Triumph Over Data Obstacles In RAG: 8 Expert Tips

Introduction
Retrieval-Augmented Generation (RAG) has emerged as the de-facto architecture in building apps with LLMs. RAG enhances the LLM by integrating external data, enabling more comprehensive and accurate responses. However, to harness the full potential of RAG systems, it’s crucial to navigate and overcome some data challenges that are inherent in this technology.
In the following sections, we will discuss some common data-related challenges when building LLM RAG applications, along with strategies to overcome them:
1. Data Extraction
Challenge: Parsing complex data structures, such as PDFs with embedded tables or images, can be difficult and require specialized techniques to accurately extract relevant information. As of today, OCR (Optical Character Recognition) is still largely an open problem, especially when dealing with scanned complex documents like invoices.
Strategies:
- Start simple: start with a text only data pipeline whenever possible. If your RAG system cannot perform well on text data then chances are it will not perform well on images and audio.
- If your data contains PDF files, then invest in a good parsing tool. A very common document recognition method would be to segment the problem into subproblems of lower complexity. For example: if you are building a RAG to read medical invoices, then you may use an OCR tool for specific key fields like: total amount, tax amount etc and if needed use advanced visual models (GPT4 vision works great with complex PDF documents for examples).
- Worth noting that Microsoft Azure probably has the best pre-built document recognition/understanding tools for enterprises (product name: Document Intelligence).
2. Handling Structured Data
Challenge: LLMs are great at dealing with unstructured data, such as free-flowing text, but not that good at handling structured data, like tabular data for example. Many issues arise when trying to use LLM over tabular data, including a high rate of hallucination. My advice is that you avoid using LLMs on tabular data altogether whenever possible. If that’s not a choice, then:
Strategies:
- Transform tabular data to unstructured text. You have to be careful with:
- Numerical Representation: Traditional tokenization methods, such as Byte Pair Encoding (BPE), split numbers into non-aligned tokens, complicating arithmetic operations for LLMs. Newer models, like LLaMA, tokenize each digit separately, improving the understanding of symbolic and numerical data.
- Categorical Representation: Excessive columns in tabular data can lead to serialized input strings that exceed the context limit of LLMs, resulting in data pruning and performance issues. Poorly represented categorical features, such as nonsensical characters, can also hinder LLM processing and understanding.
- Employ techniques such as the chain-of-the-table approach, which combines table analysis with step-by-step information extraction strategies, enhancing tabular question-answering capabilities in RAG systems. https://blog.gopenai.com/enhancing-tabular-data-analysis-with-llms-78af1b7a6df9
3. Choosing the Right Chunk Size and Chunking Strategy
Challenges:
Determining the optimal chunk size for dividing documents into semantically distinct parts while balancing the need for comprehensive context and fast retrieval. Longer contexts lead to longer inference time (try Gemini 1.5 pro with 1M context tokens!), and smaller context chunks might lead to incomplete answers.
The other major challenge around chunking is the chunking strategy, meaning should you chunk based on sentences? paragraphs? word count? etc
Strategies:
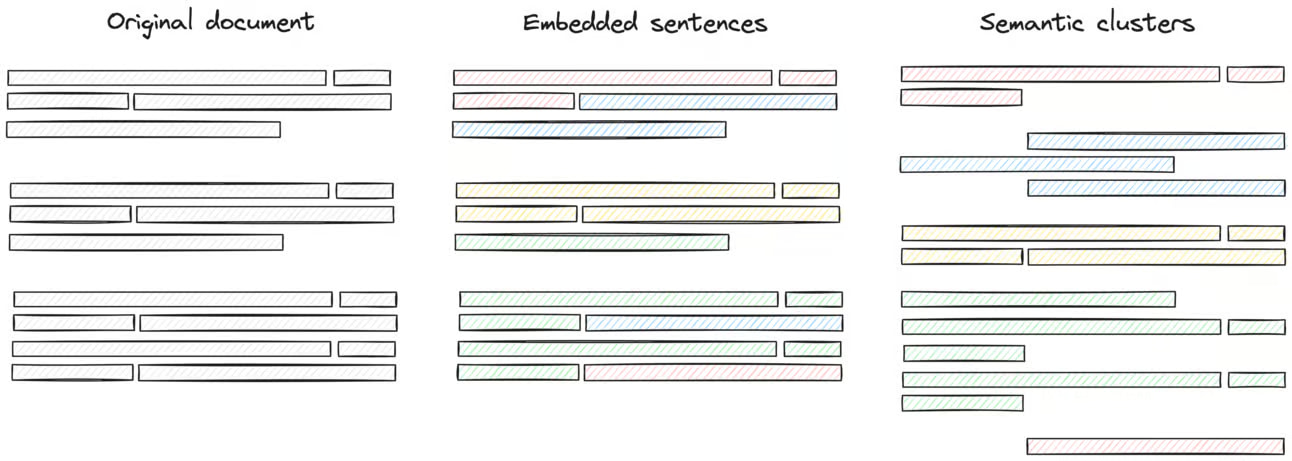
- Again, start simple and iterate: pick a simple chunking strategy first, run evals, measure everything, I talked more about chunking strategies in this newsletter post: https://heycloud.beehiiv.com/p/text-splitting-chunking-rag-applications
- Chunk size should follow the chunking strategy not the opposite, meaning: first you determine the strategy you want to follow, then you determine the chunk size considering both your strategy and the LLM context size. For example: if your data is a collection of news articles, then the paragraph-level chunking would likely work, and since the context size of most LLMs is larger than one paragraph, then you can afford a variable chunk size which is the size of a paragraph.
4. Creating a Robust and Scalable Pipeline
Challenge: Building a robust and scalable RAG pipeline to handle a large volume of data and continuously index and store it in a vector database. Most RAG app builders have this part as an afterthought, which makes sense as your first goal is to make something that works. However, if you know you app will eventually have to handle TBs of data per hour, then you may have to design the whole app with that in mind.
Strategies:
- Once again, start simple 🙂 I think you got the memo by now!
- Try to estimate the scale of your app early on, even though you don’t need to act on this information from the beginning.
- If needed, adopt a modular and distributed system approach, separating the pipeline into scalable units and employing distributed processing for parallel operation efficiency.
- Use battle-tested tools to deploy your app, like kubernetes. The good thing about Kubernetes is that you can scale up and down as needed. For example, if you need a periodic cron job to clean newly fetched data, then you can schedule it and be sure it will disappear after the job is done, saving you compute and money.
5. Retrieved Data Not in Context
Challenge: The RAG system may retrieve data that is not relevant or does not provide the necessary context for accurate response generation. One of the common reasons for this is: bad embedding, bad user query, context truncating etc
Strategies:
- Use query augmentation/rewriting to enhance user queries with additional context or modifications, improving the relevancy of retrieved information. An excellent example of query rewriting is how Cursor.sh does it.
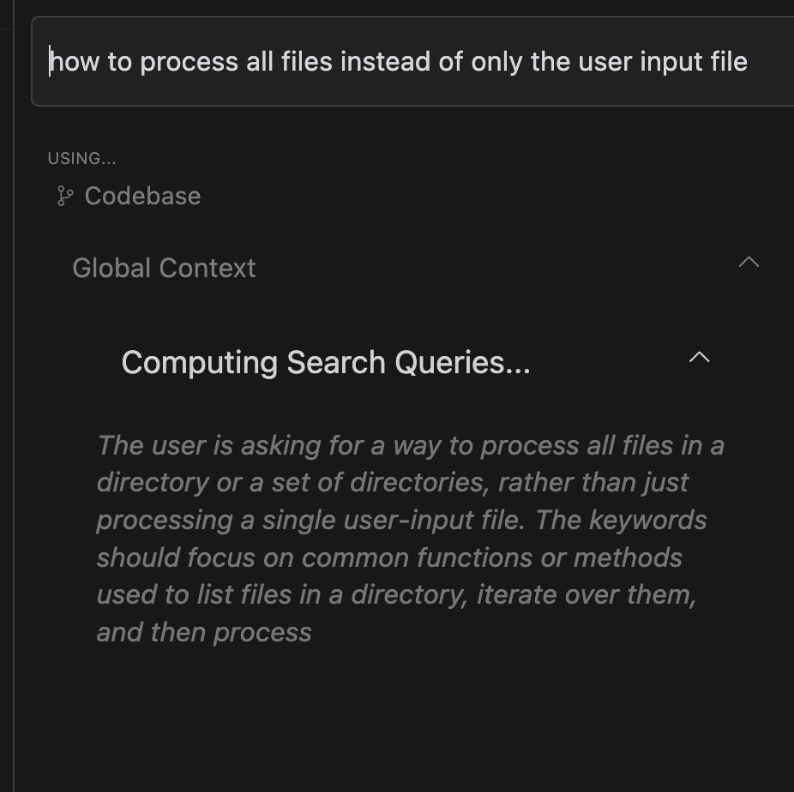
- Explore different retrieval strategies, such as small-to-big sentence window retrieval and semantic similarity scoring, to incorporate relevant information into the context.
- A more advanced trick would be to use generative UIs to clarify user intent. For example, you could reply to the user’s query by asking to clarify it to ensure the retrieval engine retrieves the complete context to then answer the query. Morphic.sh is a good example of an answer engine using dynamically generated UIs for user query clarification.
- Invest in a monitoring solution to visualize prompts, chunks and responses.
6. Task-Based Retrieval
Challenge: RAG applications should be able to handle a wide range of user queries, including those seeking summaries, comparisons, or specific facts. Hence, handling all user queries with one retrieval prompt might not do the job.
Strategy:
- Implement query routing to identify the appropriate subset of tools or sources based on the initial user query, ensuring adapted retrieval for different use cases. Routing usually involves creating multiple indexes and a classifier. The classifier could be a small and cheap LLM classifying the query and routing it into the corresponding index.
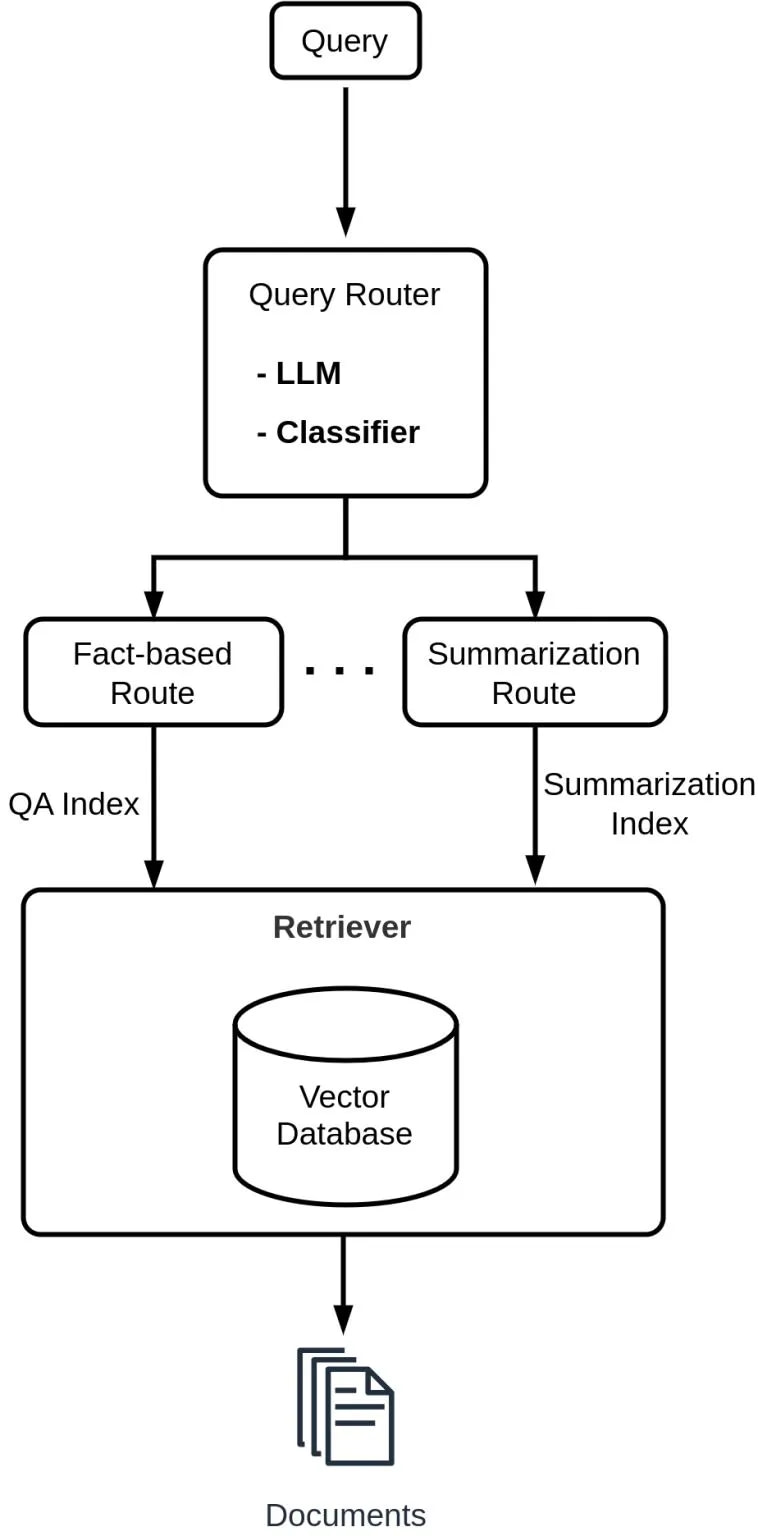
Souce: https://mlnotes.substack.com/p/adaptive-query-routing-in-retrieval
7. Data Freshness
Challenge: Ensuring that the RAG app always uses the latest and most accurate information, especially when documents are updated.
Strategies:
- Implement metadata filtering, which acts as a label to indicate if a document is new or changed, ensuring the app always uses the most recent information.
- Like in “Ensuring data is in context”, a more advanced trick would be to use generative UIs to clarify user intent around recency. For example, you could answer the user query by asking to clarify if the user is asking about recent events or general events etc.
- In some cases, LLMs confuse their internal learned information about dates and external data timestamps, hence it is important to be explicit in the prompt about which to use.
8. Data Security
Challenge: Ensuring the security and integrity of LLMs used in RAG applications, preventing sensitive information disclosure, and addressing ethical and privacy considerations. I wrote here about security threats that one should consider when building RAG applications. In summary:
Strategies and considerations:
- Implementing multi-tenancy to keep user data private and secure is one of the most important mitigation strategies.
- Properly handle the user prompt to ensure it does not abuse the LLM.
- Analyze the RAG data for any signs of data poisoning.
Conclusion
Data is the central piece of any RAG system. Issues with the data may render your RAG system unusable or even worse, expose your users to security threats. Hence it is very important to be aware of the common challenges and the best strategies to correctly handle your RAG data.In this article we attempt to exactly address those common issues, ranging from missing context to data security etc.
This is a rapidly evolving field so we highly encourage the reader to keep an eye on recent advances in LLMs and RAG techniques. A good way to that is to subscribe below so you don’t miss our next articles. Also, follow my subscribe to my newsletter: https://heycloud.beehiiv.com/p/attack-vectors-rag-applications. I frequently write about RAG techniques and my own experience building RAG apps.
References
- https://www.anyscale.com/blog/a-comprehensive-guide-for-building-rag-based-llm-applications-part-1
- https://mlnotes.substack.com/p/adaptive-query-routing-in-retrieval
- https://arxiv.org/html/2402.17944v2
- https://www.hopsworks.ai/dictionary/retrieval-augmented-generation-llm
- https://humanloop.com/blog/optimizing-llms
- https://gretel.ai/blog/how-to-improve-rag-model-performance-with-synthetic-data
- https://www.rungalileo.io/blog/optimizing-llm-performance-rag-vs-finetune-vs-both
- https://heycloud.beehiiv.com/p/cheaper-faster-rag-sql-layer