Retrieval Augmented Generation: The Easy Path To AI Relevancy

What is Retrieval Augmented Generation (RAG)?
Almost every organization is operating with a growing sense of urgency around generative AI. It poses unprecedented opportunities to amplify worker productivity, engage customers with innovative user experiences, and drive efficiencies and cost savings in the process.

As more and more developers have started building generative AI features into their applications, they often encounter the same sets of initial challenges. These include things like knowledge gaps in the LLM training data. Those gaps could be around subject matter that emerged after the LLM’s training cutoff. It could also be gaps about company-specific information that the LLMs weren’t trained on.
Out of the box, most LLMs have a bad tendency of responding to queries on topics they don’t know about by making up believable, but completely incorrect, responses. We call these incorrect responses hallucinations, and they represent one of the biggest risks to companies aiming to put their trust in generative AI solutions for mission critical applications that are core to their business.
Luckily, the Facebook AI research team encountered these same problems several years ago and invented a technique known as Retrieval-Augmented Generation, or RAG for short, to solve them.
Large Language Models Do Not Know Your Data
While general purpose AI tools, like ChatGPT, are great for everyday tasks like writing an email or a generating some python code examples, they don’t come out of the box ready to support the types of key strategic applications that have the potential to move the needle for your business.

Building AI copilots can allow almost every knowledge worker get their job done in a more efficient manner, but only if that AI assistant provides accurate information. Customer service AI agents have the power to respond to customer queries instantly and offer the potential to increase customer satisfaction, decrease call volumes and make waiting on hold for a customer service rep a thing of the past.
If you ever want to make these types of applications a reality, you must establish a bridge between your preferred foundation model and all of the data sources where your data lives. For a customer service agent, this may include unstructured data sources like a knowledge base where you provide guidebooks that instruct your human agents how to handle difficult customers. It may also include sources of structured data like APIs to retrieve the latest customer account and activity data.

In a nutshell, this is what retrieval augmented generation does. RAG provides a way to take an LLM with no prior knowledge of your data, give it the necessary context as part of your input, and enable the LLM to provide relevant, accurate responses about topics it was never trained on.
Understanding RAG
As the name suggests, retrieval augmented generation generally involves 3 distinct steps: Retrieval, Augmentation, and Generation. In LLM-based applications, you will typically find RAG workflows that look something like this:
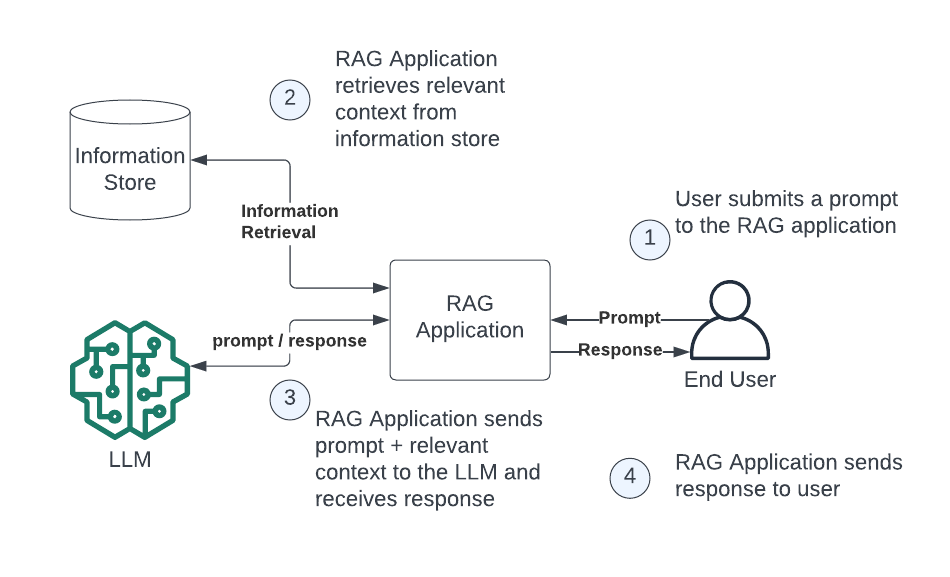
Retrieval occurs by identifying the relevant context and performing lookups, searches, or other techniques to obtain the necessary external knowledge. This could involve scanning a file system, making an API call to external sources, doing a full text search on a knowledge base, executing a SQL query on a relational database, or performing a similarity search on a vector database.
Augmentation can be thought of as the step where you augment your prompt with the specific context that you retrieved in the first step. In effect, this is the mechanism you use to provide the LLM with the necessary context to accurately respond to the instructions provided in the prompt, making it an efficient way to enhance the information retrieval component.
Generation is performed by the LLM just like it would be normally; however, because of the context and instructions provided in your prompt, the LLM can now supplement the knowledge it was trained on with the information that you’ve supplied in the prompt, allowing it to provide accurate responses even about subjects it wasn’t trained on. This process demonstrates how RAG combines traditional language models with innovative retrieval techniques to improve the depth and accuracy of generative AI.
Vector Databases and Semantic Search
A RAG application often relies heavily on a vector database to identify the most helpful context which it can provide to the LLM. A vector database is often useful in this scenario because it is purpose built to enable semantic search capabilities. Rather than approaches that rely on keyword or full text search, semantic search lets you identify the meaning of a piece of text and search for relevant context that has similar meaning.
As a simple example, consider these short sentences: “I love being close to you” and “I hate being apart from you.” As humans, we know these sentences have identical meaning. But from a keyword search perspective, these sentences couldn’t be more different; “love” is the opposite of “hate” and “close” is the opposite of “apart.”

The fact that vector databases enable this type of semantic search is exactly why they’ve seen so much adoption recently and why so many applications that rely on retrieval augmented generation include a vector database in their architecture.
If you imagine applying such a meaning-based search across all the knowledge bases and file systems your organization possesses, you can start to see why generative AI plus vector search are such a powerful combination in the generative AI tech stack.
The role of embedding models
While a vector database provides the ability to store vectors and perform similarity searches on those vectors, you need some way to generate those vectors from your source documents. For this, you’ll need a text embedding model like OpenAI’s text-embedding-v3 or Voyage AI’s voyage-large-2 model. These models accept some text string as their input and produce a vector, that is, an array of floating point numbers, as their output.
You can then rely on techniques like approximate nearest neighbor searches to find the most similar document embeddings that match your input. In this way, you can retrieve the most relevant context in your database that will help your LLM to generate an accurate response to your input prompt.
Applications and Benefits of RAG
By now, you should see why providing up-to-date information to your LLM is so critical to reducing hallucinations and filling in knowledge gaps about topics your LLM wasn’t trained on. As a result, retrieval augmented generation will play a large part in most gen AI application strategies and is particularly well suited for many of the most common use cases and applications that you will find on your project roadmap.
Applications of RAG
Enhanced Chatbots
Retrieval augmented generation is a critical component of almost any type of LLM-powered chatbot. In their most simple form, these applications may offer “chat with your PDF” type capabilities. In cases where your only looking at one or two small documents, you don’t need advanced techniques like embedding models or vector search, you can simply put the entire contents of your document into the prompt.

However, for more complicated examples like an automated AI agent that helps user troubleshoot problems with a SaaS product, you may need to leverage RAG to lookup relevant product documentation, information about how the user has configured the product, clickstream data to see what the user was doing before encountering the problem, and content from support tickets where support engineers helped other customers solve similar problems.
Content Generation Engines
Generative AI has already demonstrated amazing capabilities when it comes to creative content. While the natural language processing capabilities of your large language model are certainly impressive, AI-generated articles, blog posts, and communications often sound overly structured, formal and overly verbose.
Retrieval augmented generation can help to select snippets from similar content that can help the LLM to understand the style and tone you desire and generate content that’s more reflective of these stylistic attributes. For example, let’s say your company makes apparel and the marketing team needs to create product descriptions for next season’s new product offerings. To help create a product description for a new swim suit, you might want to retrieve relevant product descriptions from swimwear of past years and ask the LLM to use this same style and tone to create a product description that’s on brand.
AI Assistants
Many workers are heavily reliant on domain-specific knowledge that’s often entirely absent from the training data used to train popular LLMs. Internal knowledge of business processes, company-specific nomenclature, proprietary data about products and customers are all examples where an LLM would require more detail to accurate respond to a user query.

Retrieval augmented generation offers an ideal approach to perform information retrieval to search the appropriate data source, then include those search results in the LLM prompt to provide context to help the text generator model to provide an accurate, meaningful response. This approach allows your RAG implementation to answer questions even when the relevant information represents new data that was not included in the LLMs original training data.
From legal data, to numerical representations, to medical inquiries, to complex technical support, RAG equips LLMs with the tools necessary to support such knowledge-intensive tasks in all corners of your organization.
Benefits of Retrieval Augmented Generation
Address gaps in training data
One of the biggest benefits of RAG is that it lets you use an LLM to generate content on subjects that were outside the scope of its training data. In effect, this means that simply by providing the right context, you can create LLM applications that cover a wide range of topics and use cases even when the foundational model you’re using knows nothing about the topic at hand.
Reduce hallucinations
As mentioned before, one of the biggest risks for companies using LLMs to power applications, especially customer-facing applications, is that the LLM will respond with incorrect information. This can lead to unhappy customers and in some cases even open a company up to legal liability.

By combining a RAG system architecture with prompt engineering, you can ensure your LLM applications leverage the most relevant external knowledge and data to help your generative ai models provide accurate, hallucination free responses.
Provide up to date context
One of the biggest advantages of retrieval augmented generation over alternative approaches such as fine tuning is that the RAG model inherently ensures that your LLM has the most accurate, up to date information possible when it generates its response. This is because you can always query for the latest information from your external knowledge bases. Techniques like fine tuning cannot offer this same benefit.
Challenges and Future Directions
At this point, you can hopefully see that retrieval augmented generation (RAG) is a very useful method to ensure your chat applications provide an accurate answer, your AI assistants can understand all your company’s acronyms, and your creative content is on brand with the right tone and style. But every architecture has its challenges and RAG is no exception. Let’s take a look now at some of the challenges you’ll face as you start to adopt RAG.

Getting Accurate Context
Everything we’ve looked at in this article hinges in the idea that we can identify the correct context and use it to create an augmented prompt that we can then pass to the LLM to avoid getting back inaccurate responses.
However, this is not as simple as it may sound, especially at scale. To retrieve the most relevant information you’ll often need to create a data pipeline to extract data from the appropriate external knowledge base and push it to your vector store. This process is filled with decision points that can dramatically impact the effectiveness of your information retrieval process. Selecting an extraction implementation to pull content out of files, deciding how to best chunk that content up for later retrieval, and choosing an embedding model to generate your text embeddings are all places where you can inadvertently shoot yourself and your end user in the foot.
One of the key benefits that Vectorize provides is the ability to make a data driven choice around each of these decision points using experimentation to determine which approach will work best for you and your data.
Vector Drift in RAG Applications
Once you have a vectorization strategy that works for you and you have your vector search indexes populated in your vector database, you now must consider how you’re going to keep those indexes up to date. Over time the contents in your various unstructured data sources will change. New policies will get added, product documentation will be updated, customer data will change, and you need to make sure your LLM always has access to the most current, accurate information it needs to produce accurate responses.

This is another area where Vectorize can help eliminate the burden of keeping your context and your source data in sync. While most traditional data engineering solutions don’t handle unstructured data sources very well and don’t have expertise to build accurate, optimized vector indexes, Vectorize does.
Computational and Financial Costs
Building strategic capabilities to support RAG is not without cost. Generating embeddings is a computationally intensive operation. Database providers will often charge using models that scale up with the number of vectors in your vector database. Better performing embedding models often produce bigger vectors which in turn require more compute to calculate and carry higher persistence and query costs to retrieve.

This is another area where leveraging a data driven approach in Vectorize via our free experiments feature can identify the point of diminishing returns for you and your data. Often, we find that smaller open source models are able to provide comparable performance to larger, proprietary models such as OpenAI’s text-embedding-v3-large model.
Future Directions and Potential Improvements in RAG Technology
The entire ecosystem of generative AI is moving unbelievably fast. Advancements in LLMs to support larger and larger context windows, such as Google Gemini’s 10M tokens, has led some people to wonder if RAG is dead. However, even with large context windows, you still must retrieve the relevant context, augment your prompt with that context, then ask the LLM to generate a response based on that context. In other words, RAG becomes more important with large context windows, not less.

Likewise, new techniques are being suggested on a near-daily basis suggesting that in some circumstances you’ll be able to achieve better results. One of the reasons why Vectorize is so attractive for AI engineers and companies building their generative AI strategies is that only through experimentation can you make data driven decisions about which new, emerging techniques will actually deliver improved results, and which simply don’t live up to the hype, at least for your specific data and use case.
Conclusion
Retrieval Augmented Generation (RAG) is an important technique that every application developer, AI engineer and data scientist should be aware of. It offers a battle tested approach to address the limitations of large language models and ensure new data is readily available to your LLM applications in a way that fine tuning can’t.
With RAG, you can tap into the vast knowledge library within your organization, leverage semantic search that will allow your generative AI language models to simulate the sort of deep understanding required to support knowledge-intensive tasks.