Launch Week, Day 4: Hybrid Retrieval, Metadata, and Real-Time Pipelines Take Flight

Launch Week has been full throttle. We’ve shown you how to build chat apps without glue code, connect your AI tools with Remote MCP, and drop a chat widget into any site with a single snippet.
For our final day, we’re spotlighting the retrieval capabilities that make your agents sharper, faster, and always up to date. Today’s highlights: hybrid retrieval, metadata filtering, and real-time pipelines. 🚀
Hybrid Retrieval and Advanced Filtering
Not every query should rely on embeddings alone. Sometimes you need both the semantic power of vector search and the precision of keywords or filters.
Vectorize offers three retrieval modes (for the built-in database and Elasticsearch):
- Vector Search – pure semantic similarity for conceptual queries
- Text Search – exact keyword matching for specific codes, terms, or phrases
- Hybrid Search – the best of both worlds, combining semantic understanding with keyword precision
And you can go further with advanced filtering:
- Boolean combinations (AND, OR, NOT)
- Range queries (dates, numbers, priorities)
- Nested conditions (e.g. “Q3 2024 docs that are either high-priority OR finance, but not drafts”)
Example: Looking for Q3 revenue guidance? In hybrid mode, you’d search for ‘revenue guidance’ while also filtering for the exact term ‘Q3.’ The result: documents that are both conceptually relevant and textually precise.
📘 Learn more in our Advanced Query docs
Metadata
Every document in Vectorize carries metadata. This is what makes advanced filtering so powerful — giving your queries the structure they need.
Three kinds of metadata you can use:
- System metadata – automatically captured (filename, timestamps, origin)
- User-defined metadata – custom fields you define per document
- Automatic extraction – Iris model + schema editor to pull structured fields from unstructured docs
Define schemas visually, extract fields automatically, and pass metadata filters directly to the retrieval endpoint to get exactly the context your agents need.
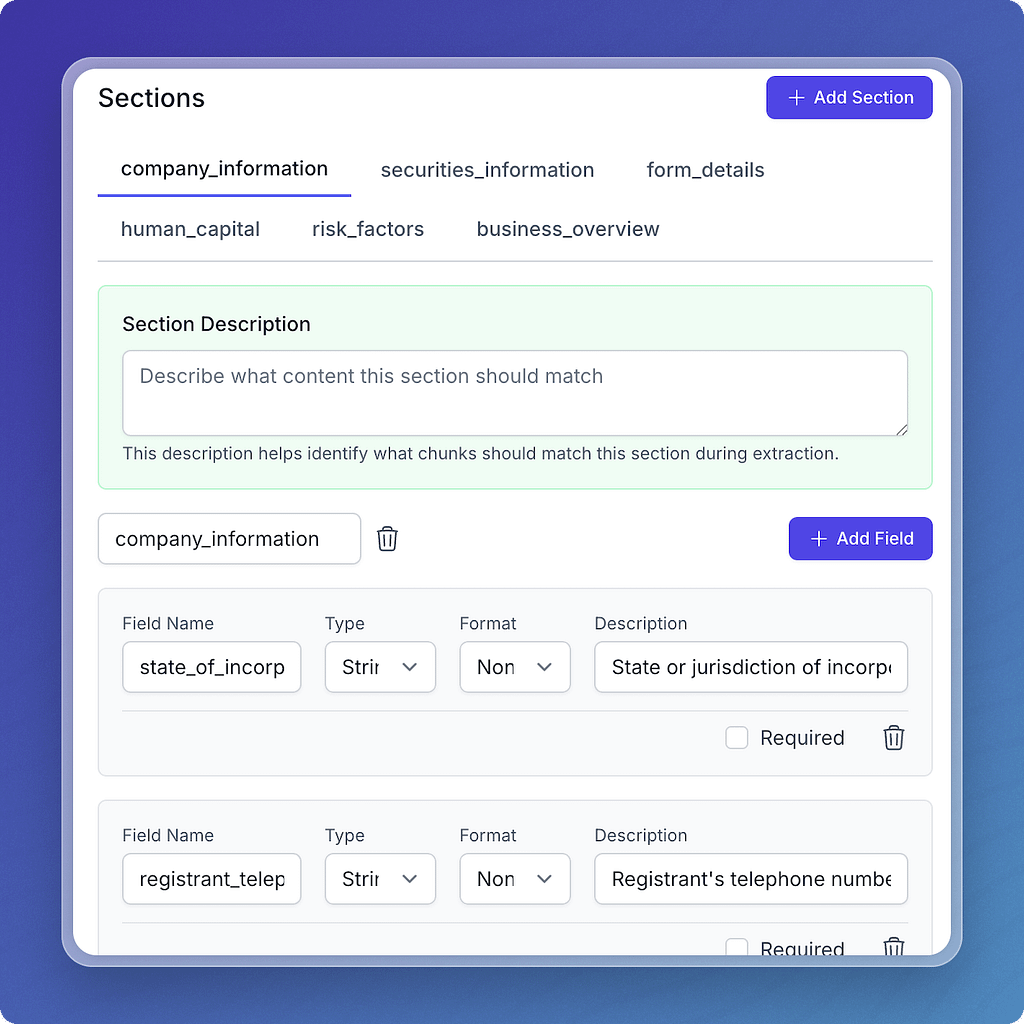
🗂️ Details in Understanding Metadata and the Retrieval Endpoint docs
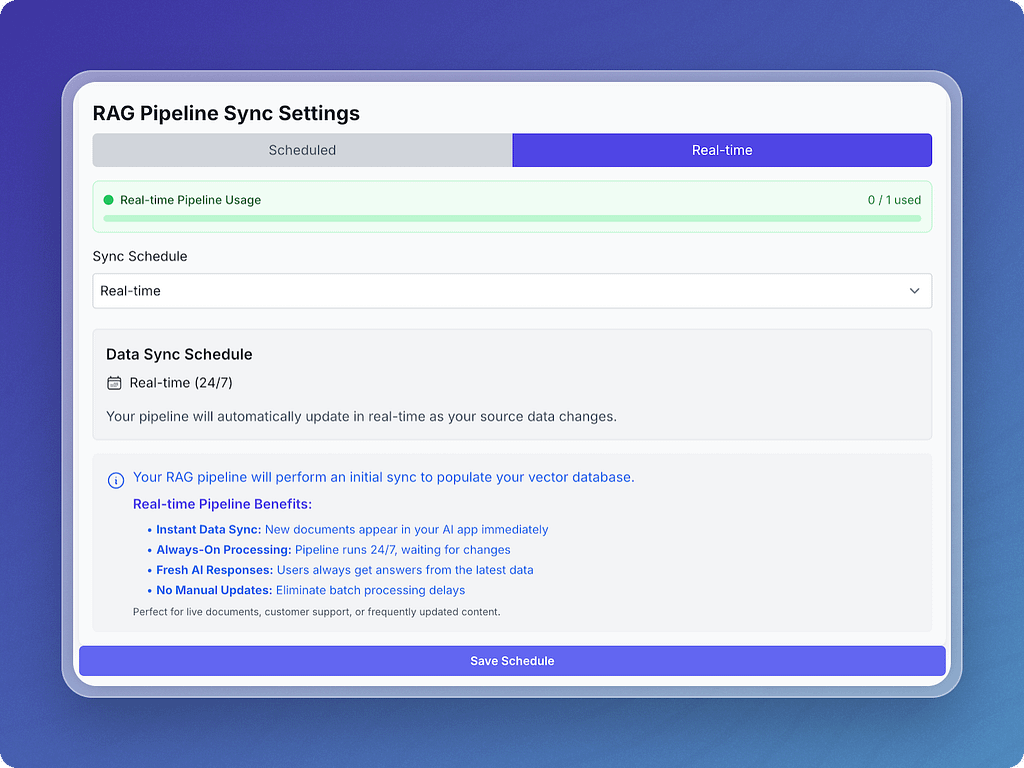
Real-Time Pipelines
Data doesn’t sit still — and now your pipelines don’t either.
With real-time pipelines (available as a premium add-on), Vectorize automatically reprocesses content as soon as it changes — usually within minutes. Works across all supported sources, whether that’s Google Docs, S3, or beyond.
- Edit a document → the new version is ready for retrieval
- Add a file to storage → it’s live in your pipeline without a manual run
No re-deploys. No waiting for schedules. Just fresh data, always.
⚡ See how it works in the Real-Time Pipeline docs
Wrapping Up Launch Week
That’s a wrap on Launch Week! Here’s what we launched:
- Chat Applications — full apps, no glue code
- Remote MCP — connect your pipelines to Claude, Groq Desktop, and more
- Chat Widget — add an agent to any website with a single snippet
- Hybrid Retrieval & Advanced Filtering — semantic search plus precise query logic
- Metadata — structured context with system, custom, and extracted fields
- Real-Time Pipelines — always-fresh data, synced as it changes
Vectorize connects your agents to all the data they need — structured, unstructured, and everything in between. And now, they can do it faster, smarter, and fresher than ever.
✨ Thanks for coming along for the ride.
💡 New users: Try Vectorize free for 7 days — and get 50% off your first month with code CHATTRIAL7.