5 RAG Vector Database Traps and How to Avoid Them

Retrieval Augmented Generation (RAG) and Vector Databases
For developers that are building generative AI features, retrieval augmented generation is becoming the standard way to connect external knowledge bases to the large language models (LLMs) that are powering their applications.
Increasingly, developers are discovering that the best way to handle the retrieval part of RAG is with a vector database. On paper, this process is simple. You populate your vector database with your most relevant documents. You query that database using a similarity search. The database returns back relevant documents or parts of those documents. You then give that context to your LLM, and get back better, more accurate responses from your LLM.

Easy right? Well… Often that’s not the case. And one of the most frustrating experiences for an AI engineer is to build a RAG application, wire everything up, and then discover things aren’t working as you’d like. The LLM produces hallucinations, users are frustrated by their poor results, and you’re left to troubleshoot the problem, which is no small feat given the non-deterministic nature of these systems!
How Do RAG Models Work? Architecture Overview
To understand where things can go wrong, we need to start by examining the various steps we need to go through to create a fully working retrieval augmented generation (RAG) solution. The end state of a RAG application will usually look something like this:
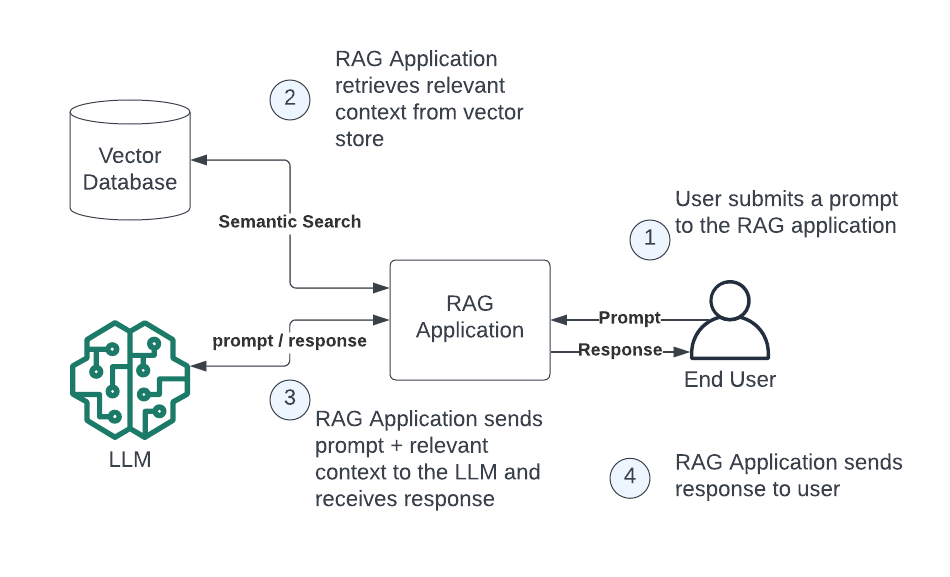
If you aren’t familiar with the basics of RAG architecture, you should read our very thorough introduction to retrieval augmented generation, for a more complete overview.
In order to build out this RAG application architecture, there are several key steps we need to complete before our application is fully functional. It is very easy to make a mistake in any of these steps that can torpedo the overall effectiveness of your RAG architecture. To start, though, let’s explain what the steps are and how to go about building out your LLM tech stack.
Extracting relevant documents from source systems
Depending on the application you’re building, your large language model may need context that lives in file systems, SaaS platforms, traditional databases, or in a knowledge base. This extraction process can be accomplished in a number of ways such as via one-off scripts to parse PDF files in python using a library like PyPDF2 or PDFMiner.

You may also need to integrate with knowledge bases or SaaS platforms using their APIs. This can be time consuming to build these integrations, but can ensure your RAG application has all the relevant context it needs from across your organization.
Chunking documents
Whether you are working with PDF documents, wiki pages you retrieved from a knowledge base like Atlassian Confluence or Notion, or account notes from Salesforce, you will need to decide how you want to store those documents in your vector database.
Retrieval augmented generation relies heavily on vector search. When you perform a similarity search against your vector database, the ideal query results would be the exact information that the language model needs to respond to your prompt.

Generally speaking, this means you want to vectorize smaller chunks rather than massive ones. For example, pushing a 300 page document into the context window of your large language model will often produce worse results than if you had broken that document up into page-sized or paragraph-sized chunks.
Creating vector embeddings
Chunking and vector embeddings are closely related. You will most often use your document chunks as the input into a text embedding model. An embedding model is a specialized type of machine learning model. The output of these models is a vector which encodes the semantic meaning of the text you supplied to the model.
Vectors are just arrays of floating point numbers. This means we can use standard mathematical techniques such as cosine similarity and dot product as distance metrics to power semantic search. This allows the vector database to identify chunks from the most similar documents by comparing the distance metric between the search input query vector that is passed in to the vector search request, and the vector representations that are stored in vector indexes within the vector database. In short, we can perform approximate nearest neighbor searches to retrieve the most relevant context to the LLM.

Embedding models are generally created one of two ways. Either they are open source machine learning models that are distributed as python libraries you can download and run from GitHub or Hugging Face. Or, they are proprietary models that can only be created via REST API calls to a web endpoint. Both have their advantages and disadvantages and you can use either option to generate vectors that will work very well for vector search and within a retrieval augmented generation architecture.
Populating the vector database
Different vector databases have different interfaces you can use to populate them. Modern cloud native vector databases like AstraDB, Pinecone, and Zilliz all have REST APIs along with lightweight libraries that wrap the API for popular languages like TypeScript and Python.
Likewise, more established databases which have vector support such as MongoDB and PostgreSQL will use their existing libraries and/or binary drivers to persist vector data and facilitate vector search queries.

From an actual vector persistence standpoint, most of these offerings are going to behave in pretty similar ways. You need to know ahead of time how many dimensions each of your vectors will have. Newer vector databases will use search indexes as their primary data types while more traditional relational and NoSQL databases will use tables or documents with vector-specific data points within these structures.
The important role of metadata in vector search
Metadata is important for primarily two reasons. The first is that if you expect the number of vectors in a vector index to grow large, the “approximate” part of approximate nearest neighbor gets worse and worse.
If your vector database is able to return the top 3% most similar vectors when you perform a semantic search, that’s will be fine when your vector indexes have 100 or 1,000 vectors in them. However, if you expect that you might have a million vectors, then that 3% now encompasses that top 30,000 most similar searches which can be pretty darn different.

Most popular vector databases are able to improve the relevant information that gets retrieved in these high volume similarity search use cases by supporting metadata filtering. Metadata filtering is essentially a pre-filtering step that is used to narrow down the set of vectors to search when you submit a vector search query. This can greatly improve both the speed and accuracy of the retrieval process, since there are fewer vector embeddings that need to be compared in order to identify the relevant knowledge to return.
The other reason metadata is important is because in retrieval augmented generation (RAG), you will often want to surface key information about the chunks that get returned such as the document location, unique identifiers, and other metadata.
Hybrid search and traditional search engine capabilities
While vector databases excel at performing semantic search, increasingly developers are combining vector search with more traditional full text keyword search in an approach known as hybrid search.
Certain platforms such as OpenSearch, Elastic search and others offer a specialized database that supports multiple query options and even lets you specify the mixture of vector similarity search and keyword search results that you would like to return.
Refreshing your document vectors
Once your vector database is initially populated with vector embeddings you can sail away happily into retrieval augmented generation paradise, right? Well, unfortunately no. Even if you have achieved a high performing RAG application, your vector database starts to get stale almost immediately, especially if its sourced from a SaaS platform.

When building your RAG architecture, you must not just consider the initial population, but also have a strategy for keeping vector data fresh.
The Five Common RAG Vector Database Traps
Now that we’ve deconstructed the typical data ingestion process that you must implement to build solid vector search capabilities to power your RAG applications, let’s take a deeper look at the mistakes that many developers and companies make along the way.

Trap 1: Using the wrong chunk size
If you create poorly sized chunks, you will have a difficult time retrieving the most relevant information to power your retrieval augmented generation (RAG) applications. As an extreme example, you could imagine that a sentence-chunking strategy would often return very similar responses, especially for prompts that contain only short input query strings. However, those chunks that come back in the return data from your vector search won’t be particularly useful to help the LLM provide a relevant, accurate response.
Likewise, if you use chunk sizes that are too big, your query may return chunks that cover several pages of text from a document. If your query parameters indicate you want to get back the top 10 most similar vectors, you may end up with low context relevancy.

In these cases, the context provided to the large language models include the information needed to generate an accurate answer, but your language model may struggle to hone in on the signal through the noise and produce the result you want.
For this reason, it’s often best to rely on either a semantic chunking approach which allows you to capture longer passages of related text.
Semantic chunking has the downside that it relies on natural language processing to identify the semantic breaks. This often involves machine learning libraries which tend to be more computationally expensive and slower than alternative techniques.
Recursive chunking is often used to create vector embeddings from a given piece of text, then provides context before and after that text to capture any relevant context that surrounds each snippet.
Trap 2: Picking the wrong embedding models
The starting point for most developers when picking a model is usually the Hugging Face massive text embedding benchmark (MTEB) leaderboard. For retrieval augmented generation use cases, the machine learning models which score best on retrieval benchmarks will be the ones that are best suited for RAG applications.
However, there are a number of considerations and trade offs you need to think through as you’re selecting an embedding model as well. Many of these models were specifically designed to perform well with the benchmarks’ original training data.

In some cases, the machine learning models that perform best on the benchmarks, may be somewhat overfit for these lab-environment tests, but may not perform as well in real world use cases for you and your specific data. For this reason, it’s important to take a data driven approach to evaluate which embedding model performs best on metrics such as Context Relevancy and Normalized Discounted Cumulative Gain.
Trap 3: Not designing your metadata
Vector databases are well suited to provide both core vector search capabilities as well as metadata filtering. However, many developers are so focused on generating vectors and storing data that they forget that their user query often requires retrieval of metadata as well the embedding data.
Your metadata design should take into account any anticipated partitioning keys that can narrow down your search query as well as relevant details from your knowledge base that you want to get back when you perform a vector similarity search.
Trap 4: Building fragile vector data pipelines
There are many mature, battle tested data engineering platforms in the market, but most of these excel at working with structured data. Common RAG applications like chatbots that answer a user’s question in human like text, or recommendation systems that generate recommendations from knowledge base data, rely much more heavily on unstructured data.
However, building vector ingestion pipelines from knowledge bases is fraught with many of the same potential points of failure as traditional structured data pipelines. API calls to generate embeddings can fail, leaving you with a half populated vector index. Your vector database can have an outage or timeout along with many other common failure conditions.

Building resilient data integration capabilities is particularly challenging for RAG systems because many of the go-to tools we reach for for more traditional data engineering solutions – solutions which have advanced retry and error handling capabilities built-in – aren’t well suited to handle either the unstructured data sources needed for RAG models or the vector generation and persistence capabilities needed here either.
For this reason, you will need to find a specialized product, like Vectorize, that is purpose built to support robust data engineering requirements on vector data pipelines, or take care to build these into integration scripts you build on your own.
Trap 5: Letting your vector search indexes get stale
Stale vector data can turn great generative AI systems into useless systems in short order.
Imagine that you’ve build a RAG application that uses an LLM to provide natural language processing capabilities on top of your company’s Salesforce data. You’ve generated vector embeddings for customer data, sales opportunities, and customer meeting notes.

However, you also have sales reps who are continuously updating Salesforce. This means that your RAG application might give great answers about how your deals looked when the vector database was first populated, but each new query strays farther and farther from the truth.
As you are building your integrations into your vector databases, you want to take care to ensure you are prepared to handle new data as it becomes available. You also want to consider the freshness requirements that you need for your given use case.
Avoid these traps with Vectorize
It should come as no surprise that Vectorize was built to solve many of these common challenges for you out of the box, in many cases using only our free tools!
Data driven decisions with experiments
You could spend days writing scripts to populate various vector indexes with different embedding models and chunking strategies. You could write your own tests to score how well each combination performs. You could crunch the number and try to get a quantitative assessment of which option works best for you and your data. You could do that… OR!
You could save yourself days of writing code and run a few experiments on Vectorize and have this information in minutes.

Experiments let you run multiple models to generate text embeddings and different chunking strategies in parallel. First you provide a representative sample of your data in the form of PDFs, text files, HTML, or other files. We then generate a set of canonical questions that your data would be best suited to answer. We help you identify if the data you have will support the use case you are aiming to solve, and we tell you definitively which vectorization strategy is going to produce the most relevant context.
The end result is that you no longer need to rely on guesswork and gut feel when deciding on the optimal approach to populate your vector databases.
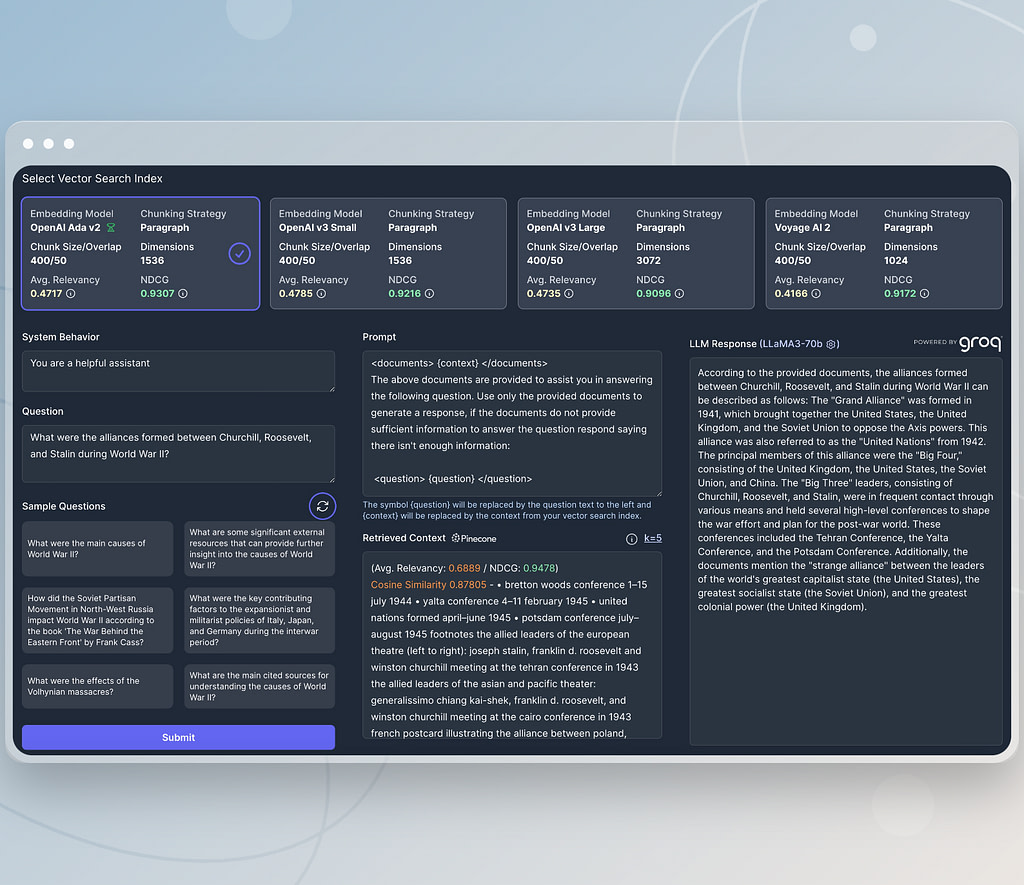
Qualitative, collaborative assessments with RAG sandbox
Data is great, but it’s often helpful to validate quantitative assessments with actual real world experience. The RAG sandbox lets you chat with your experiment data. You can select the vector index you want to use, pick your LLM and submit queries to see how well they perform in your experience. You can invite teammates to try it out with you and compare notes. This can help you pick the right strategy with the best price/performance characteristics for your situation.
Production-ready vector pipelines
Vectorize is built on top of a distributed, real time streaming platform. It’s the same technology which is being used in mission critical enterprise applications across the globe. Operated on a cloud native architecture built on Kubernetes, Vectorize vector pipelines give you the out of the box integration capabilities to connect to unstructured data sources and well as vector databases with all of the data engineering best practices built-in.
If you want to build better AI apps faster, try Vectorize. Our platform helps you quickly evaluate and optimize your vector data, boosting RAG performance without the usual headaches. Start for free, pay only for what you use, and see results in minutes. Ready to improve your AI? Sign up now and see the difference.