MemPalace Benchmarks Debunked: What the Scores Mean
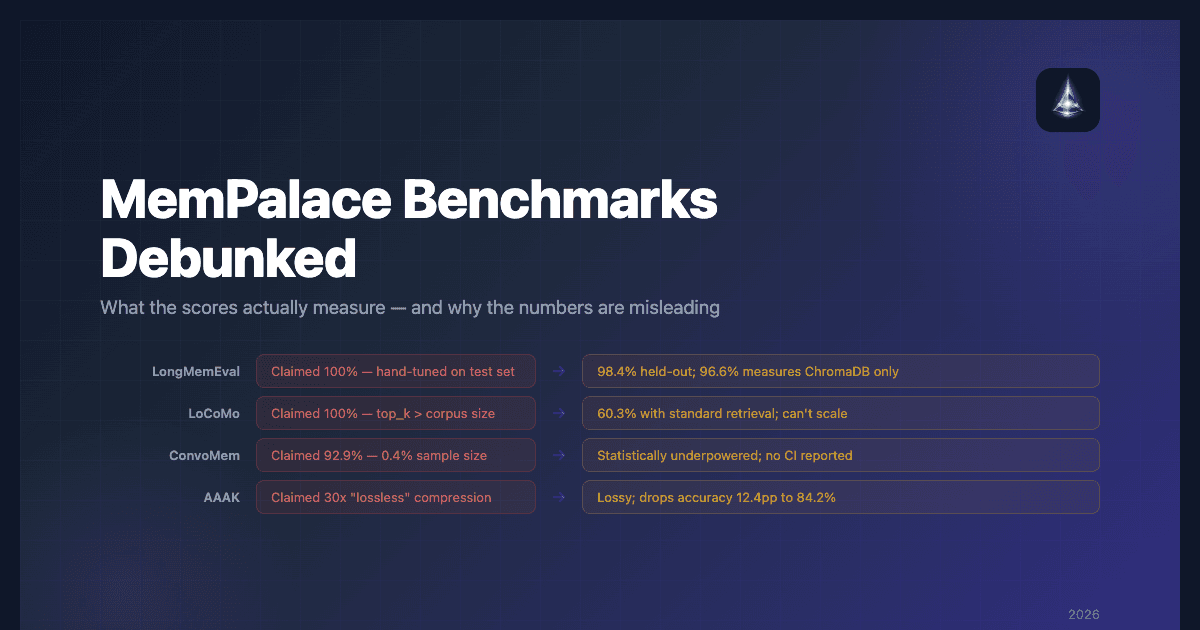
MemPalace's viral adoption was fueled by one claim: "the highest-scoring AI memory system ever benchmarked." The numbers looked extraordinary — 100% on LongMemEval, 100% on LoCoMo, 92.9% on ConvoMem, and 30x lossless compression.
Within days, independent developers and researchers dissected every benchmark. What they found tells a cautionary tale about how AI benchmark scores can obscure more than they reveal.
This article is a technical teardown of MemPalace benchmarks — what was claimed, how the tests were actually run, and what the scores mean for anyone evaluating agent memory systems.
Understanding AI Memory Benchmarks
Before diving into MemPalace's specific scores, it helps to understand what these benchmarks test.
LongMemEval is the standard benchmark for AI memory systems. It evaluates whether a system can retrieve and use information from long conversation histories. Scores can be reported as retrieval recall (did the right document appear in results?) or end-to-end QA accuracy (did the system answer the question correctly?). These are different metrics — retrieval recall is always higher.
LoCoMo tests memory across long conversations with multiple sessions. It evaluates whether systems can find relevant information scattered across many separate interactions.
ConvoMem tests memory for specific conversation details — facts, events, preferences, and other elements mentioned in dialogue.
Each benchmark has standard protocols for how tests should be run. Deviating from those protocols — changing retrieval parameters, fixing specific failing questions, using different metrics — makes scores incomparable to published results from other systems.
LongMemEval: From 100% to 96.6% to "It's Measuring ChromaDB"
MemPalace's LongMemEval journey tells the story in three acts.
Act 1: The Perfect Score (100%)
The initial claim was a perfect 100% on LongMemEval in hybrid mode (with Haiku LLM reranking). This would be the first perfect score ever recorded on the benchmark.
What actually happened: The team ran the benchmark, identified the three specific questions the system got wrong, engineered targeted fixes for those exact questions, and retested on the same set. The held-out score — testing on questions not used for tuning — was 98.4%.
This is overfitting. Training on your test set and reporting the result as a benchmark score violates the basic methodology of any evaluation. The team later acknowledged this, but the 100% claim drove the initial viral wave.
Act 2: The Raw Score (96.6%)
After the 100% claim was challenged, attention shifted to the raw mode score: 96.6% with zero API calls. This uses ChromaDB's default embeddings on uncompressed conversation text.
96.6% is genuinely impressive for a zero-API-cost system. But what is it measuring?
Act 3: It's Measuring ChromaDB
The lhl/agentic-memory analysis — the most detailed independent code review published — reached a clear conclusion: the 96.6% measures ChromaDB's default embedding model performance on raw text. The palace structure is not involved.
The benchmark:
- Does not use wings, rooms, or halls
- Does not use AAAK compression
- Does not use the knowledge graph
- Does not use the memory stack
It proves that ChromaDB's default embeddings work well on the LongMemEval dataset. That's a useful data point about ChromaDB, but it tells you nothing about MemPalace's architecture.
Thin Signal's X thread teardown confirmed that the 96.6% path "uses zero MemPalace-specific logic" — the palace architecture isn't used in the raw benchmark at all, making it "a ChromaDB benchmark, not a MemPalace benchmark."
What Happens When You Turn on Palace Features
An independent reproduction on M2 Ultra (GitHub Issue #39) tested what happens when you actually use MemPalace's differentiating features:
| Configuration | LongMemEval R@5 | Delta |
|---|---|---|
| Raw (ChromaDB only) | 96.6% | — |
| Rooms enabled | 89.4% | -7.2pp |
| AAAK compressed | 84.2% | -12.4pp |
The features that make MemPalace "MemPalace" reduce retrieval accuracy by up to 12.4 percentage points. This is the most important data point in the entire MemPalace benchmarks discussion.
The Metric Mismatch
MemPalace reports recall_any@5 — whether the correct memory appears anywhere in the top 5 retrieval results. Other systems report end-to-end QA accuracy — whether the system actually answers the question correctly.
| System | Metric Reported | Score |
|---|---|---|
| MemPalace | recall_any@5 | 96.6% |
| Hindsight | End-to-end QA | 94.6% |
| Zep | End-to-end QA | 63.8% |
| Mem0 | End-to-end QA | 49.0% |
Retrieval recall is always higher than end-to-end accuracy because finding the right document is easier than answering the question. Placing these numbers side-by-side — as MemPalace's marketing does — inflates MemPalace's relative position against every competitor.
As the Nicholas Rhodes Substack review documented, MemPalace conflates different measurement types — placing retrieval recall alongside end-to-end QA accuracy without labeling the difference.
LoCoMo: The Benchmark That Reveals the Scalability Problem
MemPalace claims 100% on LoCoMo. The methodology doesn't just make this number meaningless — it exposes the deepest flaw in MemPalace's architecture.
How It Was Run
The LoCoMo benchmark was configured with top_k=50 — retrieve the top 50 items from the memory system. The LoCoMo dataset contains a maximum of 19–32 sessions per conversation.
When top_k exceeds the number of items in the corpus, you retrieve everything. The retrieval step — the thing a memory system is supposed to do — is completely bypassed. You're handing the entire conversation history to Claude Sonnet and asking it to answer a question. That's a reading comprehension test for the LLM, not a memory retrieval test.
The Real Number
Without the inflated top_k and without reranking, MemPalace scores 60.3% R@10 on LoCoMo. For context, HiMem reports 83–89% on the same benchmark with standard retrieval parameters.
Why This Matters More Than Any Other Finding
The top_k=50 configuration isn't just a benchmark trick — it's how MemPalace is designed to work. The system stores conversations verbatim and retrieves broadly. When your corpus is 32 sessions, you can dump it all into the LLM's context window and get away with it.
But agent memory systems don't stay at 32 sessions. A year of daily agent conversations generates tens of thousands of sessions and millions of tokens. At that scale, "retrieve everything" is physically impossible — it won't fit in any context window. And MemPalace has no selective retrieval mechanism to fall back on. The palace hierarchy adds metadata filtering, but the core strategy remains: retrieve as much as possible and hope it fits.
This is the question any team evaluating MemPalace should ask: what happens at 10,000 sessions instead of 32?
What Scale-Tested Memory Looks Like
The BEAM benchmark was designed to answer exactly this question. It tests memory systems at up to 10 million tokens — a scale where context-stuffing is impossible.
| Tier | Hindsight | Honcho | LIGHT Baseline | RAG Baseline |
|---|---|---|---|---|
| 100K tokens | 73.4% | 63.0% | — | — |
| 500K tokens | 71.1% | 64.9% | — | — |
| 1M tokens | 73.9% | 63.1% | — | — |
| 10M tokens | 64.1% | 40.6% | 26.6% | 24.9% |
Hindsight scored 64.1% at the 10M tier — 58% ahead of the next-best system. Its accuracy actually improved from 500K to 1M tokens (71.1% → 73.9%) before gracefully degrading at 10M. That's what production retrieval architecture looks like: it works when "retrieve everything" stops being an option.
MemPalace has no published BEAM results because its retrieve-all approach can't operate at that scale.
The "2x Mem0" Claim
MemPalace's marketing states the LoCoMo score is "more than 2x Mem0." But this comparison fails on two levels:
- MemPalace's 100% isn't a retrieval score — it's a reading comprehension score with all context provided
- Mem0's score uses a different metric (end-to-end QA) with standard retrieval parameters
A legitimate comparison would either run Mem0 through the same retrieval-recall harness or run MemPalace through end-to-end QA with the same judge. Neither was done.
ConvoMem: Statistically Underpowered
MemPalace reports 92.9% on ConvoMem, framed as dramatically outperforming Mem0's 49.0%.
The test used 50 items per category (300 total) from a dataset of 75,000+ QA pairs. This is a 0.4% sample.
With 300 data points, even a 10-percentage-point confidence interval would be optimistic. No significance testing was reported. The "more than 2x" comparison drawn from this sample size isn't statistically rigorous enough to publish, let alone use as a marketing headline.
AAAK: The "Lossless" Compression That Loses 12.4 Points
AAAK is MemPalace's custom compression format. The marketing claim: "30x lossless compression" with "zero information loss."
What the Data Shows
| Mode | LongMemEval R@5 | Quality Loss |
|---|---|---|
| Raw (uncompressed) | 96.6% | — |
| AAAK compressed | 84.2% | 12.4 percentage points |
12.4 percentage points of quality loss is not "zero information loss." By definition, if compressed retrieval performs worse, information has been lost.
How the Compression Ratio Was Calculated
The 30x compression claim used len(text)//3 as a token estimator — dividing string length by 3. This is not how tokenization works. Different tokenizers produce different token counts, and string-length division systematically overestimates token counts for English text. The team acknowledged and fixed this after the community flagged it.
What AAAK Actually Is
AAAK is described as a custom encoding format. Code review reveals it's lossy summarization — conversations are compressed into structured shorthand. The decode method performs string splitting, not text reconstruction. There's no way to recover the original text from AAAK-encoded data.
Calling this "lossless" is inaccurate. It's a reasonable compression approach — lossy summarization has legitimate uses — but the marketing misrepresents what it does.
The Broader Pattern
Across all four MemPalace benchmarks, the same pattern emerges:
| Benchmark | Claimed | Methodology Issue | Honest Number |
|---|---|---|---|
| LongMemEval (hybrid) | 100% | Hand-tuned on failing questions | 98.4% (held-out) |
| LongMemEval (raw) | 96.6% | Retrieve-all on small corpus | 89.4% with palace features |
| LoCoMo | 100% | top_k > corpus size bypasses retrieval | 60.3% R@10 |
| BEAM (10M tokens) | Not tested | Retrieve-all can't scale | Hindsight: 64.1% (SOTA) |
| ConvoMem | 92.9% | 300/75,000 sample, no significance testing | Unknown (underpowered) |
| AAAK | 30x lossless | Lossy, miscalculated ratio | 84.2% accuracy with 12.4pp loss |
Each headline number has a methodology issue that inflates the result. Individually, each could be explained. Together, they represent a pattern of benchmarking that favors impressive numbers over honest evaluation.
What Responsible Benchmarking Looks Like
The MemPalace benchmarks controversy highlights what responsible AI memory evaluation should include:
-
Benchmark the actual system — If your architecture has novel features, they should be active during the benchmark. Benchmarking raw ChromaDB and attributing the score to your palace architecture is misleading.
-
Use standard parameters — Setting
top_khigher than your corpus size, or tuning on your test set, produces numbers that aren't comparable to anyone else's published results. -
Report comparable metrics — If competitors report end-to-end QA accuracy, don't compare your retrieval recall against their numbers without clearly labeling the difference.
-
Provide confidence intervals — Small sample benchmarks need statistical context. A 92.9% from 300 samples means something very different than 92.9% from 75,000.
-
Show ablation studies — What does each component contribute? Hindsight's 94.6% includes entity resolution, knowledge graph, and reranking. Remove any one and the score drops — proving each component is load-bearing.
-
Test at scale — Small-corpus benchmarks don't reveal scalability limits. The BEAM benchmark at 10M tokens separates systems that can selectively retrieve from systems that can only dump everything into context.
Hindsight scores 94.6% on LongMemEval through standard methodology and 64.1% on BEAM at 10M tokens — SOTA, 58% ahead of the next system. The full system is engaged (TEMPR retrieval, entity resolution, knowledge graph, cross-encoder reranking), no questions are hand-tuned, and the architecture scales to real-world volumes where retrieve-everything approaches fail.
Conclusion
MemPalace benchmarks tell a story of impressive numbers built on methodology that doesn't withstand scrutiny. The 100% was overfitted. The LoCoMo 100% bypasses retrieval by retrieving everything — an approach that fundamentally can't scale. The ConvoMem score is statistically underpowered. The compression is lossy, not lossless.
The scalability issue is the most consequential finding. MemPalace works when your corpus fits in context. After a year of real agent use — millions of tokens of conversation history — the retrieve-everything approach breaks, and there's no selective retrieval to fall back on.
None of this means MemPalace is useless — local-first memory has real value, and the approach works at small scale. But the benchmark scores that drove 19,500 GitHub stars don't measure what the marketing claims, and they reveal an architecture that hasn't been tested at the volumes where agent memory actually matters.
For teams evaluating agent memory, the lesson is clear: methodology matters more than headline numbers, and scale matters more than either. Ask what's being measured, how the test was run, and what happens at 10 million tokens instead of 32 sessions. When you apply that lens, systems with honest benchmarks, load-bearing architecture, and proven scale — like Hindsight — are the ones you can build on.
Further Reading
- What is MemPalace? — How MemPalace works and what to use instead
- MemPalace alternatives — The 5 best agent memory systems to consider
- What is agent memory? — Foundational concepts behind persistent AI memory
- Best AI agent memory systems compared — Full comparison of all major frameworks
- MemPalace vs Hindsight — Head-to-head comparison on architecture and features
- Agent memory vs RAG — Key architectural differences between memory and retrieval