Mastering RAG Evaluation: Strategies for Accurate Assessment

Frequent evaluation of Retrieval Augmented Generation (RAG) systems is vital. Assessments expose RAG components that need improvement, attention, and updates. Maximize the value generated by your system through an in-depth assessment.
RAG systems can improve continually. The possibilities are endless and yes, it can be overwhelming not to know what to optimize first. This is exactly why we bring you a holistic guide to accurate assessments. In this guide, we will be unpacking a lot in this blog. Including metrics, the RAG evaluation framework, evaluation methods, and practical advice. So, sit tight, let’s go!
RAG Evaluations in a Nutshell
A RAG system has two main components: the retriever and the generator. This system uses both to accurately integrate data into the context of the query a user submits. The system then produces insights that fulfill the user query.
- The retriever and the generator must work effectively to produce accurate and relevant insights. If either of these lacks the system will end up hallucinating and producing useless insights.
- These components must be rigorously tested, evaluated, and optimized. Some key metrics include Precision, Recall, and Faithfulness. Assessing these ensures your system produces high-quality and contextually appropriate responses.
- Comprehensive evaluation frameworks and iterative testing processes come in handy here. These evaluations can make the system increasingly useful for its users.
- The findings can help mitigate bias, enhance outcomes’ quality, and expand RAG’s capabilities.
The typical RAG pipeline includes two critical elements:
First, is the retriever component. This locates pertinent information within an extensive data repository. The information is stored in this repository as high-dimensional vectors. The second is the generator. This uses the retrieved content to create responses. A superior RAG pipeline will ensure the accuracy and relevance of the responses. RAG’s ultimate goal is to combine the components together in the best way possible. If they work in harmony, then the pipeline will be able to answer user queries effectively.

Making these components work:
The retriever and the generator must work in tandem. Developers can make this happen by selecting suitable hyperparameters and evaluating performance frequently. So the developers must ensure the retrieval component selects and ranks relevant information.
Companies use RAG systems to narrow down the knowledge gap between large language models and their proprietary data. An effective retriever taps into the exact data required to generate a response. Similarly, an effective generator builds a response that satisfies the context of the query. Ensuring both of these components perform their responsibilities helps deliver successful RAG systems.
Importance of Evaluating RAG Systems
Continuous evaluation of RAG systems is paramount for maintaining high-quality outputs. As RAG systems scale new issues may surface. These can be in the form of overfitting, underfitting, errors, misunderstandings, and hallucinations. All of these happen because the responses produced are not grounded in actual facts or provided context.
This can be a major failure where the accuracy and reliability of the responses are critical. There is an easy way out though. Regular assessments help developers maintain relevant and suitable responses, that fit business needs. If the pipeline produces correct responses user trust and satisfaction grows with it. However, if it fails to do so, the business may lose faith in the system and the investment might tank.
RAG systems must be trained, tested, and evaluated with a focus on the right RAG metrics. This can mitigate risk exposure to the users. It will for sure reduce any grievances caused by faulty responses.
Curating training data with the help of domain experts can significantly improve data relevance. Strategies such as diversifying the training datasets can further solidify the model. The training data should accurately represent the target domain can help with the performance as well. But, all of this starts with the assessment. You can’t fix what you don’t know is broken after all.
What Goes Into A RAG Evaluation?
Assessing RAG systems’ effectiveness necessitates a diverse collection of evaluation metrics. There is a whole variety of retrieval, generation, data, indexing, relevance, and accuracy metrics. Use a combination of metrics that matter the most to you. That will help you build a holistic picture of where your system stands.
Metrics like Precision, Recall, Context, and adherence to factual accuracy are indispensable. These metrics determine a RAG system’s dependability. The retrieved context is also vital in evaluating RAG systems. It directly impacts the accuracy and relevance of the generated outputs.
Utilizing such RAG metrics enables creators to confirm that their system works or it can work. A clear understanding of the limitations of your pipeline is essential to prevent waste of time, reputation, and money.

Context Recall and Precision
The RAG system’s ability to gather all pertinent context from a dataset is quantified by recall. As you’d expect this is an essential performance indicator. You can gauge RAG’s recall abilities by a variety of metrics. Here are some to get you started:
Recall level
Achieving high recall means the system successfully sifts relevant information. It means the indexing works and the system is aware of what to find and where to get it from. This is a key metric to test where omitting critical details can be detrimental.
Recall@k
Recall@k, with ‘k’ denotes the number of top entries reviewed assesses a little more than just recall. It scores how effectively can the system recognize relevant data among top results.
This one is vital when overlooking significant pieces of data could introduce serious errors.
Precision
Conversely, precision measures the relevance of recovered items. This is an evaluation of whether retrieved content is truly applicable to the query at hand. It analyzes if the data found by the retriever is the data that the user actually demanded. If yes, then the precision is high. If not, then it is poor, of course. Combined with recall metrics, precision creates a fuller picture.
Precision@k
This is used where it’s paramount that results are accurate. Precision@k becomes a useful measure for quality assessment over quantity retrieval. This gives a look into just how well the system performs in sourcing materials. It is a check of thoroughness and accuracy, both.
Average Precision
This one is assesses the result arrangement. It reflects on placing important facts above less salient ones within search outputs.

Answer Relevancy and Quality
RAG assessments gauge performance on relevance, quality, and value to the end users. These standards ensure that outputs are precise and significantly relevant to the context. Some other metrics used here to understand answer quality include:
Faithfulness score
The faithfulness score quantifies how accurately the answers reflect found information. This is an analysis of the retrieved contexts and the formulated response. It is vital to check this score where insights can cause heavy consequences for the users.
F1 Score and Average Precision
Metrics like F1 Score and Average Precision quantify result quality. They indicate whether the system aligns with expected quality and norms or not.
Normalized Discounted Cumulative Gain (NDCG)
NDCG is another metric that is used to assess the quality of ranked data retrieval systems. It uniquely checks ranking order. If anything fishy is found the system gets penalized. It is normally used where user trust is fragile or dependent on proper response ranking.
To ensure thorough evaluations under NDCG, graded relevance metrics must be used. These metrics provide a spectrum of relevance from ‘not at all’ to ‘extremely’ relevant. This is a nuanced assessment. So, through this, the NDCG verifies that the RAG system fetches pertinent documents and positions them suitably. While this doesn’t directly look at the LLM output, it does give an indication of the context provided to the LLM.
Evaluating the Retrieval Component

The evaluation of the retrieval component is vital in any RAG system. It underpins performance and identifies problems with generating content.
Looking at the retriever, developers can refine and enhance the system. They can identify problem areas without causing disruption. Finding out the retriever is holding you back will save you from a troubleshooting spree that brings everything to a halt. For this, an evaluation is needed.
Developers can test resource distribution and query complexity to see how well a retrieval performs. Developers can then implement re-ranking methods to improve the relevance of retrieved documents. But, it all depends on your findings. Here are some ways to explore your retriever.
Embedding Model Selection
The accuracy of RAG systems heavily relies on the appropriateness of the embedding model. During brute force indexing, these models are scrutinized to ensure precise retrieval performance. Retrieval effectiveness is judged using metrics such as
- ContextualPrecisionMetric: This finds out if relevant data is prioritized over non-relevant content.
- ContextualRecallMetric: This finds out if pertinent information is correctly identified.
- Zero-shot re-ranking models: This solution can improve the system’s retrieval precision across scenarios and use cases. It can lead to more efficient performance in discerning relevant data for various contexts.
Vector Database Efficiency
Efficient similarity searches in vector databases are super important for RAG systems. They organize vectors to boost the performance of these systems. How? By enabling rapid and exact retrieval of documents according to vector similarities. These databases significantly improve RAG responsiveness and precision. If you find low efficiency in fetching or remembering vectors then the database must be optimized.
Evaluating the Generation Component
In a RAG pipeline, following the retrieval phase, generation comes next. It is the task of the generation element to create impressive outputs. The kind that users love. This evaluation means measuring the caliber of the responses your system generates. It is a test of quality, faith, and context in a nutshell.
Prompt Template Optimization
One way to improve the quality of the response is by tweaking the structure and phrasing your prompt templates. By optimizing your templates you can add specificity. Or more context to what you are asking RAG to produce for you. Doing so enhances the efficacy of the response you get. Imagine asking your system to find a needle in a haystack without specifying the size of the needle. The system will be baffled by the request and throw random needles at you, none of which will be what you wanted it to find in the first place.
So prompt template optimization is essential. The template must contain specifications. You must provide context, clear instructions, and requirements in a format that works for your RAG system. Experimentation with various options can help you determine the optimal approach here.
Measuring Output Quality
Output quality should be assessed. All language learning models offer different quality of output. The quality also depends on the training data, database, and so on. One of the factors that affect the quality of the responses is the temperature setting of an LLM. This setting controls the randomness of responses. Experiment with this setting to see how well your system responds to different queries. The experimentation will give you an estimate of how random or specific can your model behave. Especially if there is a lot of noise in your data, queries, or training.
Comprehensive RAG System Evaluation

Assessing a RAG system’s effectiveness requires a thorough evaluation. You will have to assess the combined performance of the retriever and generator. Based on the results you find you can conclude if your system can achieve business goals and keep up with changing business needs or not.
It is also important that like your system, you also keep your metrics up to date. Check your system frequently and with revised criteria to make sure it evolves, improves, and keeps up with user demands.
End-to-End Performance Metrics
An end-to-end evaluation method takes a holistic view of both components and their effect on RAG’s performance. There are a lot of tools that can help you do that.
Tools like ARES are ideal for environments requiring continuous training and updates. This ensures that the system remains up-to-date and effective.
Platforms like TruLens offer detailed metrics to assess retrievers built for specific domains.
Trade-offs and Optimization
Evaluating a RAG system will give clarity on its capabilities. It does however come with a trade-off. You must consider whether you are ready to improve your performance and system responsiveness. Enhancing the accuracy of responses will result in increased computational demands. This may lead to higher latency and greater expenses.
Similarly, finding out that you need a more scalable storage solution or a new set of algorithms may mean downtime and disruption.
There are trade-offs involved. Thus, it’s essential to strike an optimal balance to satisfy user expectations and the pros of optimization while managing the cons. Inform your decision with the following recommendations:
- Use Mean Reciprocal Rank (MRR) or Average Precision to assess your current response quality.
- Consider investing in expanded memory resources to boost indexing recall capabilities.
- Apply subjective assessment through the GEval metric to review language model outputs. This will ensure a well-rounded perspective on response generation excellence.
Prioritize what you want. Upgrade where necessary, improve where possible, and avoid if the cons are too much as compared to the expected return.
Tools and Frameworks for RAG Evaluation

Numerous tools and frameworks exist to help with the evaluation of RAG systems. These include open-source and proprietary options. Some leading examples of open-source frameworks include TraceLoop, ARES, and RAGAS facilitate evaluations in unique ways. Proprietary solutions like Galileo concentrate on boosting the performance and transparency of the system. Or, if you are looking for something more robust you can use Vectorize.
Using Vectorize for RAG Evaluation
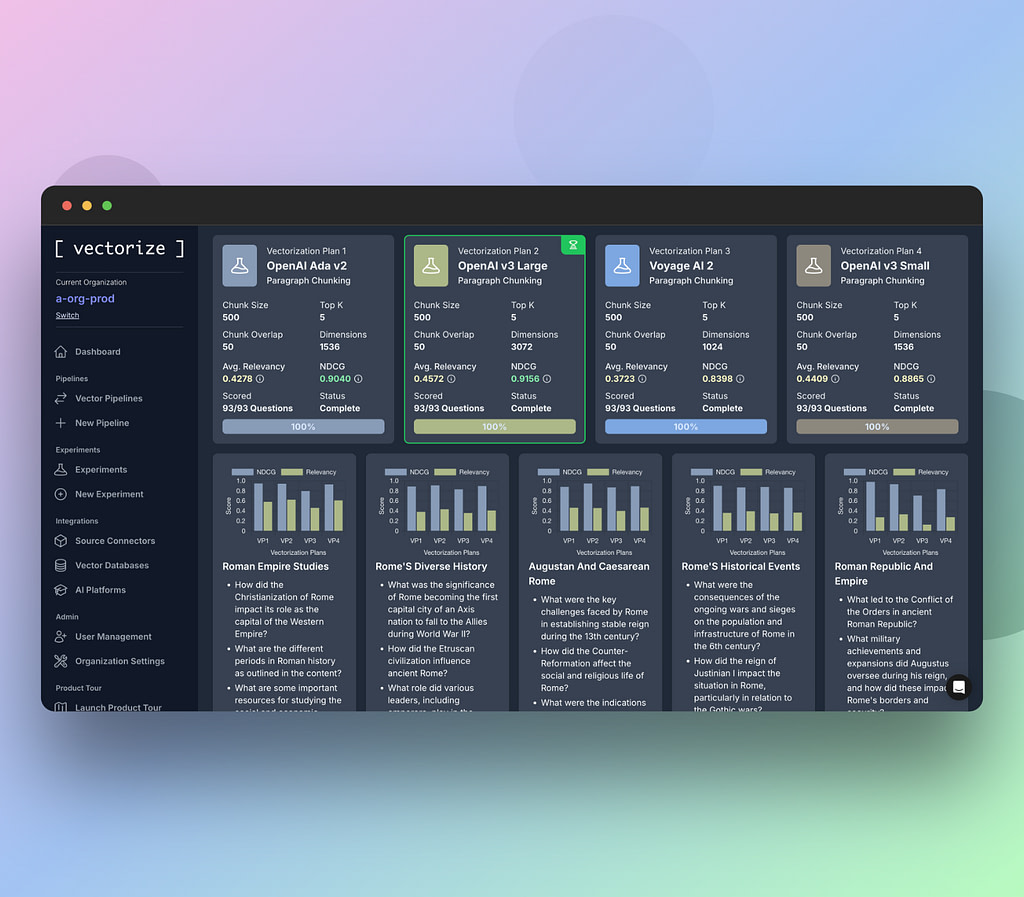
Vectorize offers a robust solution to streamline the performance evaluations of RAG systems. The solution is designed for experimentation and fine-tuning. You can register at no cost. Just by providing a data sample representative of their work on https://platform.vectorize.io, users can gain access to sophisticated capabilities.
The platform’s Experiments utility enables exploration across various embedding models, partitioning methods, and retrieval settings to determine optimal configurations tailored to the user’s unique dataset.
Allows individuals to put into practice full-scale RAG scenarios with vector search indexes that have been created during their experiments. This practical experience grants critical insights into the intricacies of retrieval-augmented generation processes, providing opportunities for ongoing enhancement and precision tuning in real-world applications.
The Hands-on RAG Sandbox Functionality
The Sandbox enables individuals to put into practice full-scale RAG scenarios. Users can test vector search indexes that have been created during experiments.
It gives practical experience and critical insights into the intricacies of RAG processes. Vectorize provides opportunities for ongoing enhancement and precision tuning in real-world applications. Utilizing Vectorize’s offerings facilitates improved outcomes in evaluating and augmenting performance metrics.
Retrieval Metrics and Evaluation Frameworks
Custom evaluation metrics give hyper-focused insights. Using these you can study your system’s efficacy in industry-specific use cases. You can also customize your metrics to see how well your system supports your business objectives. Tailoring your evaluation to how you will use the pipeline will help you pre-empt possible limitations. A preventative approach would be the one where you resolve the found issues before users identify them.
To do this, you need to identify clear goals for your application. Then measure the performance of your system against these goals. Ensuring this evaluation process remains fair and relevant is essential. It is possible that a creator’s bias seeps into the evaluation. A focused evaluation will assess the content with fairness and objectivity.
Involving a diverse team in the audit process enhances the evaluation by. It also helps if you include external members in this process.
This will help you:
- Incorporate various perspectives,
- Run a test group,
- Avoid attachment biases,
- And, ultimately get more comprehensive and balanced outcomes.
You can also use statistical software to facilitate the analysis with audit data visualizations.
Practical Tips for Effective RAG Evaluation
The first and foremost tip is to ensure continuous improvement in system performance. This requires maintaining a consistent process of reassessment and enhancement.
You can start by implementing a solid testing procedure prior to launch. This will empower your team to secure the system’s efficiency and dependability. You can identify issues before the system is handed off to users, leading to proactive improvements.
Iterative Testing and Feedback Loops
Iterative testing is a process that enables ongoing refinements to be made. This may be in response to actual user experiences or results from your test environment. Using iterative testing can boost the performance of RAG pipelines incrementally.
Feedback loops here will demonstrate the system’s effectiveness under real-world conditions. Such feedback has just the insights you need to make your system high-performing.
This cyclical improvement strategy boosts precision and pertinence within the system. It also fosters confidence and satisfaction among users. They feel empowered to work with the creators of the system to identify, improve, and resolve issues.
Final Message
If you take away just one piece of advice from this guide make sure it’s this one — constant refinement and measurement are paramount for preserving the long-term performance of your system.
Frequently Asked Questions
What is Retrieval Augmented Generation (RAG)?
The Retrieval Augmented Generation (RAG) is designed to compute data from large language models. It does so through a vector database. This system is able to generate responses that are enriched with more contextually relevant data.
Why is evaluating RAG systems important?
It is essential to perform evaluations of RAG systems to ensure that issues like hallucinations are minimized. This effort helps in preserving the system’s accuracy and pertinence. Consistent evaluations aid in building confidence in this technological innovation.
What metrics are used to evaluate RAG systems?
To properly assess RAG systems, it is critical to consider essential metrics. This includes:
- Precision, recall, and faithfulness scores,
- Normalized Discounted Cumulative Gain (NDCG),
- F1 Score, and Average Precision among many others.
These metrics provide an accurate picture of RAGs’ performance capabilities.
How can Vectorize help in RAG evaluation?
Vectorize improves the evaluation of RAG by providing automated analysis of retrieved context. These include an assortment of embedding models and segmentation tactics. Clients can also use Vectorize’s RAG Sandbox for an extensive end-to-end examination of relevant context. Such enhancements enable efficient trials and an increase in objectivity.
What are some practical tips for effective RAG evaluation?
Consistent re-assessment and iterative experimentation can ensure the RAG system meets user needs. It also looks at changing needs, and new business objectives and then assesses the system’s abilities against them.
Taking into account user insights can further improve the RAG system. Another tip is for creators to acknowledge and mitigate any data biases by leveraging tailored custom metrics. By adopting these methods, the efficiency of your RAG evaluations will be substantially increased.