Picking the best embedding model for RAG

What are text embedding models?
Text embedding models are a type of machine learning model that are used heavily in the domain of natural language processing. These models typically accept a text input and convert that text into a numerical representation that encodes the semantic meaning of the text. Embedding models were instrumental in early machine learning use cases like sentiment analysis, classification and summarization just to name a few.
Increasingly, embedding models are finding themselves in the spotlight as more developers start to build generative AI and other artificial intelligence features into their applications. These developers typically discover techniques such as retrieval augmented generation (RAG), which relies heavily on semantic search to identify relevant context which in turn helps large language models (LLMs) to reduce hallucinations and provide higher accuracy responses to user queries.
Using RAG, developers can leverage an LLM to generate text on topics that are completely outside of its training dataset.
How are embeddings used in retrieval augmented generation (RAG)?
Let’s start by walking through a simple example of how RAG works and along the way we will highlight the role of text embedding vectors before diving deeper into selecting the model that will work best for your particular use case.

For this example, let’s imagine that we have a “chat with our docs” application. Because we are releasing new versions of our product on a regular basis, pre-trained foundational models like GPT or Gemma or Mistral will usually lack the latest product details in their training dataset. Therefore, we can use RAG to provide the LLM with the missing context data and help it create higher quality outputs that can assist users in understanding how to use our product.
Step 1: User Submits Query to LLM
This use case starts out like most interactions with an LLM, by the user submitting a prompt.
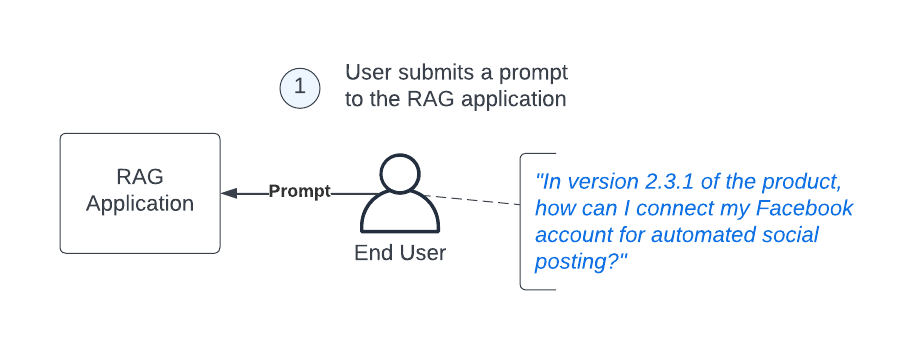
Here you can see that our user is asking how to connect their Facebook account to our fictional product, however instead of asking this directly to the LLM, we have application logic that will first enhance the prompt before making the call to the LLM.
Step 2: RAG application generates query vector and performs similarity search
In the simplest approach to RAG, the application will use the user’s query to perform a semantic search to retrieve relevant search results, often using a vector database.
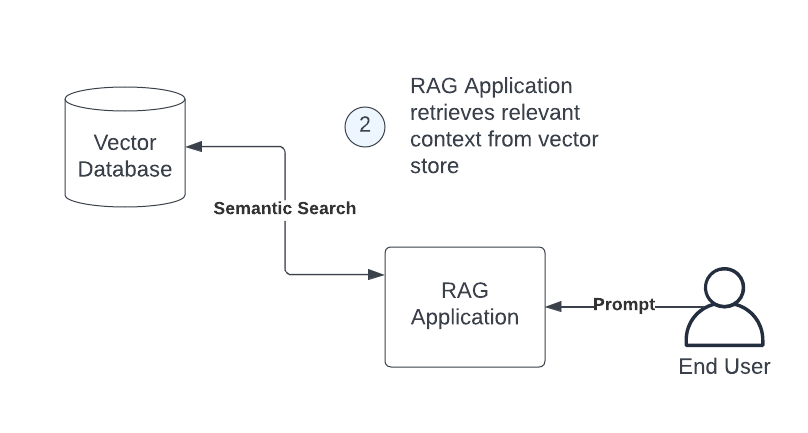
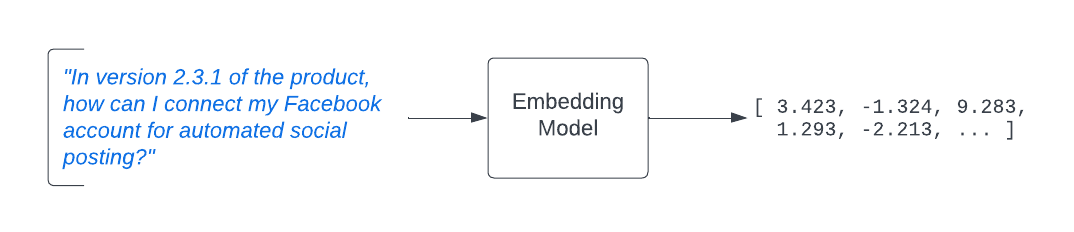
In order to perform this semantic search, the RAG application will use an embedding model. The embedding model will take the text from the user’s prompt and it will produce an output vector called an embedding.
The application then submits a short query to the vector database. The vector database identifies similar documents by comparing the vector input, also called a query vector, against the embedding vectors in the appropriate search index. It does this by using a distance metric, such as cosine similarity (most common) or dot product, to measure the similarity between the documents it has in the indexed dataset and the query vector being used to search embeddings.
This overall process is known as an approximate nearest neighbor search and is the most common approach used by vector search engines. This approach to semantic search is a useful technique to allow applications to get more relevant search results compared to alternative methods like full text or keyword searches.
Step 3: RAG application augments the prompt using semantic search results
In this step, the RAG application uses the context it retrieved in step 2 to produce an augmented prompt. Using a basic form of prompt engineering, the RAG application takes the original prompt then injects the context along with any other guidance the app wishes to provide.
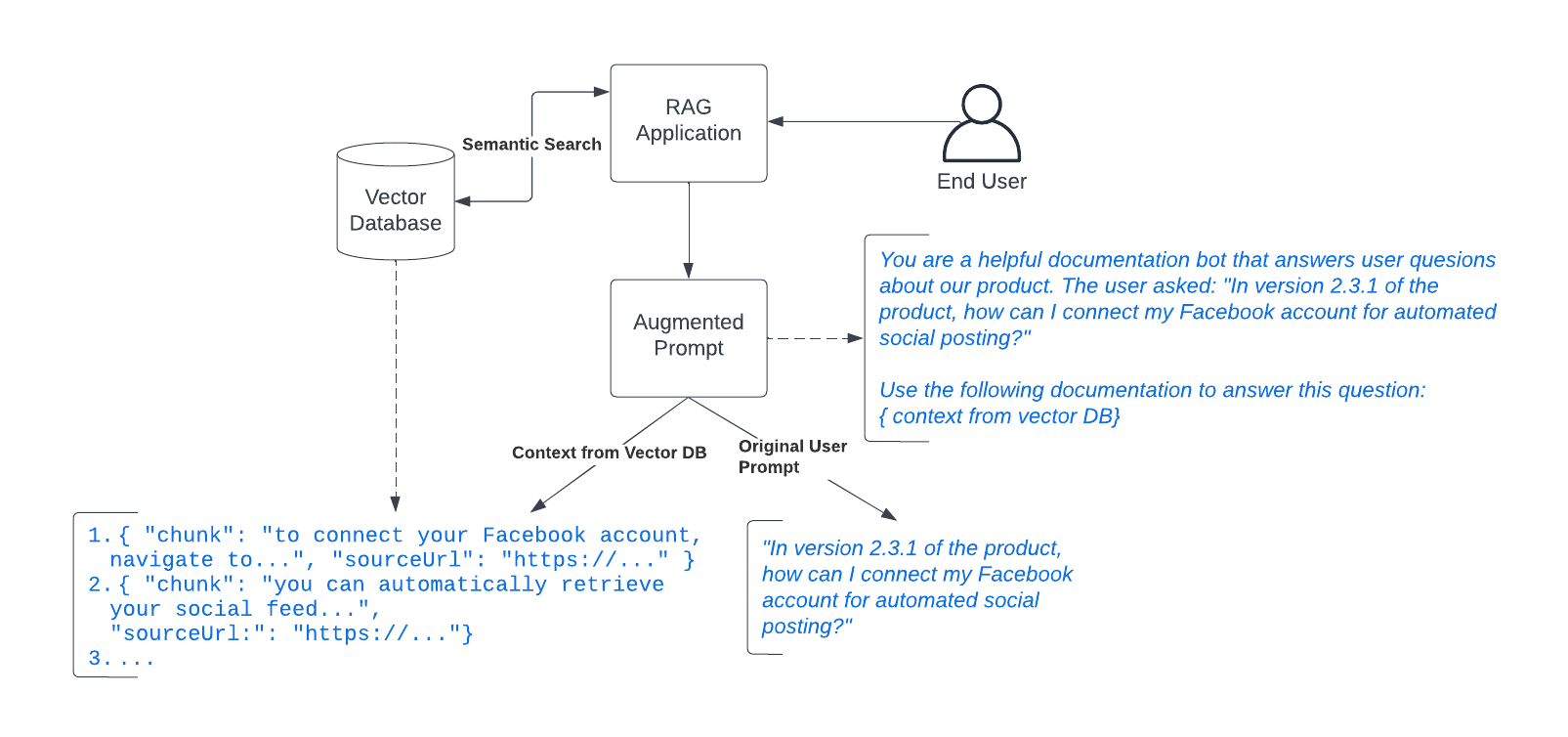
Once the augmented prompt is created, it is then passed to the language model to generate a response.
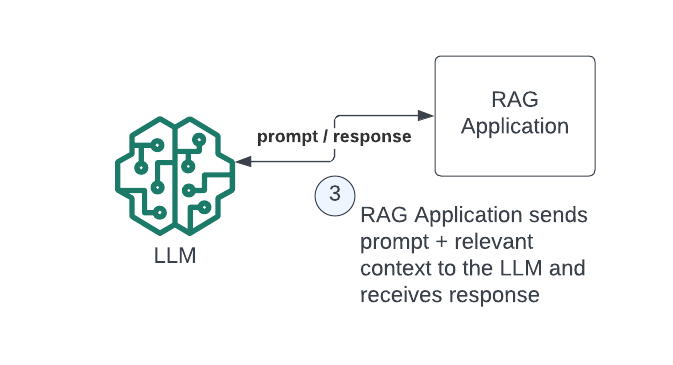
Step 4: LLM generates a response based on the augmented prompt
Here the LLM responds to the prompt, which now takes into account the additional contexts which were supplied to it in step 3. This allows the LLM to provide information about the new release of our product even though its training datasets didn’t include any documents about this version. That’s kind of amazing when you think about it!
Choosing the best embedding model for your application
Hugging Face MTEB leaderboard
Most developers have one of two default ways to decide which embedding model to focus on. They either use one of OpenAI’s embedding model options because they are using one of the GPT language models.
The other popular approach is to start exploring the MTEB leaderboard. This is a great resource to see at a high level how various models perform on specific sets of standardized benchmark tasks.
These benchmarks cover a range of tasks and datasets. Some involve sentiment analysis of sentences extracted from comment threads on discussion forums. Others perform comparison analysis on question and answer pairs trying to identify the most correct option from a set of possible answers. Some of these benchmarks relate more to traditional use cases such as the ability of sentence transformers like BERT to assess phrases.
In retrieval augmented generation (RAG), you’ll want to focus on benchmarks that center on retrieval use cases. The distinction for these benchmarks is that they aim to measure the performance and quality of a model’s ability to identify the most relevant document or documents in a dataset. Examples may include identifying the best article from a corpus of news columns, or performing a search to identify the document with the closest semantic match within a large set of documents within an example dataset.
Most commonly you will find embedding models that are trained to only understand English words and phrases. However, there are specialized models that focus on other languages and some offer a multilingual version as well. Additionally, there are even models that are trained to create embeddings from software source code.
The challenge with text embedding model benchmarks
While benchmarks are a good starting point, it’s very common that the performance of a model in a lab setting will vary considerably from the performance you will experience in the real world. The solution to this problem is to perform your own experiments to assess the differences between models and see which ones produce the best accuracy and similarity scores in your app.

Key performance metrics to consider
Context Relevancy (CR)
The idea behind a CR score is to assess how much of the context that you are providing in your augmented prompt is relevant to answering the query submitted to the LLM. This score is calculated by evaluate each of the words in the prompt using a natural language processing model to determine if the word is relevant or not. Low CR scores can be a sign that you are not providing enough information to help the LLM answer the user query with grater accuracy.

There is often a trade off between chunk sizes and the CR score for data returned from a semantic search query. Larger chunks often contain irrelevant information, which can sometimes actually improve the accuracy of results since the LLM have a greater contextual understanding to incorporate into the generation process. At the same time, larger chunks can also cause LLMs to struggle when deciding which part of the chunk to pay attention to. For this reason, CR can be useful in determining whether your semantic search produces useful information, it is not always the case that higher scores equal higher accuracy.
Normalized Discounted Cumulative Gain (NDCG)
NDCG is a metric that has long been used in search engines to determine if the search result data is useful and relevant for the query submitted by the user. Compared to CR, NDCG will tell you if the search result data returned is relevant and also how well the results are ranked. It is often used in information retrieval to measure the overall quality of search results.
Using Vectorize to make a data-driven decision
You can certainly write your own code and create a script that chunks a sample of the data you intend to use for semantic search in your RAG application. Open source frameworks like Ragas offer tools to assess the overall quality of the embedding models you want to compare.
However, this process is time consuming both to create the embeddings as well as to build logic to analyze the data to determine which option gives you the best results. If you would rather get perform these assessments in minutes with almost zero effort instead of over days with a lot of effort, you may want to consider trying the Vectorize free experiment tool.
Data driven experiments
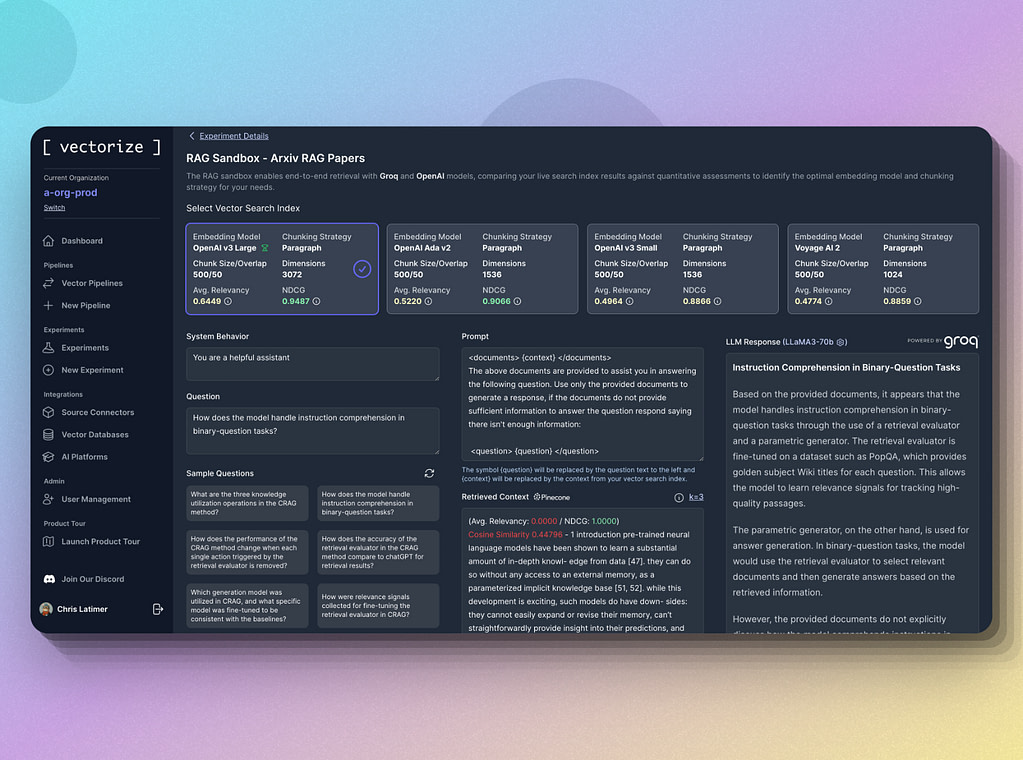
Vectorize provides a frictionless tool for comparing the performance you can expect from a set of embedding models and chunking strategies using a representative sample of your data.

Experiments will execute a vector pipeline to parse your unstructured data, generate embeddings, build a search index using either Pinecone or AstraDB as the vector database engine and will then provide a quantitative assessment of which vectorization strategy will be optimal for semantic search capabilities in your RAG application.
Qualitative and collaborative assessments using the RAG Sandbox
It’s always a good idea to verify the quantitative view with your own personal experience. The Vectorize RAG Sandbox allows you to chat with your experiment data. You can ask the LLM one of the questions that get generated as part of the experiment, or submit a question of your own. You can also invite additional team members to your Vectorize organization so you can get early feedback from your users before you ever write a line of code.
With Vectorize you can take the guess work out of building relevant, accurate RAG applications and you can get it done in a tiny fraction of the time.
Conclusion
Embedding models are an essential component for any RAG application and there are many to choose from. The unique characteristics of your data and your use case may produce different results than those from benchmark datasets.
If you want to see how well different embedding models perform on your data, sign up for a free Vectorize account now. In less than a minute, you can have concrete data showing exactly how well different embedding models and chunking strategies perform and ensure your RAG applications will always have the most relevant, accurate context.