Designing Agentic AI Systems, Part 1: Agent Architectures
How do you build an agentic system that works? And how do you spot potential problems during development that can snowball into massive headaches for future you when they go into production?
To answer these questions, you need to break agentic systems into three parts: tools, reasoning, and action. Each layer comes with its own challenges. Mistakes in one layer can ripple through the others, causing failures in unexpected ways. Retrieval functions might pull irrelevant data. Poor reasoning can lead to incomplete or circular workflows. Actions might misfire in production.
An agentic system is only as strong as its weakest link and this guide will show you how to design systems that avoid these pitfalls. The goal: build agents that are reliable, predictable, and resilient when it matters most.
Architecture Overview
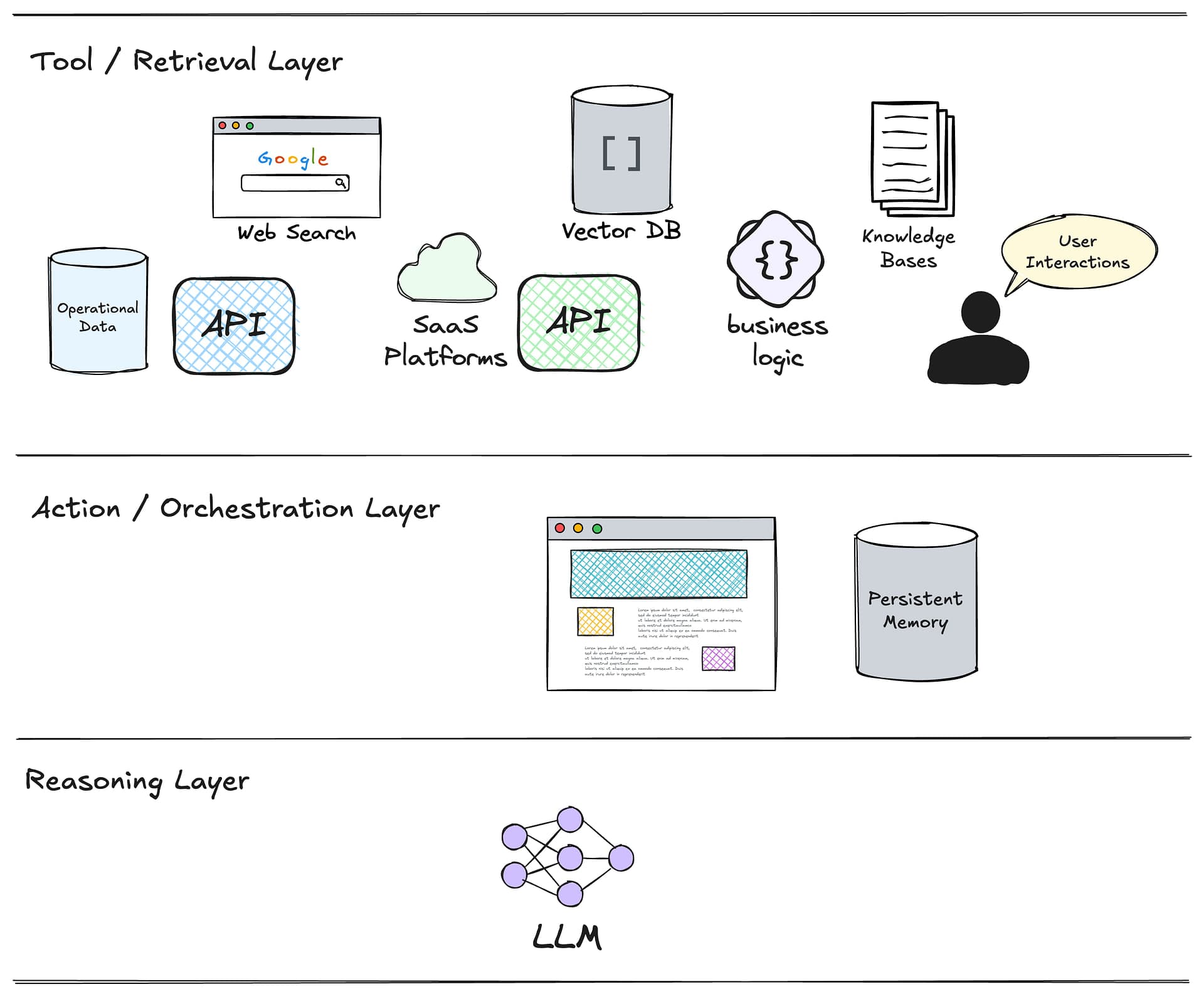
Agentic systems operate across three logical layers: Tool, Reasoning, and Action. Each layer has a specific role in enabling the agent to retrieve, process, and act on information effectively. Understanding how these layers interact is critical to designing systems that are both functional and scalable.
The diagram below illustrates these three layers and the components within them:

- Tool Layer: The foundation of the system. This layer interfaces with external data sources and services, including APIs, vector databases, operational data, knowledge bases, and user interactions. It’s responsible for fetching the raw information the system relies on. Well-designed tools ensure the agent retrieves relevant, high-quality data efficiently.
- Action Layer: Sometimes called the orchestration layer. This is layer is responsible for brokering the interactions between the LLM and the outside world (the tools). It handles interactions with the user, when applicable. It receives instructions from the LLM about which action to take next, performs that action, then provides the result to the LLM in the reasoning layer.
- Reasoning Layer: The core of the system’s intelligence. This layer processes the retrieved information using a large language model (LLM)*. It determines what the agent needs to do next, leveraging context, logic, and predefined goals. Poor reasoning leads to errors like redundant queries or misaligned actions.
* To be precise, reasoning in an agentic system isn’t always performed by an LLM. For example, a Roomba vacuum is an agentic system that doesn’t use an LLM. For the purposes of this article we’re focused on LLM-based agentic systems only.
Agentic Workflow
The action/orchestration layer is the main engine that drives the behavior of the agentic system forward. This layer provides a main processing loop that looks something like this:

The first interaction between the agent application and the LLM defines the overall objective the system is trying to accomplish. This could be anything from generating a real estate listing to writing a blog post to handling an open ended request from a user waiting in a customer support application.
Along with these instructions is a list of functions that the LLM can call. Each function has a name, description, and a JSON schema of the parameters it tables. This simple example of a function is from the OpenAI documentation:
{
"model": "gpt-4o",
"messages": [
{
"role": "user",
"content": "What's the weather like in Boston today?"
}
],
"tools": [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"]
}
},
"required": ["location"]
}
}
}
],
"tool_choice": "auto"
}It’s up to the LLM in the reasoning layer to decide which of the functions should be called next in order to get one step closer to accomplishing the specified goal.
When the LLM responds, it will indicate which function should be called along with the parameters that should be provided to the function.
Depending on the use case and the capabilities of the LLM that are being used in the reasoning layer, the LLM may be able to specify a set of functions which should be called (ideally in parallel) before the next trip through the loop.
It’s a good idea to provide an exit function so the reasoning layer can indicate when it has completed processing and the action layer should exit successfully.
Design Principles
At a surface level, this all appears to be straightforward. However, as the complexity of the tasks grows, so does the list of functions. With more surface area to cover, it’s easier for the reasoning layer to make mistakes. Once you start adding new APIs, specialized sub-agents, and multiple data sources, you’ll find there’s a lot more to manage than just plugging in a prompt and hitting “go.”
In Part 2, we’re going to dive into the idea of modularity. We’ll talk about why decomposing your agentic system into smaller, more focused child agents helps you avoid the pitfalls of a monolithic design.

Each sub-agent can handle its own specialized domain—returns, orders, product information—and that separation gives your parent agent the freedom to dispatch tasks without juggling every possible function in one massive prompt.
In Part 3, we’ll dive deeper into agent-to-agent interactions. Even with great modularization, it can be a real challenge to build uniform interfaces to allow sub-agents to interact in a consistent way. We’ll explore how to define clear, standardized handoffs that let each agent do its job without creating a confusing web of calls and callbacks. You’ll see why having a consistent interface matters and how that helps you troubleshoot or escalate issues when something goes wrong.
In Part 4, we will look at data retrieval and retrieval augmented generation (RAG). Your language model can only do so much without fresh, relevant data, so we’ll discuss how to hook into databases, APIs, and vector stores to give your agent the context it needs. We’ll cover everything from pulling structured data out of existing systems to indexing unstructured content like PDFs, so your system remains fast and accurate as it scales.

Finally, in Part 5 we’ll look at cross-cutting concerns. This includes the critical but easily overlooked aspects of designing any robust agentic system—observability, performance monitoring, error handling, security, governance, and ethics. These elements determine whether your agent can handle real-world traffic, protect user data, and remain resilient as your architecture inevitably evolves.
That’s the roadmap. By the time we’re done, you’ll have the tools and patterns you need to build a reliable, scalable agentic system—one that not only sounds good in theory but actually holds up under the real-world pressures of production environments.