Items and Artifacts | -16.55% | +9.91% |
| NPCs and Henchmen | -14.19% | -25.57% |
| Player Characters (PCs) and Non Player Characters (NPCs) | +462.08% | +692.13% |
| Spell Effects and Components | -45.32% | -4.30% |
| Spells and Magic | +53.58% | +13.04% |
| Spells and Magic Detailed | -30.44% | -39.51% |
| Tactics and Strategy | -44.20% | -35.47% |
| Weapons and Armory | +58.31% | -27.26% |
As you can see, the results cover the gamut from being amazingly better in some categories and moderately worse in others. Interestingly, even at around a third of the dimensions, v3 Small holds its own against Ada v2 in almost every category, at least in terms of the context relevancy score.
To get a better sense of how they compare, we can remove the outliers and visualize the results here:
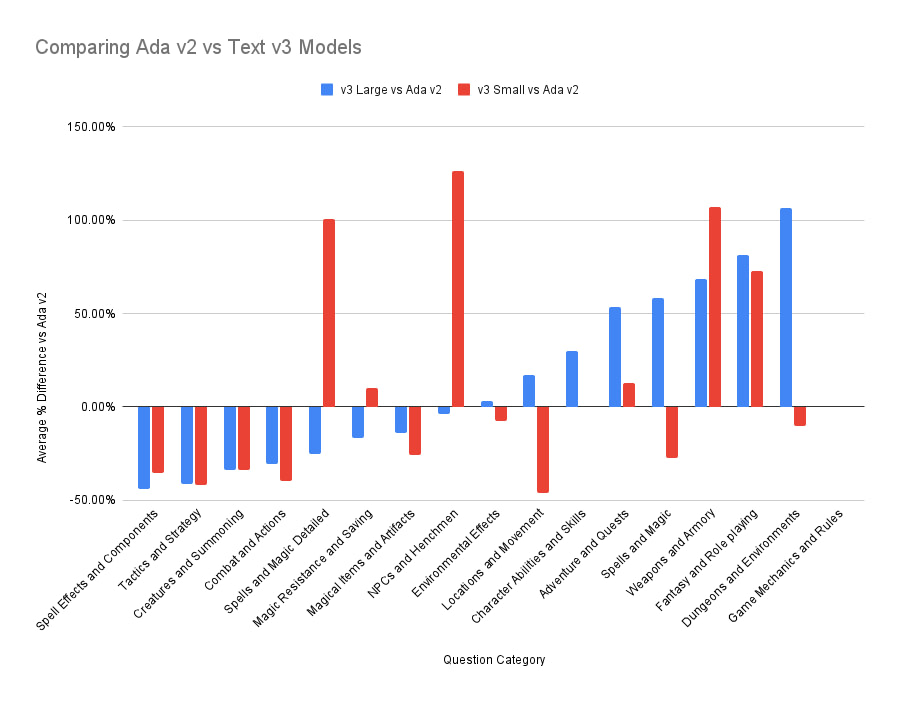
Looking overall at the set of categories analyzed, here’s how each model performed on context relevancy vs Ada v2.
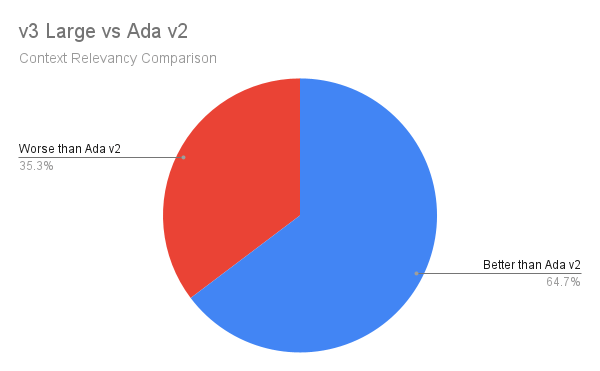
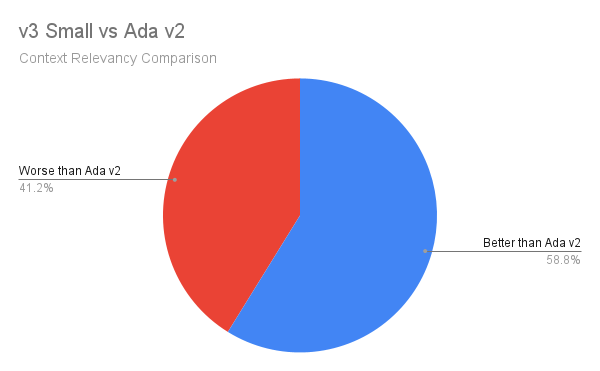
Takeaways
While this is just a first look and certainly doesn’t claim to be a comprehensive tear down or assessment of these new embedding models, it did give some interesting insights into how these models performed in our initial experiments.
Takeaway #1: Matching with our overall experience building Vectorize, bigger is not always better when it comes to embeddings. While v3 Large performed very well overall, it didn’t universally beat out Ada v2 in everything.
Takeaway #2: v3 Small at low dimensions is impressively good considering you’ll spend significantly less on vector storage with most of the vector database pricing models that are out there today, along with the lower pricing from OpenAI.
Takeaway #3: Just because an embedding model performs very well on benchmarks, that doesn’t necessarily mean you will see the same amazing performance in your real-world RAG application. This observation was one of the key insights that led us to start working on Vectorize in the first place!
If you enjoyed this post and would like to try out Vectorize for yourself, our waitlist is now open! We’d love to talk to you about how Vectorize can help you build production-ready gen AI applications quicker.
We’re just starting off as a company, so if you would follow us on LinkedIn that would mean a lot to us as well!